11.6.1 事前学習モデルロードマップ:BERT、GPT、T5
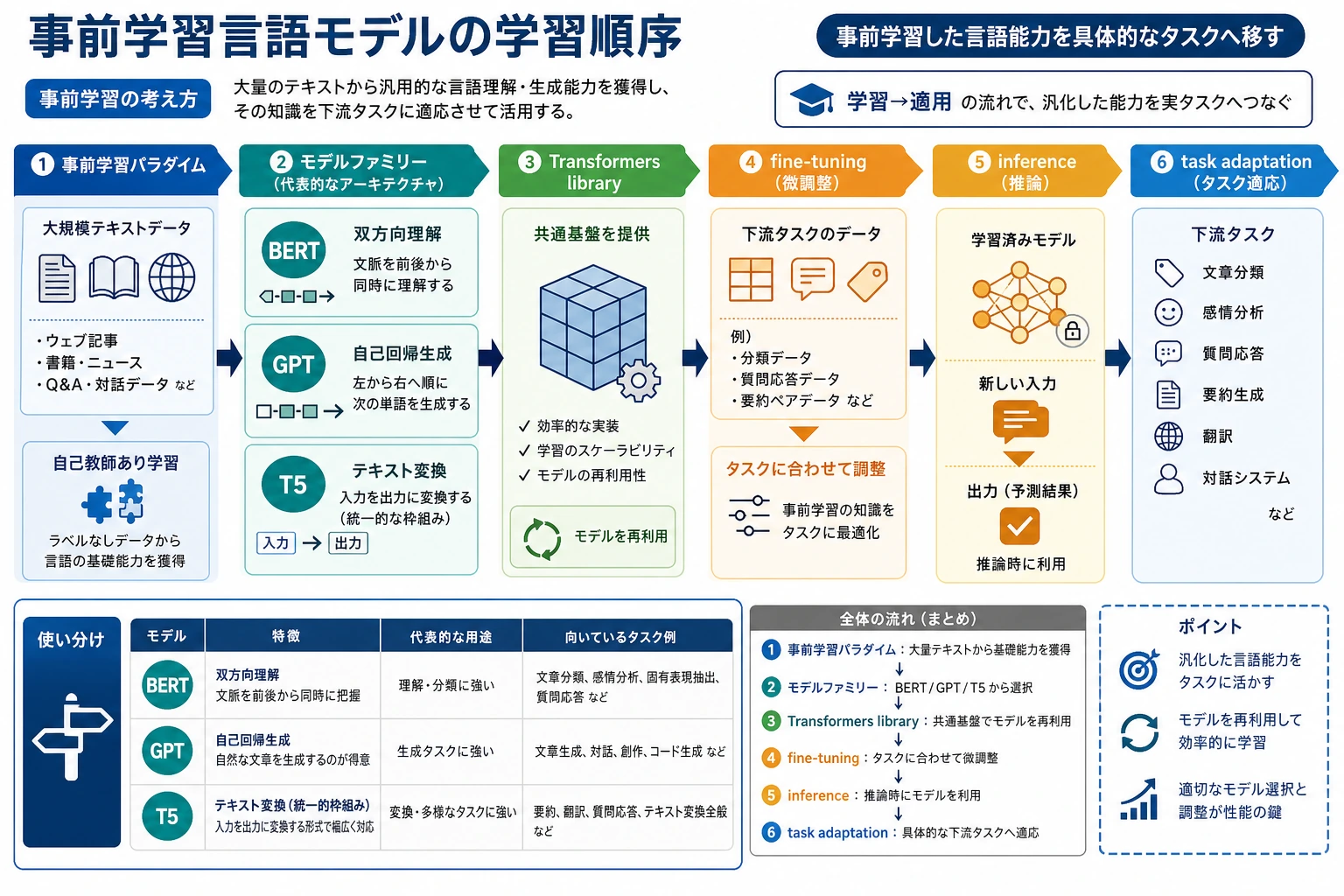
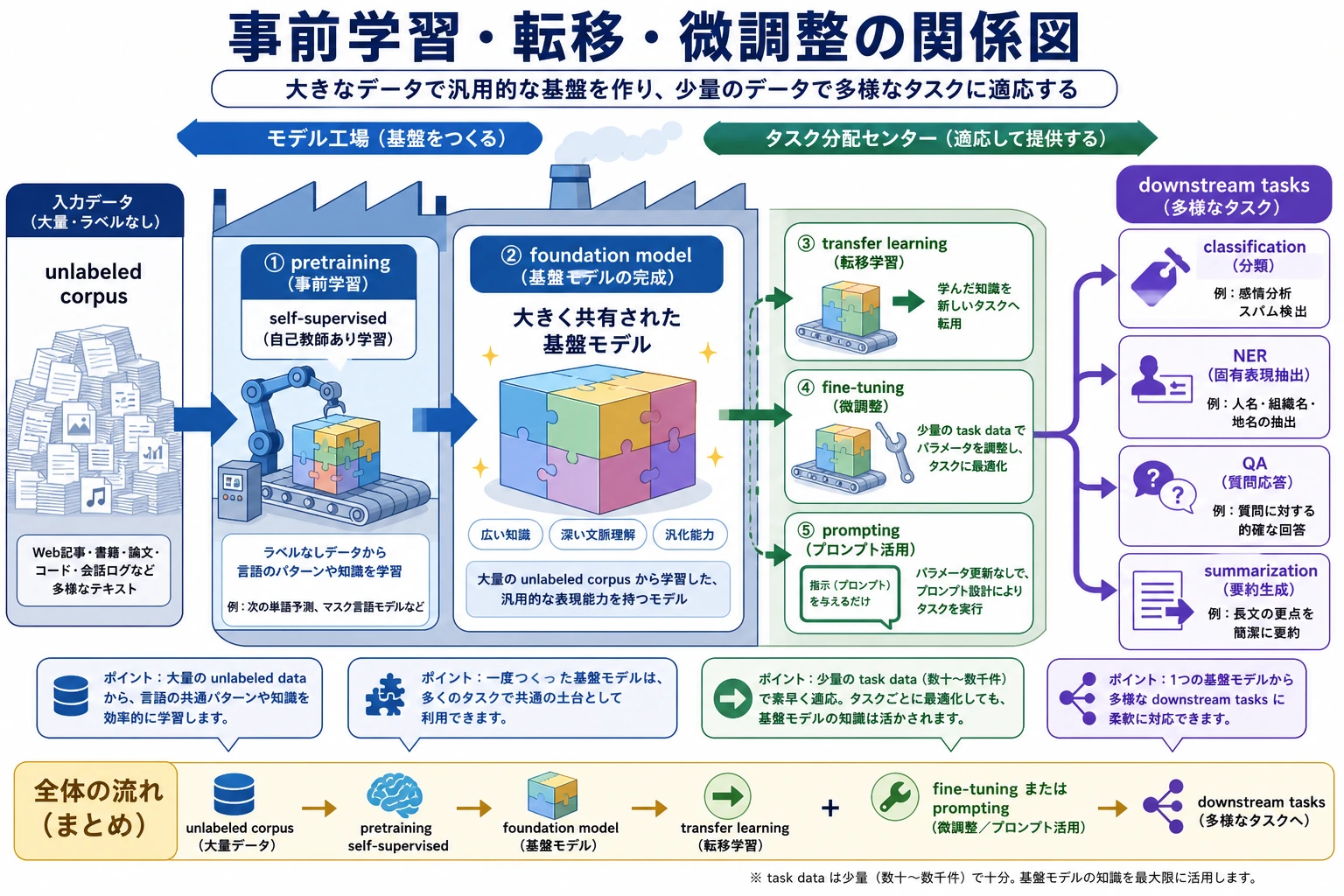
事前学習モデルでは、モデルを毎回ゼロから育てません。大規模テキストで先に言語のパターンを学び、あとから分類、生成、抽出、検索などのタスクに使います。
先に全体像を見る
| モデル群 | 得意な方向 | 代表的な用途 |
|---|---|---|
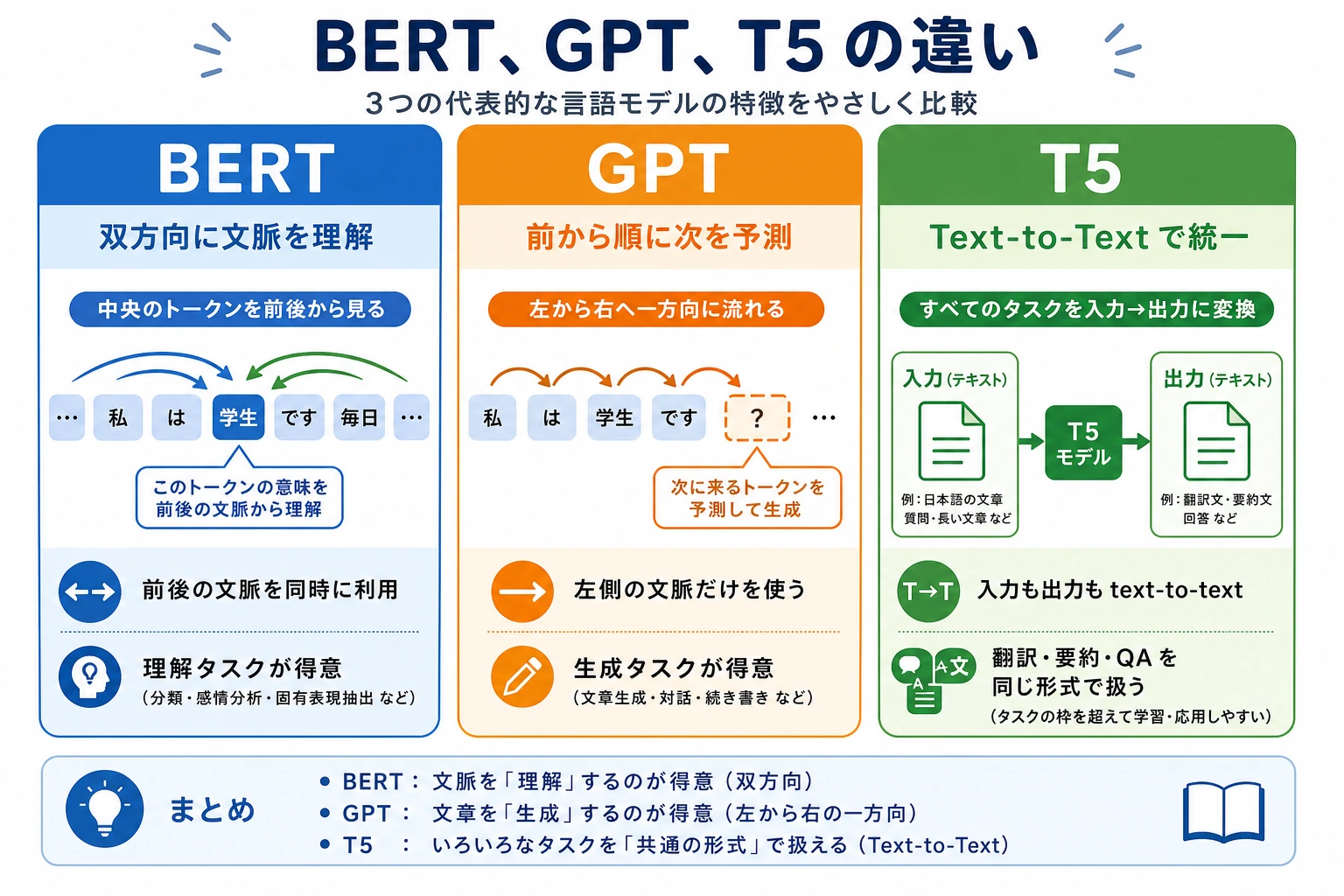
| BERT | 理解 | 分類、抽出、照合 |
| GPT | 生成 | チャット、文章生成、ツール呼び出し |
| T5 | text-to-text | 翻訳、要約、QA、分類の統一 |
タスクからモデルの型を選ぶ
モデル名を丸暗記するより、まず出力形式を見ます。
task = {
"needs_generation": True,
"needs_sentence_label": False,
"needs_text_to_text": True,
}
if task["needs_text_to_text"]:
family = "T5-style text-to-text"
elif task["needs_generation"]:
family = "GPT-style autoregressive"
else:
family = "BERT-style understanding"
print("family:", family)
print("reason:", "match model objective to task output")
期待される出力:
family: T5-style text-to-text
reason: match model objective to task output
操作のコツ:autoregressive は、前の token を見ながら次の token を生成する方式です。GPT 系の生成直感を理解するための重要語です。
transformers を学ぶときの見方
transformers は、tokenizer、model、pipeline などを同じ考え方で扱えるライブラリです。初心者はまず次の 3 点だけ意識します。
| 部品 | 役割 |
|---|---|
| tokenizer | 文字列を token ID に変える |
| model | ID を受け取り、予測や生成を行う |
| pipeline | よくある処理を短いコードで実行する |
通過条件
| チェック | 合格ライン |
|---|---|
| 事前学習 | 大規模テキストで先に学び、下流タスクへ使う流れを説明できる |
| BERT / GPT / T5 | 理解、生成、text-to-text の違いを言える |
| タスク選定 | 出力形式からモデルの型を選べる |
| 次章とのつながり | RAG、Prompt、Agent で tokenizer、embedding、生成が再登場すると説明できる |