11.2.1 表現学習ロードマップ:意味をベクトルで扱う
前章では、テキストを token と ID にしました。この章では一歩進めて、「意味が近い言葉は、ベクトル空間でも近くなる」という考え方を扱います。
先に全体像を見る
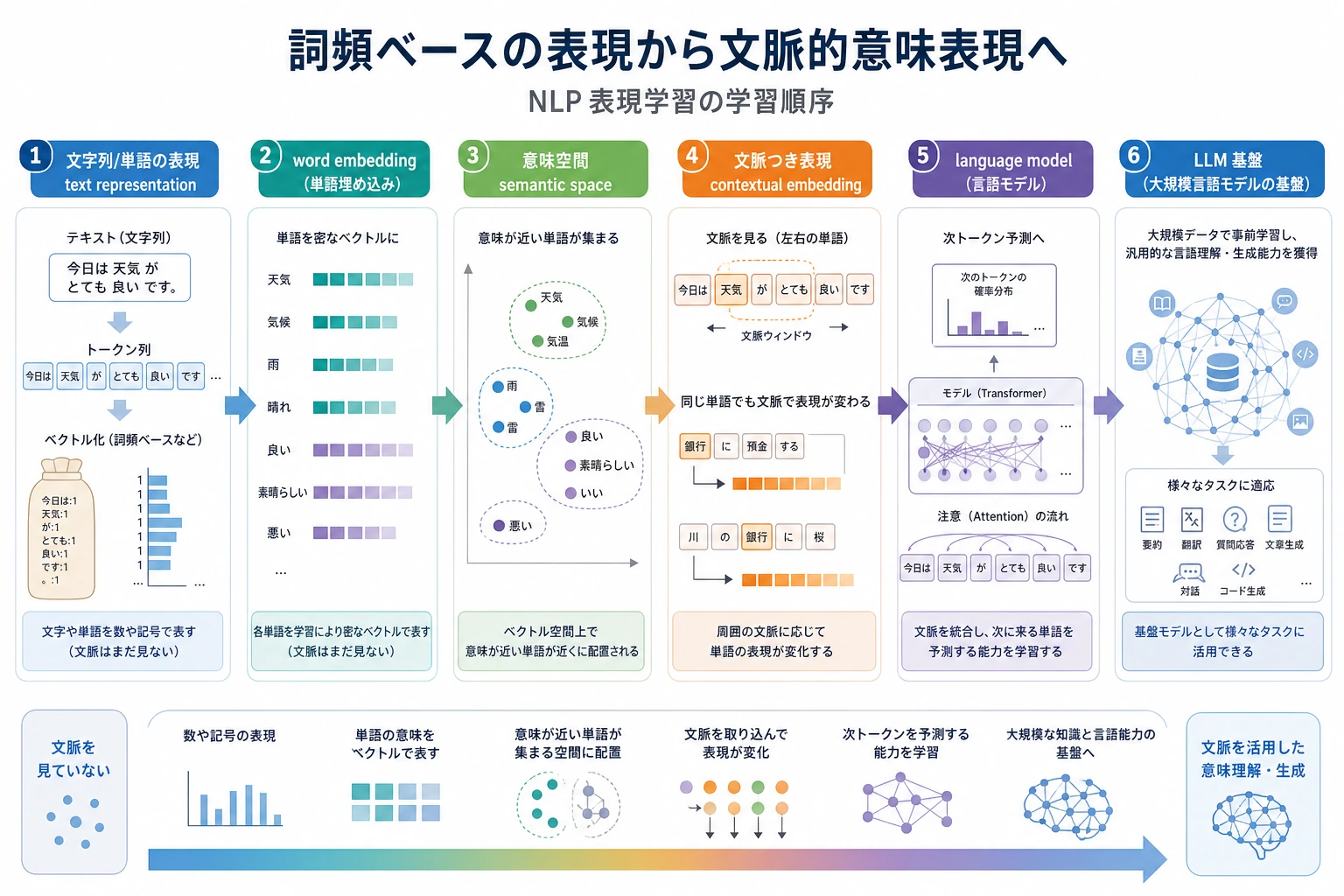
| 順番 | 学ぶこと | 役割 |
|---|---|---|
| 1 | 単語 embedding | 固定の意味ベクトルを作る |
| 2 | 文脈依存 embedding | 文によって意味が変わる単語を扱う |
| 3 | 言語モデル | 文脈全体から表現を学ぶ |
ベクトルの近さを手で確かめる
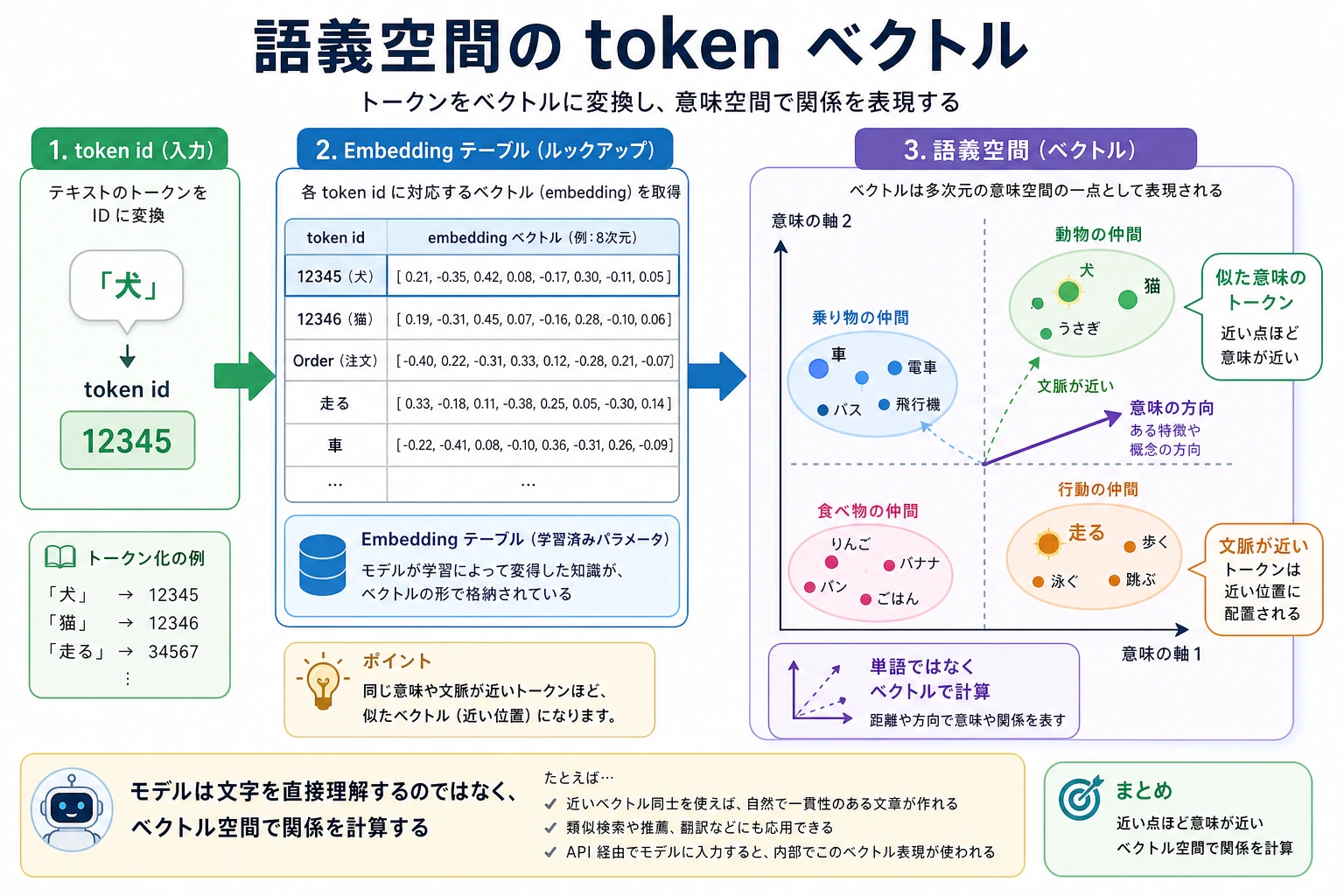
embedding は、token を数字の並びに変えたものです。数字そのものを暗記する必要はありません。大事なのは、似た意味の token が近い場所に置かれることです。
vectors = {
"cat": [1.0, 0.8],
"dog": [0.9, 0.7],
"car": [0.1, 0.2],
}
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
print("cat_dog:", round(dot(vectors["cat"], vectors["dog"]), 2))
print("cat_car:", round(dot(vectors["cat"], vectors["car"]), 2))
期待される出力:
cat_dog: 1.46
cat_car: 0.26
ここでは簡単に内積を使っています。値が大きいほど、今回の小さな例では近い関係だと見なします。本格的な検索では cosine similarity なども使います。
固定表現と文脈依存表現を比べる
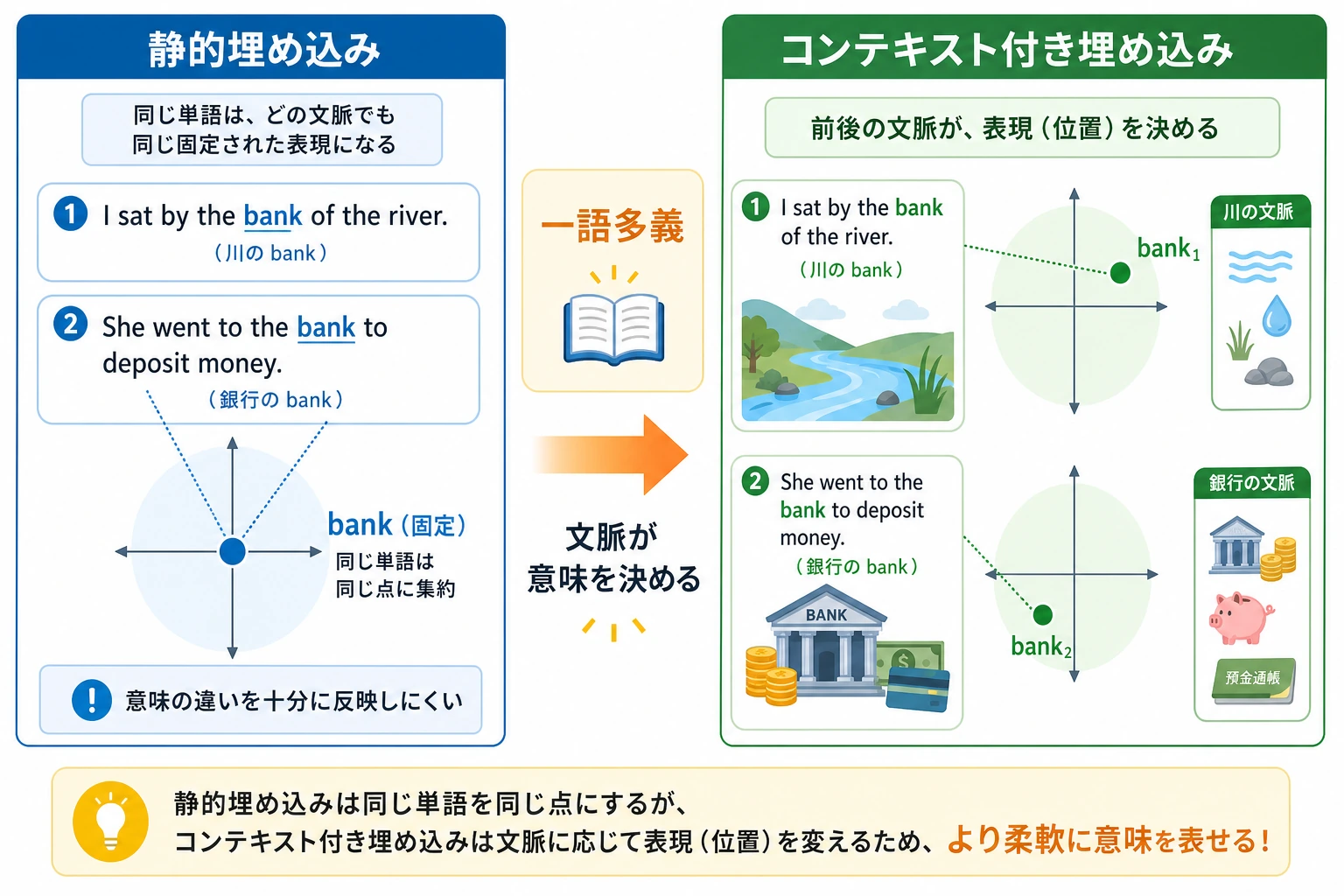
同じ単語でも、文によって意味が変わります。たとえば bank は銀行にも川岸にもなります。固定 embedding は単語ごとに 1 つの表現を持ち、文脈依存 embedding は周囲の文から表現を変えます。
通過条件
| チェック | 合格ライン |
|---|---|
| embedding とは何か | token を意味を含むベクトルに変えるものだと説明できる |
| ID との違い | ID は区別、embedding は近さを扱えると説明できる |
| 文脈依存表現 | 同じ単語でも文によって表現が変わる理由を言える |
| 次章とのつながり | embedding を分類器の入力にできると説明できる |