11.3.1 テキスト分類ロードマップ:テキスト入力、ラベル出力
テキスト分類は、文章を 1 つ受け取り、カテゴリを 1 つ返すタスクです。感情分析、スパム判定、問い合わせ分類、レビュー判定はすべてこの形です。
先に全体像を見る
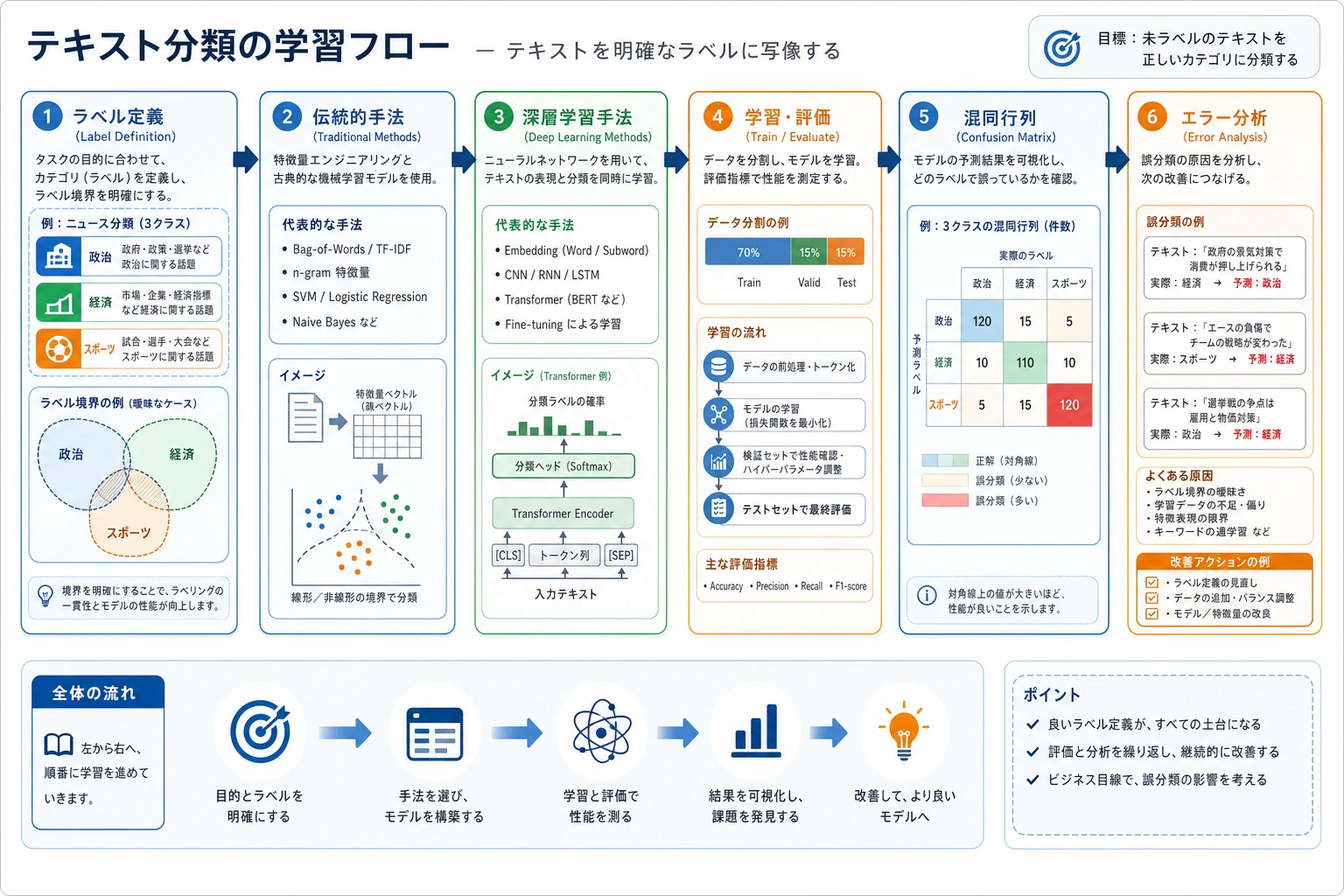
| 順番 | 方法 | 使いどころ |
|---|---|---|
| 1 | ルール baseline | まずタスクの形を確認する |
| 2 | TF-IDF + 分類器 | 小さなデータで強い基準線を作る |
| 3 | embedding + neural model | 意味情報を使って改善する |
まずルール baseline を動かす
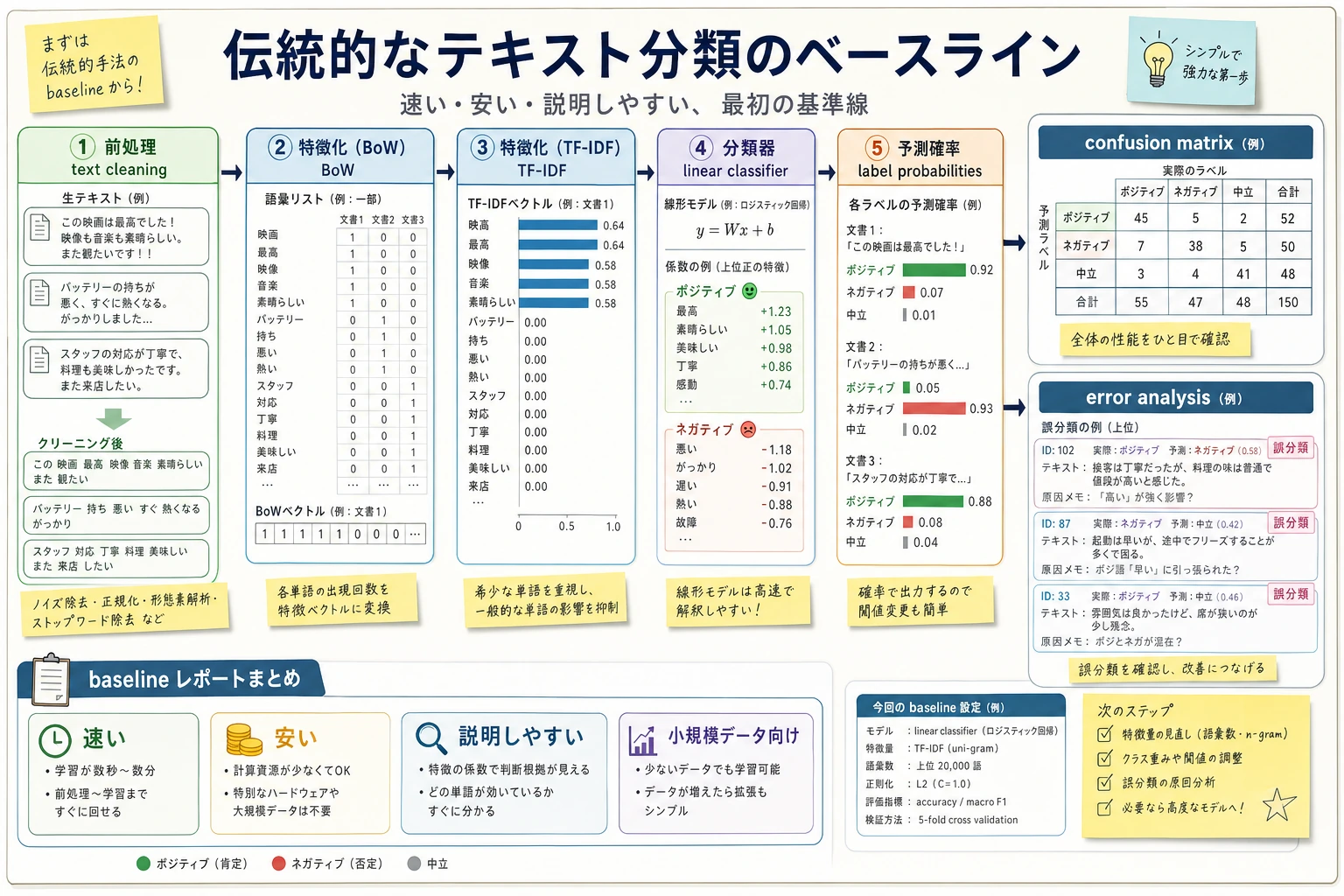
baseline は、後で比べるための最初の基準です。最初から複雑なモデルに進むより、簡単なルールで入力と出力を確認すると失敗に気づきやすくなります。
texts = ["great course and clear examples", "confusing setup error"]
positive_words = {"great", "clear", "good", "useful"}
for text in texts:
score = sum(word in positive_words for word in text.split())
label = "positive" if score > 0 else "needs_review"
print(label, "-", text)
期待される出力:
positive - great course and clear examples
needs_review - confusing setup error
操作のコツ:この baseline は賢くありません。目的は「分類タスクの入出力を固定すること」です。ここでラベル定義が曖昧なら、強いモデルでも安定しません。
embedding 分類へ進む
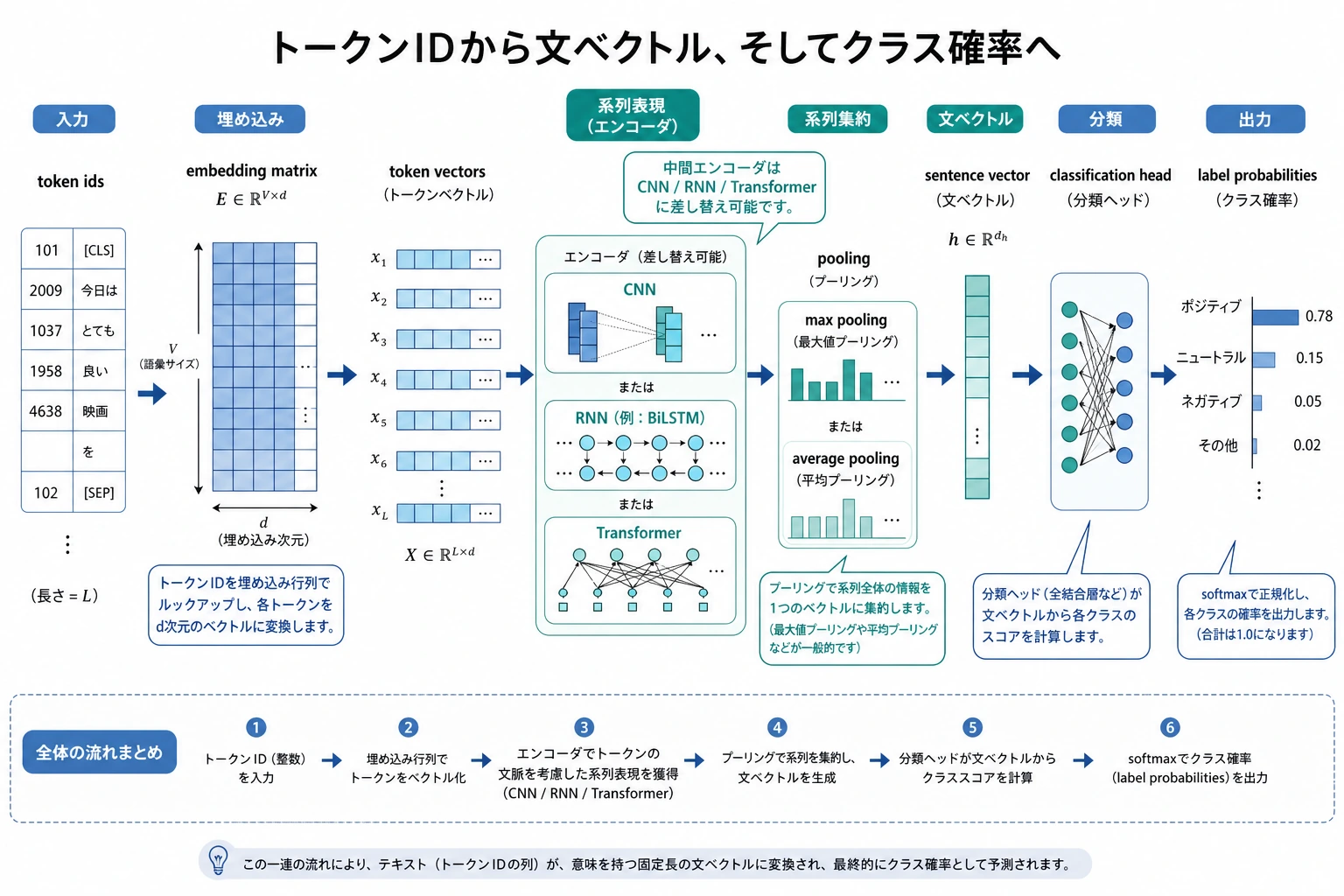
深層学習版では、token を embedding に変え、文全体の表現を作り、最後にラベルを予測します。pooling は複数 token の情報を 1 つの文ベクトルにまとめる操作です。
通過条件
| チェック | 合格ライン |
|---|---|
| 分類タスク | 入力が文章、出力がラベルだと説明できる |
| baseline | 比較用の最小基準だと説明できる |
| TF-IDF | 単語の出現と重要度から特徴量を作る考え方を言える |
| neural 分類 | embedding、pooling、分類ヘッドの流れを説明できる |