11 NLP 専門:LLM 後のテキストタスク
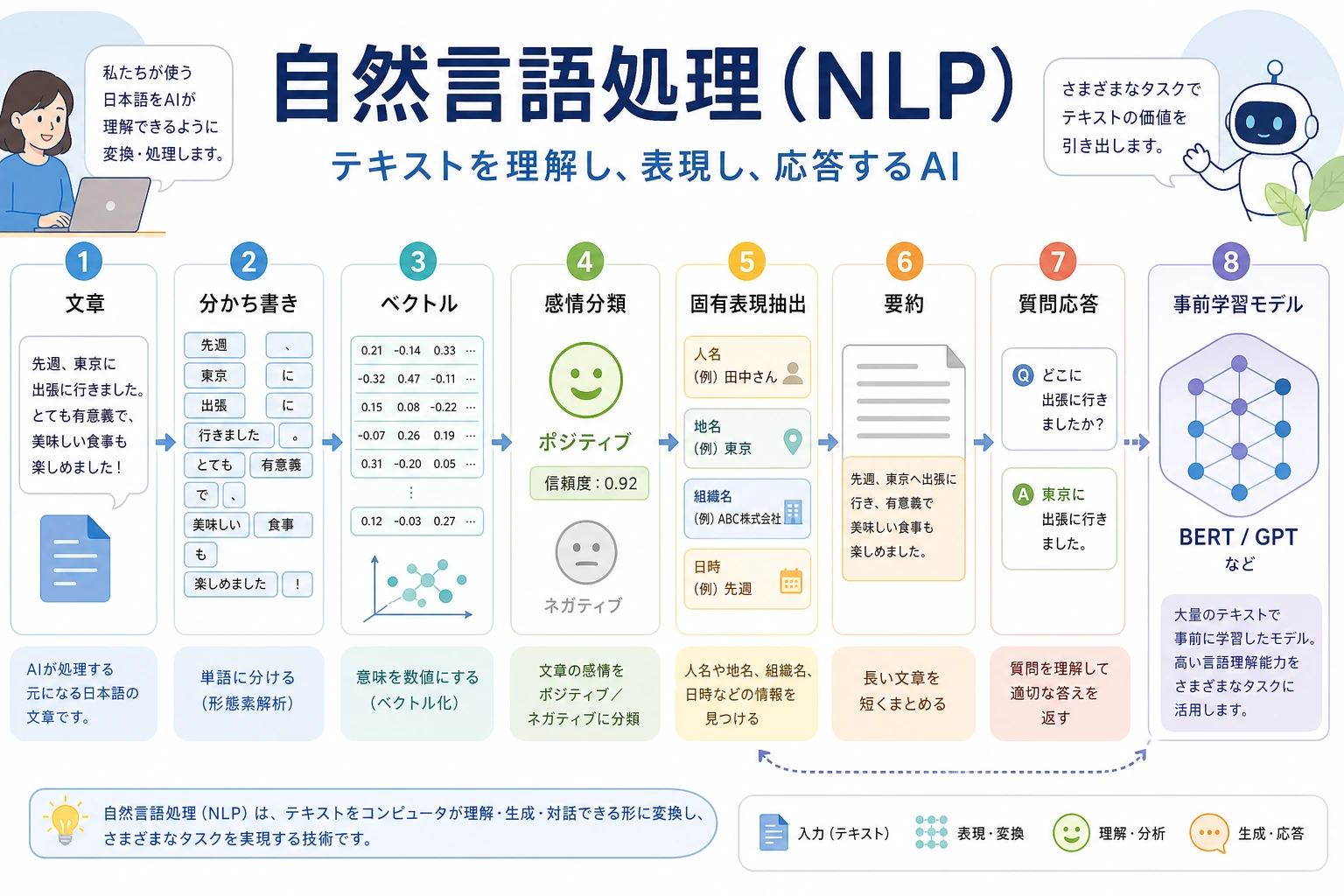
この専門章は、LLM、RAG、Agent のメインルートの後に置きます。第 7 章ですでに最小限の NLP クラッシュコースを扱っています。第 11 章は、実プロダクトでより明確なラベル、安定した抽出、信頼できる評価、または LLM だけでは支えきれないテキストパイプラインが必要になったときに戻ってくる場所です。
本章の問いは、生のテキストが、どうやってモデルが分類・抽出・検索・生成できる対象になるのかです。LLM は多くの NLP 手順を包み込みましたが、Prompt、RAG、Agent memory、検索、評価、情報抽出は今も NLP の考え方に支えられています。
最短の初心者ルートを進むなら、まず第 1-9 章を終えてから、ここに戻ってテキスト系ポートフォリオを作ります。
まずテキストからタスクへの流れを見る

この図を章全体の地図として使います。
| 手順 | 何が起きるか | 実践で確認すること |
|---|---|---|
| 生テキスト | レビュー、ログ、文書、チャット、契約書 | 出典と言語は何か? |
| クリーニング | 大文字小文字、句読点、特殊文字を整える | 重要な意味を消していないか? |
| トークン化 | 単語、サブワード、token に分ける | 専門用語が不自然に分割されていないか? |
| 表現 | BoW、TF-IDF、embedding、文脈ベクトル | タスクとデータ量に合う表現はどれか? |
| タスク出力 | label、entity、summary、answer、検索結果 | 出力 schema は明確か? |
| 評価 | 指標、誤例、事実確認 | 失敗をレビューできるか? |
学習順序とタスク表
まずテキストの流れを理解し、それからモデル群を学びます。
| 手順 | 読む内容 | 手を動かすこと | 残す証拠 |
|---|---|---|---|
| 11.1 | テキスト基礎と前処理 | cleaning、tokenization、normalization を行い例を確認 | cleaning script と before/after |
| 11.2 | Embedding と言語モデル | BoW、TF-IDF、embedding、文脈意味を比較 | 表現方法メモ |
| 11.3 | テキスト分類 | 小さなラベルタスクを作る | ラベルガイド、指標、誤例 |
| 11.4 | 系列ラベリング | NER と token 単位フィールドを理解 | entity 例と境界ケース |
| 11.5 | Seq2Seq と attention | 生成と翻訳の歴史的ルートを理解 | 要約または翻訳メモ |
| 11.6 | 事前学習モデル | BERT、GPT、T5、Transformers の使い方を比較 | モデル選択メモ |
| 11.7 | ステージプロジェクト | 11.7.6 実践:再現可能な NLP ミニパイプラインを作る を動かす | データファイル、指標、抽出出力、失敗レポート |
最初に動かすループ:ラベル、ルール、評価
この依存なしスクリプトはあえて単純です。NLP プロジェクトの核になる習慣、つまりラベルを定義し、固定サンプルで予測し、エラーを保存することを学びます。
ch11_text_eval.py を作成し、Python 3.10 以降で実行してください。
samples = [
{"text": "RAG failed to retrieve the correct document", "expected": "retrieval"},
{"text": "The JSON output is missing a required field", "expected": "format"},
{"text": "The answer sounds fluent but cites no source", "expected": "citation"},
]
rules = {
"retrieval": ["retrieve", "document", "chunk"],
"format": ["json", "field", "schema"],
"citation": ["cite", "source", "evidence"],
}
def predict_label(text: str) -> str:
text = text.lower()
scores = {
label: sum(keyword in text for keyword in keywords)
for label, keywords in rules.items()
}
return max(scores, key=scores.get)
correct = 0
for row in samples:
pred = predict_label(row["text"])
ok = pred == row["expected"]
correct += int(ok)
print(f"pred={pred:<9} expected={row['expected']:<9} ok={ok} text={row['text']}")
print(f"accuracy={correct}/{len(samples)}")
期待される出力:
pred=retrieval expected=retrieval ok=True text=RAG failed to retrieve the correct document
pred=format expected=format ok=True text=The JSON output is missing a required field
pred=citation expected=citation ok=True text=The answer sounds fluent but cites no source
accuracy=3/3
操作メモ: "the document source field is missing" のような紛らわしいサンプルを追加してください。ルールが失敗したら、原因がラベル重複、キーワード不足、タスク定義の曖昧さのどれかを記録します。BERT、GPT、LLM を使うときも同じ考え方です。
出力で NLP タスクを選ぶ

モデルを選ぶ前に、出力を決めます。
| ほしい出力 | タスク | 評価すること |
|---|---|---|
| テキストごとに1カテゴリ | 分類 | accuracy、F1、混同行列 |
| entity や field | 抽出 / 系列ラベリング | precision、recall、field validity |
| 出典に基づく新しいテキスト | 要約 / 生成 | 事実一貫性、網羅性、引用 |
| 文書から質問に答える | QA / 検索 | hit rate、回答品質、出典支援 |
| モデル挙動を比較する | 事前学習モデル実験 | 品質、コスト、遅延、データ要件 |
よくある失敗
- ラベルやフィールドを定義する前に LLM へ進む。
- クリーニングしすぎて意味を消す。
- 分類、抽出、検索、生成の出力を混同する。
- 要約の流暢さだけを見て、事実一貫性を確認しない。
- 指標だけ報告し、誤例と境界ケースを残さない。
クリア確認
この選択章を出る前に、次をできるようにしてください。
- cleaning、tokenization、representation、task output、evaluation を説明できる。
- テキスト評価スクリプトを動かし、紛らわしいサンプルを少なくとも1つ追加できる。
- ラベル定義、field schema、境界ケース、失敗例を書ける。
- 出力タイプで分類、抽出、要約、QA、検索、事前学習モデル比較を選べる。
- 再現可能な NLP ミニパイプラインを動かし、指標と失敗例を残せる。
印刷用チェックリストは 11.0 学習チェックリスト を使ってください。プロジェクトから始めたい場合は 11.7.6 実践:再現可能な NLP ミニパイプラインを作る へ進みます。