11.7.6 実践:再現可能な NLP ミニパイプラインを作る
大きな NLP プロジェクトを選ぶ前に、まずこのミニパイプラインを一度動かしてください。本章の抽象的な概念を、確認できるファイルに変えます。原文、token、TF-IDF 特徴、分類予測、検索 QA、要約、抽出フィールド、指標、失敗例をすべて残します。

このワークショップは Python 標準ライブラリだけを使います。TF-IDF と重心分類は古典的な方法であり、最新のモデルファミリーではありません。ただしここでは意図的に使います。透明で、オフラインで動き、速く、scikit-learn、Transformers、embedding、LLM API に置き換える前の baseline として優れているからです。
何を作るか
スクリプトは nlp_workshop_run/ フォルダを作り、次の構造で成果物を保存します。
nlp_workshop_run/
data/
train_texts.csv
test_texts.csv
notes.jsonl
extraction_eval.jsonl
outputs/
classification_predictions.csv
qa_predictions.jsonl
summary_outputs.md
extraction_predictions.jsonl
reports/
classification_metrics.json
retrieval_qa_metrics.json
extraction_metrics.json
failure_cases.md
README.md
学習目標は満点を取ることではありません。各 NLP 結果を、タスク定義、元テキスト、ラベル、根拠、指標、失敗例までたどれるようにすることです。
Step 0:データの流れを先に見る
コードを実行する前に、上から下へ流れを確認してください。
- 小さなローカルデータセットに原文を書き込む。
tokenize()が文字列を token に分ける。- TF-IDF が token を数値ベクトルに変える。
- 重心分類器が固定ラベルを予測する。
- 検索 QA baseline が最も関連するノートを選んでから回答する。
- 簡単な抽出型要約器が原文の文を選ぶ。
- 正規表現の抽出器が学習ログを構造化フィールドに変える。
- 指標と失敗例をプロジェクト証拠として保存する。
Step 1:フォルダとスクリプトを作る
コースリポジトリの外、または任意の一時フォルダで作業できます。
mkdir nlp-workshop
cd nlp-workshop
python3 -m venv .venv
source .venv/bin/activate
この例は Python の組み込みライブラリだけを使うため、pip install は不要です。次に nlp_workshop.py を作り、下の完全なスクリプトを貼り付けます。
Step 2:完全なスクリプトを実行する
from __future__ import annotations
import csv
import json
import math
import re
import shutil
from collections import Counter, defaultdict
from pathlib import Path
RUN_DIR = Path("nlp_workshop_run")
if RUN_DIR.exists():
shutil.rmtree(RUN_DIR)
DATA_DIR = RUN_DIR / "data"
REPORT_DIR = RUN_DIR / "reports"
OUTPUT_DIR = RUN_DIR / "outputs"
for folder in [DATA_DIR, REPORT_DIR, OUTPUT_DIR]:
folder.mkdir(parents=True, exist_ok=True)
STOPWORDS = {
"a", "an", "and", "are", "as", "at", "be", "before", "by", "can", "do", "for",
"from", "how", "i", "in", "is", "it", "of", "on", "or", "should", "the", "this",
"to", "what", "when", "with", "why", "you", "my", "into", "that", "not", "one",
}
TRAIN_TEXTS = [
("preprocessing", "Clean noisy course comments, lowercase text, remove repeated spaces, and keep useful tokens."),
("preprocessing", "Tokenization splits a raw sentence into words so later features can count them."),
("preprocessing", "Stop words and punctuation should be handled carefully because over cleaning can lose meaning."),
("preprocessing", "Normalize user questions before building a text classifier or retrieval index."),
("preprocessing", "A preprocessing pipeline records raw text, cleaned text, and token lists for review."),
("classification", "Classify each learner question into roadmap, debugging, evaluation, or deployment intent."),
("classification", "Text classification needs label definitions, train and test split, metrics, and error samples."),
("classification", "A sentiment classifier predicts positive, neutral, or negative labels for product reviews."),
("classification", "Confusion matrix shows which labels are mixed up by the classifier."),
("classification", "Accuracy alone is not enough when classes are imbalanced."),
("extraction", "Extract stage, task, metric, and deliverable fields from a study log."),
("extraction", "Named entity recognition marks people, products, places, dates, and organizations."),
("extraction", "Information extraction converts unstructured text into schema fields."),
("extraction", "A contract parser should extract parties, dates, amounts, and obligations."),
("extraction", "Field boundaries must be written down before evaluating extraction quality."),
("summarization", "Summarization compresses a long document while keeping the key facts and conditions."),
("summarization", "Extractive summaries choose important source sentences instead of inventing new facts."),
("summarization", "A good summary is short, faithful to the source, and readable."),
("summarization", "Factual consistency checks whether each summary claim is supported by the original text."),
("summarization", "Meeting notes can be summarized into decisions, risks, and next actions."),
("question_answering", "Question answering needs a knowledge scope, retrieved evidence, an answer, and refusal rules."),
("question_answering", "A QA system should say it does not know when the answer is outside the documents."),
("question_answering", "Retrieval finds the most relevant passage before the answer is written."),
("question_answering", "Citations help users verify where an answer came from."),
("question_answering", "Evaluation for QA checks answer support, retrieval accuracy, and refusal behavior."),
("pretrained_models", "BERT uses masked language modeling and is strong for understanding tasks."),
("pretrained_models", "GPT predicts the next token and is strong for generation tasks."),
("pretrained_models", "T5 turns many NLP tasks into text to text learning."),
("pretrained_models", "The Transformers library provides tokenizers, model loading, pipelines, and fine tuning tools."),
("pretrained_models", "Pretrained models still need clear task boundaries, evaluation sets, and error analysis."),
]
TEST_TEXTS = [
("preprocessing", "My text has emojis, duplicate spaces, and mixed casing before tokenization."),
("preprocessing", "Why did removing every short word damage my model input?"),
("classification", "I need to assign each support ticket to a fixed intent label."),
("classification", "The confusion matrix says roadmap questions are predicted as debugging questions."),
("extraction", "Please pull stage, task, metric, and deliverable from this learning note."),
("extraction", "The resume parser missed the company name and employment date fields."),
("summarization", "Turn this long meeting transcript into decisions and next actions."),
("summarization", "The summary sounds fluent but adds a condition not found in the source."),
("question_answering", "Which passage supports the answer and when should the bot refuse?"),
("question_answering", "My QA demo answers even when the document has no evidence."),
("pretrained_models", "Should I use BERT style understanding or GPT style next token generation?"),
("pretrained_models", "A tokenizer from the Transformers library converts text into model ids."),
]
NOTES = [
{
"id": "preprocess",
"title": "Text preprocessing",
"text": "Text preprocessing keeps a record of raw text, cleaned text, and tokens. Lowercasing, punctuation handling, and stop word choices should be reviewed because too much cleaning can remove useful meaning.",
},
{
"id": "tfidf",
"title": "TF-IDF baseline",
"text": "TF-IDF gives higher weight to words that are frequent in one document but not common in every document. It is a transparent baseline for classification and retrieval before using embeddings or large language models.",
},
{
"id": "classification",
"title": "Text classification",
"text": "Text classification maps a text input to one fixed label. A reliable classifier needs label definitions, train and test split, metrics, a confusion matrix, and error samples.",
},
{
"id": "extraction",
"title": "Information extraction",
"text": "Information extraction turns unstructured text into structured fields such as stage, task, metric, and deliverable. Field boundaries and schema rules must be defined before evaluation.",
},
{
"id": "summarization",
"title": "Summarization",
"text": "Summarization compresses long text into a shorter version. A good summary should preserve key facts, avoid unsupported claims, and remain readable.",
},
{
"id": "qa",
"title": "Question answering",
"text": "A question answering system should retrieve supporting evidence before answering. If the documents do not contain enough evidence, the system should refuse instead of guessing.",
},
{
"id": "pretrained",
"title": "Pretrained models",
"text": "BERT is often used for understanding tasks with masked language modeling, GPT is often used for generation with next token prediction, and T5 unifies tasks as text to text.",
},
]
QA_EVAL = [
("Why should I keep raw text during preprocessing?", "preprocess"),
("What does TF-IDF emphasize in a document?", "tfidf"),
("What evidence should a text classification project keep?", "classification"),
("Which rules matter before information extraction evaluation?", "extraction"),
("How do I check whether a summary is trustworthy?", "summarization"),
("When should a QA system refuse to answer?", "qa"),
("Which note explains optimizer momentum?", None),
]
EXTRACTION_EVAL = [
{
"text": "Stage 11 | Task: text classification | Metric: accuracy | Deliverable: classification_report.md",
"expected": {"stage": "11", "task": "text classification", "metric": "accuracy", "deliverable": "classification_report.md"},
},
{
"text": "Chapter 11 task information extraction should track metric exact match and deliverable extraction_examples.jsonl",
"expected": {"stage": "11", "task": "information extraction", "metric": "exact match", "deliverable": "extraction_examples.jsonl"},
},
{
"text": "For stage 11, build summarization, evaluate factual consistency, and save summary_outputs.md.",
"expected": {"stage": "11", "task": "summarization", "metric": "factual consistency", "deliverable": "summary_outputs.md"},
},
{
"text": "Stage 11 question answering uses retrieval accuracy and writes qa_predictions.jsonl.",
"expected": {"stage": "11", "task": "question answering", "metric": "retrieval accuracy", "deliverable": "qa_predictions.jsonl"},
},
{
"text": "Stage eleven asks for preprocessing notes, token examples, and a README file.",
"expected": {"stage": "11", "task": "preprocessing", "metric": "token examples", "deliverable": "README.md"},
},
]
SUMMARY_SOURCE = """
Natural language processing projects often fail because the task boundary is vague. A team may say they want a smart text assistant, but classification, extraction, summarization, and question answering require different outputs and metrics. A practical baseline should keep raw text, cleaned text, tokens, predictions, metrics, and failure examples. When a model gives a wrong answer, the team should check the label definition, the source evidence, and the evaluation set before changing the model. This habit also prepares the learner for RAG and Agent projects, where retrieval evidence and refusal behavior are part of reliability.
""".strip()
def tokenize(text: str) -> list[str]:
return [token for token in re.findall(r"[a-z0-9]+", text.lower()) if token not in STOPWORDS and len(token) > 1]
def write_csv(path: Path, rows: list[dict[str, str]], fieldnames: list[str]) -> None:
with path.open("w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(rows)
def write_jsonl(path: Path, rows: list[dict]) -> None:
with path.open("w", encoding="utf-8") as f:
for row in rows:
f.write(json.dumps(row, ensure_ascii=False) + "\n")
def fit_idf(texts: list[str]) -> dict[str, float]:
doc_count = len(texts)
df = Counter()
for text in texts:
df.update(set(tokenize(text)))
return {token: math.log((doc_count + 1) / (count + 1)) + 1 for token, count in df.items()}
def vectorize(text: str, idf: dict[str, float]) -> dict[str, float]:
counts = Counter(tokenize(text))
total = sum(counts.values()) or 1
return {token: (count / total) * idf.get(token, 1.0) for token, count in counts.items()}
def cosine(left: dict[str, float], right: dict[str, float]) -> float:
if not left or not right:
return 0.0
overlap = set(left) & set(right)
numerator = sum(left[token] * right[token] for token in overlap)
left_norm = math.sqrt(sum(value * value for value in left.values()))
right_norm = math.sqrt(sum(value * value for value in right.values()))
return numerator / (left_norm * right_norm) if left_norm and right_norm else 0.0
def average_vectors(vectors: list[dict[str, float]]) -> dict[str, float]:
merged = defaultdict(float)
for vector in vectors:
for token, value in vector.items():
merged[token] += value
return {token: value / len(vectors) for token, value in merged.items()}
def build_classifier(train_rows: list[dict[str, str]]) -> tuple[dict[str, float], dict[str, dict[str, float]]]:
idf = fit_idf([row["text"] for row in train_rows])
by_label = defaultdict(list)
for row in train_rows:
by_label[row["label"]].append(vectorize(row["text"], idf))
centroids = {label: average_vectors(vectors) for label, vectors in by_label.items()}
return idf, centroids
def predict_label(text: str, idf: dict[str, float], centroids: dict[str, dict[str, float]]) -> tuple[str, float, float]:
vector = vectorize(text, idf)
scores = sorted(((label, cosine(vector, centroid)) for label, centroid in centroids.items()), key=lambda item: item[1], reverse=True)
best_label, best_score = scores[0]
second_score = scores[1][1] if len(scores) > 1 else 0.0
return best_label, best_score, best_score - second_score
def confusion_matrix(rows: list[dict[str, str]]) -> dict[str, dict[str, int]]:
labels = sorted({row["expected"] for row in rows} | {row["predicted"] for row in rows})
matrix = {label: {other: 0 for other in labels} for label in labels}
for row in rows:
matrix[row["expected"]][row["predicted"]] += 1
return matrix
def retrieve(question: str, notes: list[dict], idf: dict[str, float]) -> tuple[dict | None, float, str]:
q_vec = vectorize(question, idf)
scored = []
for note in notes:
score = cosine(q_vec, vectorize(note["text"] + " " + note["title"], idf))
scored.append((score, note))
score, note = max(scored, key=lambda item: item[0])
if score < 0.08:
return None, score, "I do not know based on the provided notes."
answer = best_sentence(question, note["text"])
return note, score, answer
def best_sentence(question: str, text: str) -> str:
q_tokens = set(tokenize(question))
sentences = [s.strip() for s in re.split(r"(?<=[.!?])\s+", text) if s.strip()]
scored = []
for sentence in sentences:
s_tokens = set(tokenize(sentence))
score = len(q_tokens & s_tokens) / (len(q_tokens) or 1)
scored.append((score, sentence))
return max(scored, key=lambda item: item[0])[1]
def summarize(text: str, sentence_count: int = 2) -> list[str]:
sentences = [s.strip() for s in re.split(r"(?<=[.!?])\s+", text) if s.strip()]
idf = fit_idf(sentences)
scored = []
for idx, sentence in enumerate(sentences):
vec = vectorize(sentence, idf)
score = sum(vec.values()) / (len(tokenize(sentence)) or 1)
scored.append((score, idx, sentence))
chosen = sorted(sorted(scored, reverse=True)[:sentence_count], key=lambda item: item[1])
return [sentence for _, _, sentence in chosen]
def extract_fields(text: str) -> dict[str, str]:
lowered = text.lower()
stage_match = re.search(r"(?:stage|chapter)\s*(\d+)", lowered)
stage = stage_match.group(1) if stage_match else ("11" if "stage eleven" in lowered else "")
tasks = ["text classification", "information extraction", "question answering", "summarization", "preprocessing"]
metrics = ["retrieval accuracy", "factual consistency", "exact match", "accuracy", "token examples"]
deliverable_match = re.search(r"([a-z_]+\.(?:md|jsonl|csv))", lowered)
return {
"stage": stage,
"task": next((task for task in tasks if task in lowered), ""),
"metric": next((metric for metric in metrics if metric in lowered), ""),
"deliverable": deliverable_match.group(1) if deliverable_match else "",
}
def evaluate_extraction(rows: list[dict]) -> tuple[list[dict], int, int]:
predictions = []
correct = 0
total = 0
for row in rows:
predicted = extract_fields(row["text"])
field_scores = {}
for key, expected_value in row["expected"].items():
ok = predicted.get(key, "") == expected_value
field_scores[key] = ok
correct += int(ok)
total += 1
predictions.append({"text": row["text"], "expected": row["expected"], "predicted": predicted, "field_scores": field_scores})
return predictions, correct, total
def main() -> None:
train_rows = [{"label": label, "text": text} for label, text in TRAIN_TEXTS]
test_rows = [{"label": label, "text": text} for label, text in TEST_TEXTS]
write_csv(DATA_DIR / "train_texts.csv", train_rows, ["label", "text"])
write_csv(DATA_DIR / "test_texts.csv", test_rows, ["label", "text"])
write_jsonl(DATA_DIR / "notes.jsonl", NOTES)
write_jsonl(DATA_DIR / "extraction_eval.jsonl", EXTRACTION_EVAL)
idf, centroids = build_classifier(train_rows)
class_predictions = []
failure_cases = []
for row in test_rows:
predicted, score, margin = predict_label(row["text"], idf, centroids)
result = {
"text": row["text"],
"expected": row["label"],
"predicted": predicted,
"score": round(score, 4),
"margin": round(margin, 4),
"correct": predicted == row["label"],
}
class_predictions.append(result)
if not result["correct"] or margin < 0.06:
failure_cases.append({"type": "classification", "reason": "wrong label or low margin", **result})
class_correct = sum(row["correct"] for row in class_predictions)
class_metrics = {
"accuracy": class_correct / len(class_predictions),
"correct": class_correct,
"total": len(class_predictions),
"confusion_matrix": confusion_matrix(class_predictions),
}
write_csv(OUTPUT_DIR / "classification_predictions.csv", class_predictions, ["text", "expected", "predicted", "score", "margin", "correct"])
(REPORT_DIR / "classification_metrics.json").write_text(json.dumps(class_metrics, indent=2), encoding="utf-8")
retrieval_idf = fit_idf([note["title"] + " " + note["text"] for note in NOTES] + [q for q, _ in QA_EVAL])
qa_predictions = []
for question, expected_id in QA_EVAL:
note, score, answer = retrieve(question, NOTES, retrieval_idf)
predicted_id = note["id"] if note else None
correct = predicted_id == expected_id
result = {
"question": question,
"expected_doc_id": expected_id,
"predicted_doc_id": predicted_id,
"score": round(score, 4),
"answer": answer,
"correct": correct,
}
qa_predictions.append(result)
if not correct or (expected_id is not None and score < 0.18):
failure_cases.append({"type": "retrieval_qa", "reason": "wrong document or weak evidence", **result})
qa_correct = sum(row["correct"] for row in qa_predictions)
qa_metrics = {"retrieval_accuracy": qa_correct / len(qa_predictions), "correct": qa_correct, "total": len(qa_predictions)}
write_jsonl(OUTPUT_DIR / "qa_predictions.jsonl", qa_predictions)
(REPORT_DIR / "retrieval_qa_metrics.json").write_text(json.dumps(qa_metrics, indent=2), encoding="utf-8")
summary = summarize(SUMMARY_SOURCE)
summary_text = "# Summary Output\n\n## Source\n\n" + SUMMARY_SOURCE + "\n\n## Extractive Summary\n\n" + "\n".join(f"- {sentence}" for sentence in summary) + "\n"
(OUTPUT_DIR / "summary_outputs.md").write_text(summary_text, encoding="utf-8")
extraction_predictions, extraction_correct, extraction_total = evaluate_extraction(EXTRACTION_EVAL)
extraction_metrics = {
"field_accuracy": extraction_correct / extraction_total,
"correct_fields": extraction_correct,
"total_fields": extraction_total,
}
write_jsonl(OUTPUT_DIR / "extraction_predictions.jsonl", extraction_predictions)
(REPORT_DIR / "extraction_metrics.json").write_text(json.dumps(extraction_metrics, indent=2), encoding="utf-8")
for row in extraction_predictions:
if not all(row["field_scores"].values()):
failure_cases.append({"type": "information_extraction", "reason": "field mismatch", **row})
failure_lines = ["# Failure Cases", ""]
if not failure_cases:
failure_lines.append("No failure cases were triggered. Lower one threshold or add harder samples before using this as a portfolio report.")
for idx, item in enumerate(failure_cases, start=1):
failure_lines.append(f"## Case {idx}: {item['type']}")
failure_lines.append(f"- Reason: {item['reason']}")
if "text" in item:
failure_lines.append(f"- Text: {item['text']}")
if "question" in item:
failure_lines.append(f"- Question: {item['question']}")
failure_lines.append(f"- Evidence: `{json.dumps(item, ensure_ascii=False)}`")
failure_lines.append("- Fix action: inspect task boundary, labels, source evidence, or threshold, then rerun the script.")
failure_lines.append("")
(REPORT_DIR / "failure_cases.md").write_text("\n".join(failure_lines), encoding="utf-8")
readme = f"""# NLP Workshop Run
Run command:
~~~bash
python nlp_workshop.py
~~~
Artifacts:
- data/train_texts.csv and data/test_texts.csv
- outputs/classification_predictions.csv
- outputs/qa_predictions.jsonl
- outputs/summary_outputs.md
- outputs/extraction_predictions.jsonl
- reports/classification_metrics.json
- reports/retrieval_qa_metrics.json
- reports/extraction_metrics.json
- reports/failure_cases.md
Key metrics:
- classification_accuracy: {class_metrics['accuracy']:.3f}
- retrieval_accuracy: {qa_metrics['retrieval_accuracy']:.3f}
- extraction_field_accuracy: {extraction_metrics['field_accuracy']:.3f}
"""
(RUN_DIR / "README.md").write_text(readme, encoding="utf-8")
print("STEP 1: dataset")
print(f"train_texts: {len(train_rows)}")
print(f"test_texts: {len(test_rows)}")
print(f"notes: {len(NOTES)}")
print("")
print("STEP 2: evaluation")
print(f"classification_accuracy: {class_metrics['accuracy']:.3f} ({class_correct}/{len(class_predictions)})")
print(f"retrieval_accuracy: {qa_metrics['retrieval_accuracy']:.3f} ({qa_correct}/{len(qa_predictions)})")
print(f"extraction_field_accuracy: {extraction_metrics['field_accuracy']:.3f} ({extraction_correct}/{extraction_total})")
print(f"failure_cases: {len(failure_cases)}")
print("")
print("STEP 3: files to inspect")
print(f"classification_predictions: {OUTPUT_DIR / 'classification_predictions.csv'}")
print(f"qa_predictions: {OUTPUT_DIR / 'qa_predictions.jsonl'}")
print(f"summary_outputs: {OUTPUT_DIR / 'summary_outputs.md'}")
print(f"failure_report: {REPORT_DIR / 'failure_cases.md'}")
if __name__ == "__main__":
main()
実行します。
python nlp_workshop.py
期待される出力:
STEP 1: dataset
train_texts: 30
test_texts: 12
notes: 7
STEP 2: evaluation
classification_accuracy: 0.917 (11/12)
retrieval_accuracy: 1.000 (7/7)
extraction_field_accuracy: 0.950 (19/20)
failure_cases: 3
STEP 3: files to inspect
classification_predictions: nlp_workshop_run/outputs/classification_predictions.csv
qa_predictions: nlp_workshop_run/outputs/qa_predictions.jsonl
summary_outputs: nlp_workshop_run/outputs/summary_outputs.md
failure_report: nlp_workshop_run/reports/failure_cases.md
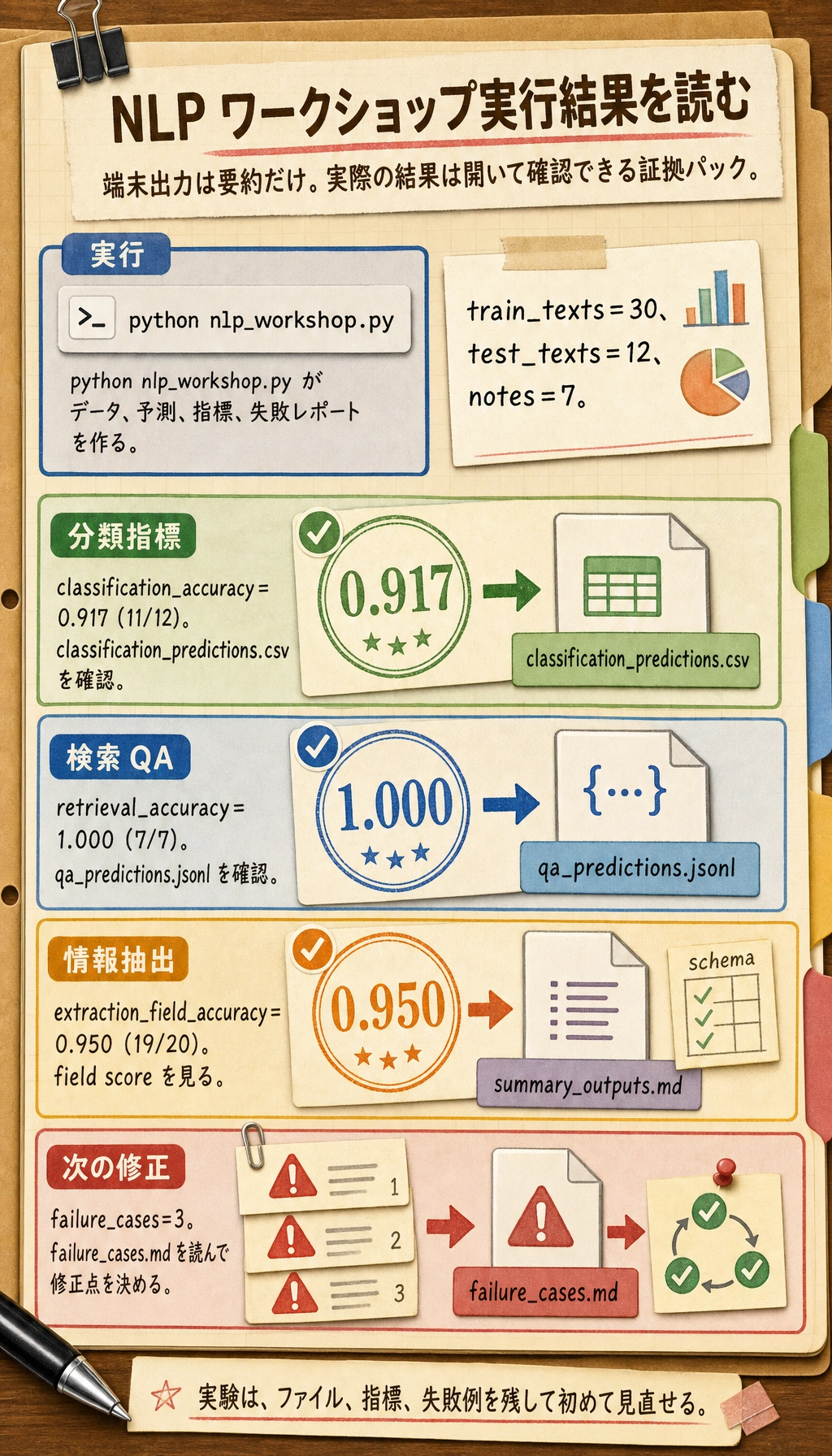
端末出力は、この実行の目次にすぎません。予測ファイル、指標ファイル、失敗レポートを開いてから、この NLP pipeline が本当に使えるか判断します。
Step 3:データファイルを読む
nlp_workshop_run/data/train_texts.csv を開きます。各行には label と text があります。これが教師ありテキスト分類データセットの最小形です。
次に nlp_workshop_run/data/notes.jsonl を開きます。各行は 1 つの知識ノートです。検索 QA は記憶だけで答えるのではなく、まずノートを選び、その中の最も関連する文を答えとして使います。これは後で RAG を作るときにも必要になる証拠を残す習慣です。
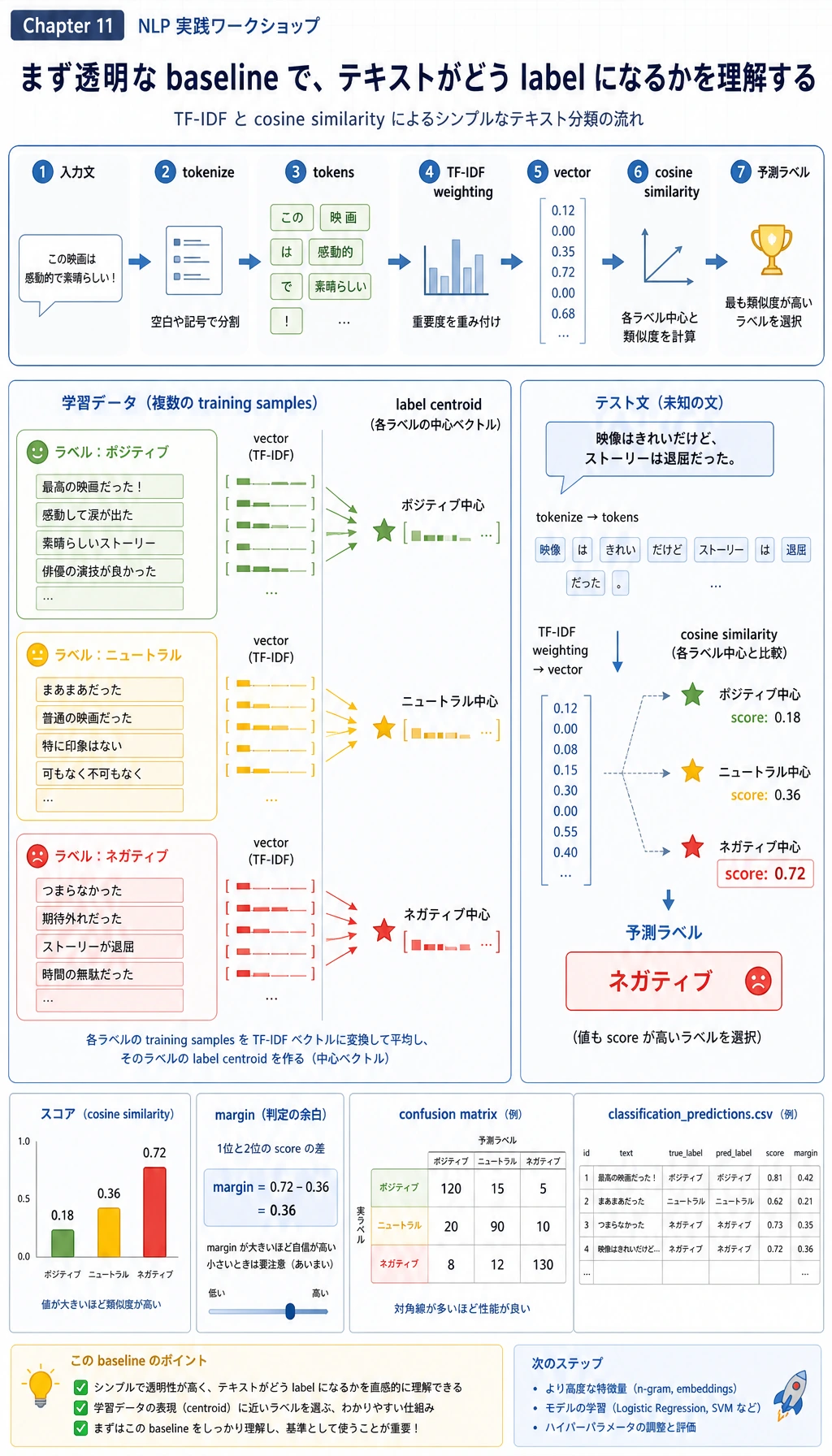
Step 4:Tokenization と TF-IDF を理解する
スクリプト内の tokenize() は、テキストを小文字化し、句読点を除き、簡単な stop words を除き、意味のある token を残します。初心者の失敗はここでよく起きます。
fit_idf() は、各 token が文書集合の中でどれくらい珍しいかを数えます。vectorize() は語頻度に IDF を掛けます。どの文書にも出る語はあまり役に立ちません。あるタスクを見分ける語のほうが価値があります。
実務では、この部分を TfidfVectorizer、embedding、Transformers の tokenizer に置き換えられます。ただし考え方は同じです。モデルが比較できるように、テキストはまず表現に変える必要があります。
Step 5:分類結果を確認する
nlp_workshop_run/outputs/classification_predictions.csv を開きます。
次の列を見てください。
| 列 | 意味 |
|---|---|
expected | 人間が付けたラベル |
predicted | モデルの予測ラベル |
score | 選ばれたラベル重心との類似度 |
margin | 1 位と 2 位のラベルの差 |
correct | 予測が正しいか |
margin が低いときは、ラベルが正しくてもモデルはあまり確信していません。実際の NLP プロジェクトでは、このような低信頼サンプルがラベル定義を改善する材料になります。
Step 6:検索 QA、要約、情報抽出を確認する
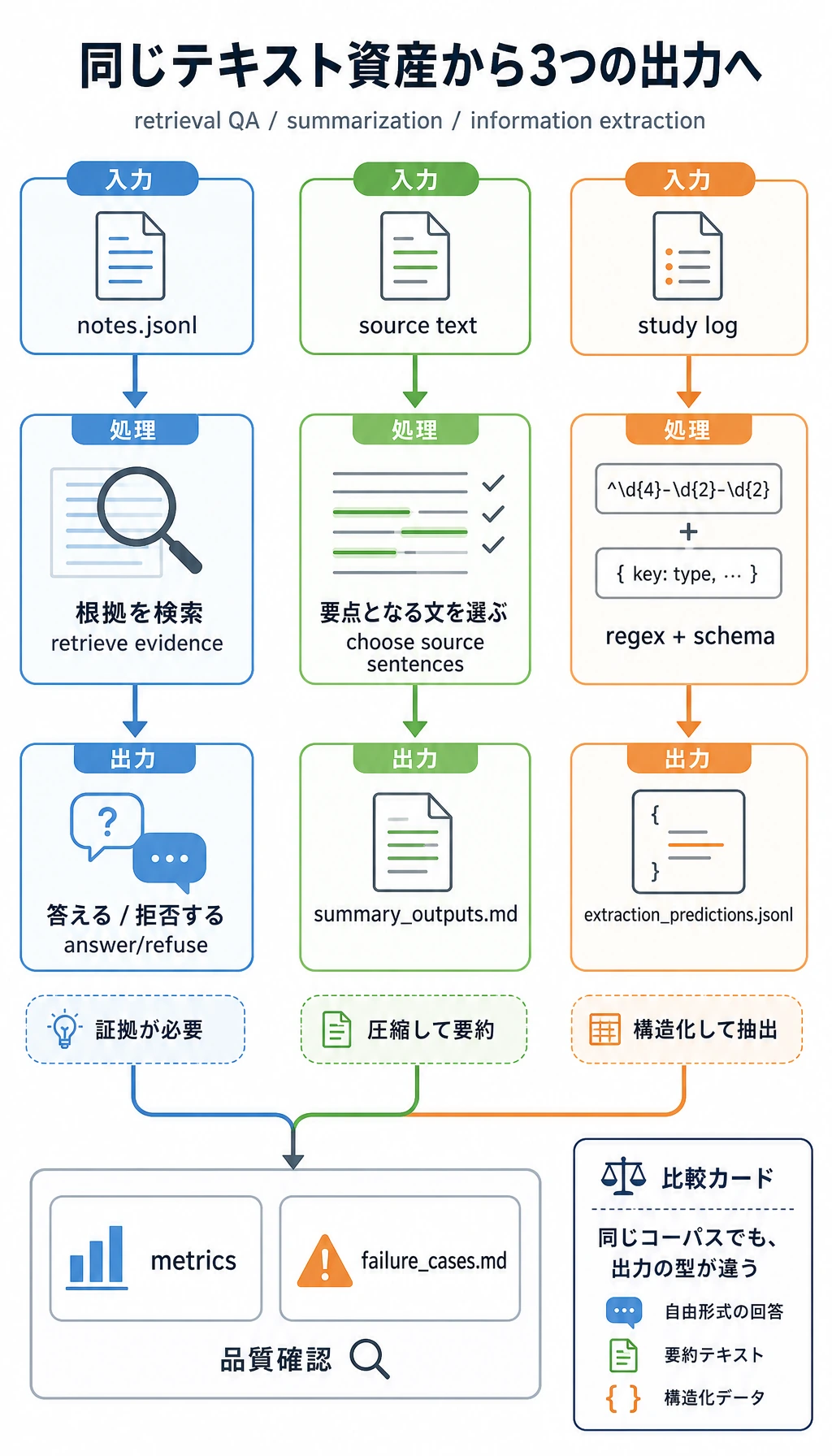
nlp_workshop_run/outputs/qa_predictions.jsonl を開きます。範囲外の質問は次です。
Which note explains optimizer momentum?
ノートには optimizer momentum が含まれていないため、システムは拒否するべきです。信頼できる QA の重要な習慣は、根拠がないときに推測しないことです。
次に nlp_workshop_run/outputs/summary_outputs.md を開きます。ここでは抽出型要約を使っているため、すべての文は元文から来ています。生成型要約より単純ですが、学習段階では評価しやすい方法です。
最後に nlp_workshop_run/outputs/extraction_predictions.jsonl を開き、expected、predicted、field_scores を比較します。情報抽出は単語を見つけるだけではなく、出力を schema に合わせる作業です。
Step 7:指標を読む
3 つの指標ファイルを開きます。
nlp_workshop_run/reports/classification_metrics.json
nlp_workshop_run/reports/retrieval_qa_metrics.json
nlp_workshop_run/reports/extraction_metrics.json
重要なのは、NLP タスクごとに必要な指標が違うことです。
| タスク | 出力 | このワークショップの指標 |
|---|---|---|
| テキスト分類 | 1 つの固定ラベル | Accuracy と confusion matrix |
| 検索 QA | 根拠ノートと回答/拒否 | Retrieval accuracy |
| 要約 | 短くしたテキスト | 元文に支えられているかの手動確認 |
| 情報抽出 | 構造化フィールド | Field accuracy |
Step 8:失敗レポートを読む
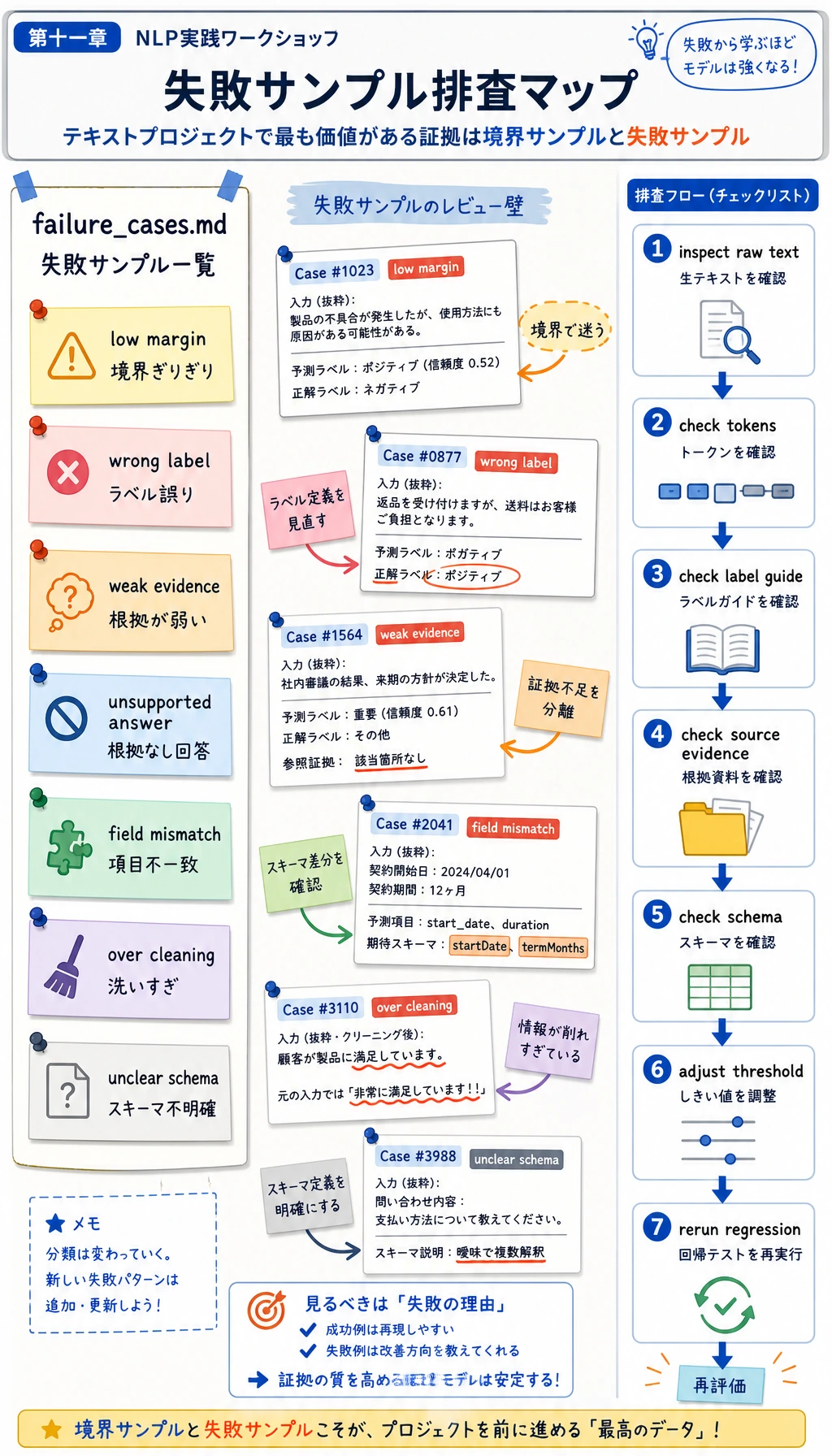
nlp_workshop_run/reports/failure_cases.md を開きます。このファイルはモデルを責めるためではありません。次にどこを直すかを決めるための材料です。
各 case について、次を確認します。
- タスク境界があいまいではないか。
- ラベルや schema があいまいではないか。
- 前処理で有用な証拠を消していないか。
- 元ノートに答えが存在するか。
- しきい値が緩すぎる、または厳しすぎないか。
これらを具体的な証拠で説明できるなら、単に「モデルを動かす」のではなく、NLP エンジニアリングをしている状態です。
Step 9:よくあるエラー
| 症状 | よくある原因 | 修正方向 |
|---|---|---|
| すべて同じラベルになる | 学習データが少ない、またはラベル間の語が似すぎている | サンプルを増やし、ラベル定義を明確にする |
| accuracy は高いのに例を見ると悪い | データセットが簡単すぎる、またはクラスが偏っている | 境界例を追加し、confusion matrix を見る |
| QA が根拠のない質問にも答える | 検索しきい値が低すぎる | しきい値を上げ、拒否テストを残す |
| 抽出でフィールドが抜ける | 正規表現や schema ルールが実テキストに合っていない | フィールド例と境界例を増やす |
| 要約が流暢だが事実と違う | 原文と照合していない | 元文を残し、主張を fact-check する |
Step 10:練習タスク
最初の実行が終わったら、次のアップグレードを試してください。
TRAIN_TEXTSとTEST_TEXTSに新しいラベルを 2 つ追加し、confusion matrix の変化を見る。QA_EVALにより難しい範囲外質問を追加し、システムが拒否するか確認する。EXTRACTION_EVALにriskフィールドを追加し、extract_fields()を更新する。- 重心分類器を scikit-learn の
TfidfVectorizerとLogisticRegressionに置き換える。 - ノート検索を embedding や LLM ベースの RAG に置き換える。ただし出力ファイルと指標は同じ形で残す。
完了基準
このワークショップを終えたら、次を説明できるようになってください。
- なぜ原文をクリーニングし、tokenize する必要があるのか。
- なぜ TF-IDF が透明な baseline として使いやすいのか。
- 分類、検索 QA、要約、抽出の出力がなぜ違うのか。
- どのファイルがパイプライン実行の証拠になるのか。
- 失敗レポートが次の改善にどうつながるのか。
これらの成果物を README に残せれば、第 11 章の実践 baseline ができています。後の RAG、LLM アプリ、Agent memory にもつながる土台になります。