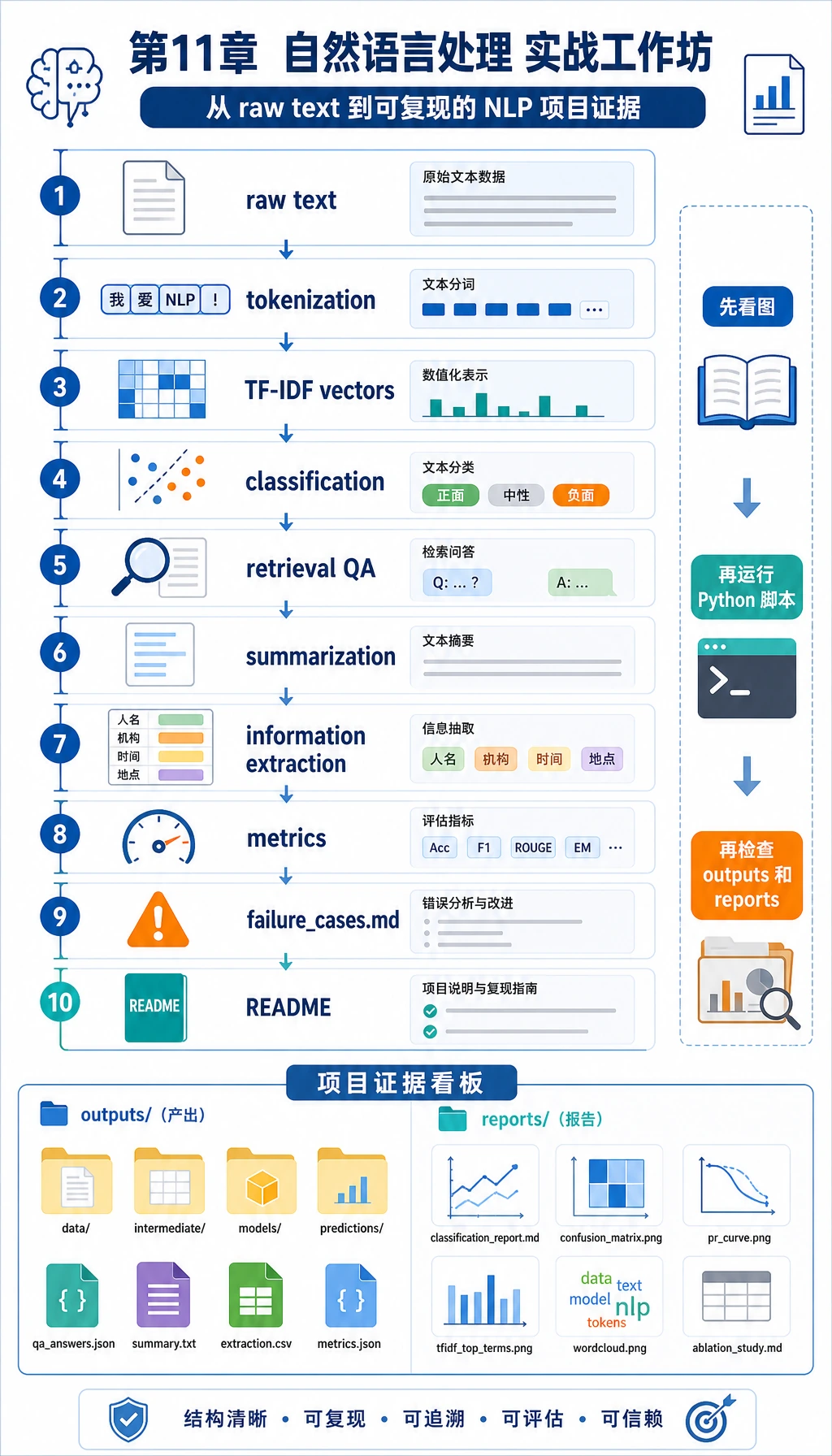
11.7.6 实操:构建一个可复现的 NLP 迷你流水线
在选择更大的 NLP 项目前,先把这个迷你流水线跑一遍。它会把本章抽象概念变成你能检查的文件:原始文本、token、TF-IDF 特征、分类预测、检索问答、摘要、结构化字段、指标和失败案例。
这个练习只使用 Python 标准库。TF-IDF 和质心分类是经典方法,不是最新模型家族,但这里是故意这样做:它透明、离线、快,适合作为 baseline。等你看清流程后,可以把其中一个模块替换成 scikit-learn、Transformers、embedding 或 LLM API。
你会构建什么
脚本会生成 nlp_workshop_run/ 文件夹,结构如下:
nlp_workshop_run/
data/
train_texts.csv
test_texts.csv
notes.jsonl
extraction_eval.jsonl
outputs/
classification_predictions.csv
qa_predictions.jsonl
summary_outputs.md
extraction_predictions.jsonl
reports/
classification_metrics.json
retrieval_qa_metrics.json
extraction_metrics.json
failure_cases.md
README.md
学习目标不是追求满分,而是让每个 NLP 结果都能追溯到任务定义、源文本、标签、证据、指标和失败样本。
Step 0:先看懂数据流
运行代码前,先按顺序看这条线:
- 小型本地数据集写入原始文本。
tokenize()把字符串切成 token。- TF-IDF 把 token 变成数值向量。
- 质心分类器预测一个固定标签。
- 检索问答 baseline 先选择最相关笔记,再回答。
- 简单抽取式摘要器选择原文句子。
- 正则抽取器把学习日志变成结构化字段。
- 指标和失败案例保存成项目证据。
Step 1:创建文件夹和脚本
可以在课程仓库外面,或任意临时目录里创建工作文件夹:
mkdir nlp-workshop
cd nlp-workshop
python3 -m venv .venv
source .venv/bin/activate
这个例子不需要 pip install,因为只用 Python 内置库。现在创建 nlp_workshop.py,粘贴下面完整脚本。
Step 2:运行完整脚本
from __future__ import annotations
import csv
import json
import math
import re
import shutil
from collections import Counter, defaultdict
from pathlib import Path
RUN_DIR = Path("nlp_workshop_run")
if RUN_DIR.exists():
shutil.rmtree(RUN_DIR)
DATA_DIR = RUN_DIR / "data"
REPORT_DIR = RUN_DIR / "reports"
OUTPUT_DIR = RUN_DIR / "outputs"
for folder in [DATA_DIR, REPORT_DIR, OUTPUT_DIR]:
folder.mkdir(parents=True, exist_ok=True)
STOPWORDS = {
"a", "an", "and", "are", "as", "at", "be", "before", "by", "can", "do", "for",
"from", "how", "i", "in", "is", "it", "of", "on", "or", "should", "the", "this",
"to", "what", "when", "with", "why", "you", "my", "into", "that", "not", "one",
}
TRAIN_TEXTS = [
("preprocessing", "Clean noisy course comments, lowercase text, remove repeated spaces, and keep useful tokens."),
("preprocessing", "Tokenization splits a raw sentence into words so later features can count them."),
("preprocessing", "Stop words and punctuation should be handled carefully because over cleaning can lose meaning."),
("preprocessing", "Normalize user questions before building a text classifier or retrieval index."),
("preprocessing", "A preprocessing pipeline records raw text, cleaned text, and token lists for review."),
("classification", "Classify each learner question into roadmap, debugging, evaluation, or deployment intent."),
("classification", "Text classification needs label definitions, train and test split, metrics, and error samples."),
("classification", "A sentiment classifier predicts positive, neutral, or negative labels for product reviews."),
("classification", "Confusion matrix shows which labels are mixed up by the classifier."),
("classification", "Accuracy alone is not enough when classes are imbalanced."),
("extraction", "Extract stage, task, metric, and deliverable fields from a study log."),
("extraction", "Named entity recognition marks people, products, places, dates, and organizations."),
("extraction", "Information extraction converts unstructured text into schema fields."),
("extraction", "A contract parser should extract parties, dates, amounts, and obligations."),
("extraction", "Field boundaries must be written down before evaluating extraction quality."),
("summarization", "Summarization compresses a long document while keeping the key facts and conditions."),
("summarization", "Extractive summaries choose important source sentences instead of inventing new facts."),
("summarization", "A good summary is short, faithful to the source, and readable."),
("summarization", "Factual consistency checks whether each summary claim is supported by the original text."),
("summarization", "Meeting notes can be summarized into decisions, risks, and next actions."),
("question_answering", "Question answering needs a knowledge scope, retrieved evidence, an answer, and refusal rules."),
("question_answering", "A QA system should say it does not know when the answer is outside the documents."),
("question_answering", "Retrieval finds the most relevant passage before the answer is written."),
("question_answering", "Citations help users verify where an answer came from."),
("question_answering", "Evaluation for QA checks answer support, retrieval accuracy, and refusal behavior."),
("pretrained_models", "BERT uses masked language modeling and is strong for understanding tasks."),
("pretrained_models", "GPT predicts the next token and is strong for generation tasks."),
("pretrained_models", "T5 turns many NLP tasks into text to text learning."),
("pretrained_models", "The Transformers library provides tokenizers, model loading, pipelines, and fine tuning tools."),
("pretrained_models", "Pretrained models still need clear task boundaries, evaluation sets, and error analysis."),
]
TEST_TEXTS = [
("preprocessing", "My text has emojis, duplicate spaces, and mixed casing before tokenization."),
("preprocessing", "Why did removing every short word damage my model input?"),
("classification", "I need to assign each support ticket to a fixed intent label."),
("classification", "The confusion matrix says roadmap questions are predicted as debugging questions."),
("extraction", "Please pull stage, task, metric, and deliverable from this learning note."),
("extraction", "The resume parser missed the company name and employment date fields."),
("summarization", "Turn this long meeting transcript into decisions and next actions."),
("summarization", "The summary sounds fluent but adds a condition not found in the source."),
("question_answering", "Which passage supports the answer and when should the bot refuse?"),
("question_answering", "My QA demo answers even when the document has no evidence."),
("pretrained_models", "Should I use BERT style understanding or GPT style next token generation?"),
("pretrained_models", "A tokenizer from the Transformers library converts text into model ids."),
]
NOTES = [
{
"id": "preprocess",
"title": "Text preprocessing",
"text": "Text preprocessing keeps a record of raw text, cleaned text, and tokens. Lowercasing, punctuation handling, and stop word choices should be reviewed because too much cleaning can remove useful meaning.",
},
{
"id": "tfidf",
"title": "TF-IDF baseline",
"text": "TF-IDF gives higher weight to words that are frequent in one document but not common in every document. It is a transparent baseline for classification and retrieval before using embeddings or large language models.",
},
{
"id": "classification",
"title": "Text classification",
"text": "Text classification maps a text input to one fixed label. A reliable classifier needs label definitions, train and test split, metrics, a confusion matrix, and error samples.",
},
{
"id": "extraction",
"title": "Information extraction",
"text": "Information extraction turns unstructured text into structured fields such as stage, task, metric, and deliverable. Field boundaries and schema rules must be defined before evaluation.",
},
{
"id": "summarization",
"title": "Summarization",
"text": "Summarization compresses long text into a shorter version. A good summary should preserve key facts, avoid unsupported claims, and remain readable.",
},
{
"id": "qa",
"title": "Question answering",
"text": "A question answering system should retrieve supporting evidence before answering. If the documents do not contain enough evidence, the system should refuse instead of guessing.",
},
{
"id": "pretrained",
"title": "Pretrained models",
"text": "BERT is often used for understanding tasks with masked language modeling, GPT is often used for generation with next token prediction, and T5 unifies tasks as text to text.",
},
]
QA_EVAL = [
("Why should I keep raw text during preprocessing?", "preprocess"),
("What does TF-IDF emphasize in a document?", "tfidf"),
("What evidence should a text classification project keep?", "classification"),
("Which rules matter before information extraction evaluation?", "extraction"),
("How do I check whether a summary is trustworthy?", "summarization"),
("When should a QA system refuse to answer?", "qa"),
("Which note explains optimizer momentum?", None),
]
EXTRACTION_EVAL = [
{
"text": "Stage 11 | Task: text classification | Metric: accuracy | Deliverable: classification_report.md",
"expected": {"stage": "11", "task": "text classification", "metric": "accuracy", "deliverable": "classification_report.md"},
},
{
"text": "Chapter 11 task information extraction should track metric exact match and deliverable extraction_examples.jsonl",
"expected": {"stage": "11", "task": "information extraction", "metric": "exact match", "deliverable": "extraction_examples.jsonl"},
},
{
"text": "For stage 11, build summarization, evaluate factual consistency, and save summary_outputs.md.",
"expected": {"stage": "11", "task": "summarization", "metric": "factual consistency", "deliverable": "summary_outputs.md"},
},
{
"text": "Stage 11 question answering uses retrieval accuracy and writes qa_predictions.jsonl.",
"expected": {"stage": "11", "task": "question answering", "metric": "retrieval accuracy", "deliverable": "qa_predictions.jsonl"},
},
{
"text": "Stage eleven asks for preprocessing notes, token examples, and a README file.",
"expected": {"stage": "11", "task": "preprocessing", "metric": "token examples", "deliverable": "README.md"},
},
]
SUMMARY_SOURCE = """
Natural language processing projects often fail because the task boundary is vague. A team may say they want a smart text assistant, but classification, extraction, summarization, and question answering require different outputs and metrics. A practical baseline should keep raw text, cleaned text, tokens, predictions, metrics, and failure examples. When a model gives a wrong answer, the team should check the label definition, the source evidence, and the evaluation set before changing the model. This habit also prepares the learner for RAG and Agent projects, where retrieval evidence and refusal behavior are part of reliability.
""".strip()
def tokenize(text: str) -> list[str]:
return [token for token in re.findall(r"[a-z0-9]+", text.lower()) if token not in STOPWORDS and len(token) > 1]
def write_csv(path: Path, rows: list[dict[str, str]], fieldnames: list[str]) -> None:
with path.open("w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(rows)
def write_jsonl(path: Path, rows: list[dict]) -> None:
with path.open("w", encoding="utf-8") as f:
for row in rows:
f.write(json.dumps(row, ensure_ascii=False) + "\n")
def fit_idf(texts: list[str]) -> dict[str, float]:
doc_count = len(texts)
df = Counter()
for text in texts:
df.update(set(tokenize(text)))
return {token: math.log((doc_count + 1) / (count + 1)) + 1 for token, count in df.items()}
def vectorize(text: str, idf: dict[str, float]) -> dict[str, float]:
counts = Counter(tokenize(text))
total = sum(counts.values()) or 1
return {token: (count / total) * idf.get(token, 1.0) for token, count in counts.items()}
def cosine(left: dict[str, float], right: dict[str, float]) -> float:
if not left or not right:
return 0.0
overlap = set(left) & set(right)
numerator = sum(left[token] * right[token] for token in overlap)
left_norm = math.sqrt(sum(value * value for value in left.values()))
right_norm = math.sqrt(sum(value * value for value in right.values()))
return numerator / (left_norm * right_norm) if left_norm and right_norm else 0.0
def average_vectors(vectors: list[dict[str, float]]) -> dict[str, float]:
merged = defaultdict(float)
for vector in vectors:
for token, value in vector.items():
merged[token] += value
return {token: value / len(vectors) for token, value in merged.items()}
def build_classifier(train_rows: list[dict[str, str]]) -> tuple[dict[str, float], dict[str, dict[str, float]]]:
idf = fit_idf([row["text"] for row in train_rows])
by_label = defaultdict(list)
for row in train_rows:
by_label[row["label"]].append(vectorize(row["text"], idf))
centroids = {label: average_vectors(vectors) for label, vectors in by_label.items()}
return idf, centroids
def predict_label(text: str, idf: dict[str, float], centroids: dict[str, dict[str, float]]) -> tuple[str, float, float]:
vector = vectorize(text, idf)
scores = sorted(((label, cosine(vector, centroid)) for label, centroid in centroids.items()), key=lambda item: item[1], reverse=True)
best_label, best_score = scores[0]
second_score = scores[1][1] if len(scores) > 1 else 0.0
return best_label, best_score, best_score - second_score
def confusion_matrix(rows: list[dict[str, str]]) -> dict[str, dict[str, int]]:
labels = sorted({row["expected"] for row in rows} | {row["predicted"] for row in rows})
matrix = {label: {other: 0 for other in labels} for label in labels}
for row in rows:
matrix[row["expected"]][row["predicted"]] += 1
return matrix
def retrieve(question: str, notes: list[dict], idf: dict[str, float]) -> tuple[dict | None, float, str]:
q_vec = vectorize(question, idf)
scored = []
for note in notes:
score = cosine(q_vec, vectorize(note["text"] + " " + note["title"], idf))
scored.append((score, note))
score, note = max(scored, key=lambda item: item[0])
if score < 0.08:
return None, score, "I do not know based on the provided notes."
answer = best_sentence(question, note["text"])
return note, score, answer
def best_sentence(question: str, text: str) -> str:
q_tokens = set(tokenize(question))
sentences = [s.strip() for s in re.split(r"(?<=[.!?])\s+", text) if s.strip()]
scored = []
for sentence in sentences:
s_tokens = set(tokenize(sentence))
score = len(q_tokens & s_tokens) / (len(q_tokens) or 1)
scored.append((score, sentence))
return max(scored, key=lambda item: item[0])[1]
def summarize(text: str, sentence_count: int = 2) -> list[str]:
sentences = [s.strip() for s in re.split(r"(?<=[.!?])\s+", text) if s.strip()]
idf = fit_idf(sentences)
scored = []
for idx, sentence in enumerate(sentences):
vec = vectorize(sentence, idf)
score = sum(vec.values()) / (len(tokenize(sentence)) or 1)
scored.append((score, idx, sentence))
chosen = sorted(sorted(scored, reverse=True)[:sentence_count], key=lambda item: item[1])
return [sentence for _, _, sentence in chosen]
def extract_fields(text: str) -> dict[str, str]:
lowered = text.lower()
stage_match = re.search(r"(?:stage|chapter)\s*(\d+)", lowered)
stage = stage_match.group(1) if stage_match else ("11" if "stage eleven" in lowered else "")
tasks = ["text classification", "information extraction", "question answering", "summarization", "preprocessing"]
metrics = ["retrieval accuracy", "factual consistency", "exact match", "accuracy", "token examples"]
deliverable_match = re.search(r"([a-z_]+\.(?:md|jsonl|csv))", lowered)
return {
"stage": stage,
"task": next((task for task in tasks if task in lowered), ""),
"metric": next((metric for metric in metrics if metric in lowered), ""),
"deliverable": deliverable_match.group(1) if deliverable_match else "",
}
def evaluate_extraction(rows: list[dict]) -> tuple[list[dict], int, int]:
predictions = []
correct = 0
total = 0
for row in rows:
predicted = extract_fields(row["text"])
field_scores = {}
for key, expected_value in row["expected"].items():
ok = predicted.get(key, "") == expected_value
field_scores[key] = ok
correct += int(ok)
total += 1
predictions.append({"text": row["text"], "expected": row["expected"], "predicted": predicted, "field_scores": field_scores})
return predictions, correct, total
def main() -> None:
train_rows = [{"label": label, "text": text} for label, text in TRAIN_TEXTS]
test_rows = [{"label": label, "text": text} for label, text in TEST_TEXTS]
write_csv(DATA_DIR / "train_texts.csv", train_rows, ["label", "text"])
write_csv(DATA_DIR / "test_texts.csv", test_rows, ["label", "text"])
write_jsonl(DATA_DIR / "notes.jsonl", NOTES)
write_jsonl(DATA_DIR / "extraction_eval.jsonl", EXTRACTION_EVAL)
idf, centroids = build_classifier(train_rows)
class_predictions = []
failure_cases = []
for row in test_rows:
predicted, score, margin = predict_label(row["text"], idf, centroids)
result = {
"text": row["text"],
"expected": row["label"],
"predicted": predicted,
"score": round(score, 4),
"margin": round(margin, 4),
"correct": predicted == row["label"],
}
class_predictions.append(result)
if not result["correct"] or margin < 0.06:
failure_cases.append({"type": "classification", "reason": "wrong label or low margin", **result})
class_correct = sum(row["correct"] for row in class_predictions)
class_metrics = {
"accuracy": class_correct / len(class_predictions),
"correct": class_correct,
"total": len(class_predictions),
"confusion_matrix": confusion_matrix(class_predictions),
}
write_csv(OUTPUT_DIR / "classification_predictions.csv", class_predictions, ["text", "expected", "predicted", "score", "margin", "correct"])
(REPORT_DIR / "classification_metrics.json").write_text(json.dumps(class_metrics, indent=2), encoding="utf-8")
retrieval_idf = fit_idf([note["title"] + " " + note["text"] for note in NOTES] + [q for q, _ in QA_EVAL])
qa_predictions = []
for question, expected_id in QA_EVAL:
note, score, answer = retrieve(question, NOTES, retrieval_idf)
predicted_id = note["id"] if note else None
correct = predicted_id == expected_id
result = {
"question": question,
"expected_doc_id": expected_id,
"predicted_doc_id": predicted_id,
"score": round(score, 4),
"answer": answer,
"correct": correct,
}
qa_predictions.append(result)
if not correct or (expected_id is not None and score < 0.18):
failure_cases.append({"type": "retrieval_qa", "reason": "wrong document or weak evidence", **result})
qa_correct = sum(row["correct"] for row in qa_predictions)
qa_metrics = {"retrieval_accuracy": qa_correct / len(qa_predictions), "correct": qa_correct, "total": len(qa_predictions)}
write_jsonl(OUTPUT_DIR / "qa_predictions.jsonl", qa_predictions)
(REPORT_DIR / "retrieval_qa_metrics.json").write_text(json.dumps(qa_metrics, indent=2), encoding="utf-8")
summary = summarize(SUMMARY_SOURCE)
summary_text = "# Summary Output\n\n## Source\n\n" + SUMMARY_SOURCE + "\n\n## Extractive Summary\n\n" + "\n".join(f"- {sentence}" for sentence in summary) + "\n"
(OUTPUT_DIR / "summary_outputs.md").write_text(summary_text, encoding="utf-8")
extraction_predictions, extraction_correct, extraction_total = evaluate_extraction(EXTRACTION_EVAL)
extraction_metrics = {
"field_accuracy": extraction_correct / extraction_total,
"correct_fields": extraction_correct,
"total_fields": extraction_total,
}
write_jsonl(OUTPUT_DIR / "extraction_predictions.jsonl", extraction_predictions)
(REPORT_DIR / "extraction_metrics.json").write_text(json.dumps(extraction_metrics, indent=2), encoding="utf-8")
for row in extraction_predictions:
if not all(row["field_scores"].values()):
failure_cases.append({"type": "information_extraction", "reason": "field mismatch", **row})
failure_lines = ["# Failure Cases", ""]
if not failure_cases:
failure_lines.append("No failure cases were triggered. Lower one threshold or add harder samples before using this as a portfolio report.")
for idx, item in enumerate(failure_cases, start=1):
failure_lines.append(f"## Case {idx}: {item['type']}")
failure_lines.append(f"- Reason: {item['reason']}")
if "text" in item:
failure_lines.append(f"- Text: {item['text']}")
if "question" in item:
failure_lines.append(f"- Question: {item['question']}")
failure_lines.append(f"- Evidence: `{json.dumps(item, ensure_ascii=False)}`")
failure_lines.append("- Fix action: inspect task boundary, labels, source evidence, or threshold, then rerun the script.")
failure_lines.append("")
(REPORT_DIR / "failure_cases.md").write_text("\n".join(failure_lines), encoding="utf-8")
readme = f"""# NLP Workshop Run
Run command:
~~~bash
python nlp_workshop.py
~~~
Artifacts:
- data/train_texts.csv and data/test_texts.csv
- outputs/classification_predictions.csv
- outputs/qa_predictions.jsonl
- outputs/summary_outputs.md
- outputs/extraction_predictions.jsonl
- reports/classification_metrics.json
- reports/retrieval_qa_metrics.json
- reports/extraction_metrics.json
- reports/failure_cases.md
Key metrics:
- classification_accuracy: {class_metrics['accuracy']:.3f}
- retrieval_accuracy: {qa_metrics['retrieval_accuracy']:.3f}
- extraction_field_accuracy: {extraction_metrics['field_accuracy']:.3f}
"""
(RUN_DIR / "README.md").write_text(readme, encoding="utf-8")
print("STEP 1: dataset")
print(f"train_texts: {len(train_rows)}")
print(f"test_texts: {len(test_rows)}")
print(f"notes: {len(NOTES)}")
print("")
print("STEP 2: evaluation")
print(f"classification_accuracy: {class_metrics['accuracy']:.3f} ({class_correct}/{len(class_predictions)})")
print(f"retrieval_accuracy: {qa_metrics['retrieval_accuracy']:.3f} ({qa_correct}/{len(qa_predictions)})")
print(f"extraction_field_accuracy: {extraction_metrics['field_accuracy']:.3f} ({extraction_correct}/{extraction_total})")
print(f"failure_cases: {len(failure_cases)}")
print("")
print("STEP 3: files to inspect")
print(f"classification_predictions: {OUTPUT_DIR / 'classification_predictions.csv'}")
print(f"qa_predictions: {OUTPUT_DIR / 'qa_predictions.jsonl'}")
print(f"summary_outputs: {OUTPUT_DIR / 'summary_outputs.md'}")
print(f"failure_report: {REPORT_DIR / 'failure_cases.md'}")
if __name__ == "__main__":
main()
运行:
python nlp_workshop.py
预期输出:
STEP 1: dataset
train_texts: 30
test_texts: 12
notes: 7
STEP 2: evaluation
classification_accuracy: 0.917 (11/12)
retrieval_accuracy: 1.000 (7/7)
extraction_field_accuracy: 0.950 (19/20)
failure_cases: 3
STEP 3: files to inspect
classification_predictions: nlp_workshop_run/outputs/classification_predictions.csv
qa_predictions: nlp_workshop_run/outputs/qa_predictions.jsonl
summary_outputs: nlp_workshop_run/outputs/summary_outputs.md
failure_report: nlp_workshop_run/reports/failure_cases.md

终端输出只是这次运行的目录。先打开预测文件、指标文件和失败报告,再判断这个 NLP pipeline 是否真的可用。
Step 3:阅读数据文件
打开 nlp_workshop_run/data/train_texts.csv。每一行都有 label 和 text,这就是监督式文本分类数据集的最小形态。
再打开 nlp_workshop_run/data/notes.jsonl。每一行是一条知识笔记。检索问答任务不是凭空回答,而是先选中一条笔记,再复制最相关的句子作为答案。这就是后面做 RAG 时必须保留的证据习惯。
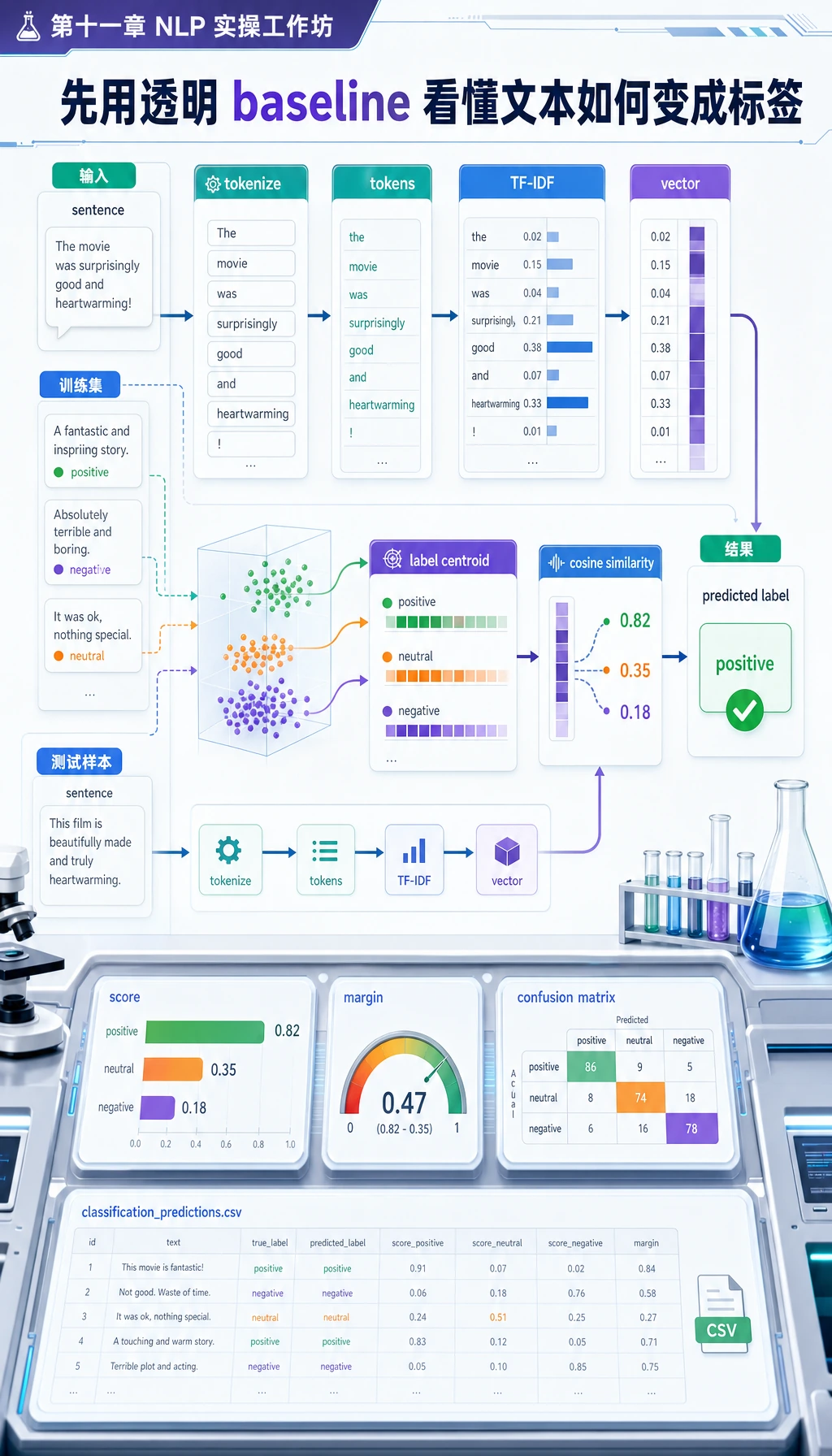
Step 4:理解 Tokenization 和 TF-IDF
脚本里的 tokenize() 会把文本转小写、去掉标点、去掉简单 stop words,并保留有意义的 token。很多新人问题都出在这里。
fit_idf() 会统计每个 token 在不同文档里的稀有程度。vectorize() 会把词频乘上 IDF。到处都出现的词帮助不大;能区分一个任务的词更有价值。
真实项目中,你可以把这里替换成 TfidfVectorizer、embedding,或 Transformers 里的 tokenizer。但底层思路不变:文本必须先变成表示,模型才能比较。
Step 5:检查分类结果
打开 nlp_workshop_run/outputs/classification_predictions.csv。
重点看这些列:
| 列 | 含义 |
|---|---|
expected | 人工标签 |
predicted | 模型预测标签 |
score | 与预测标签质心的相似度 |
margin | 第一名和第二名标签的差距 |
correct | 是否预测正确 |
margin 很低时,即使预测正确,模型也不太确定。真实 NLP 项目里,这类低置信样本通常最适合拿来改进标签定义。
Step 6:检查检索问答、摘要和信息抽取
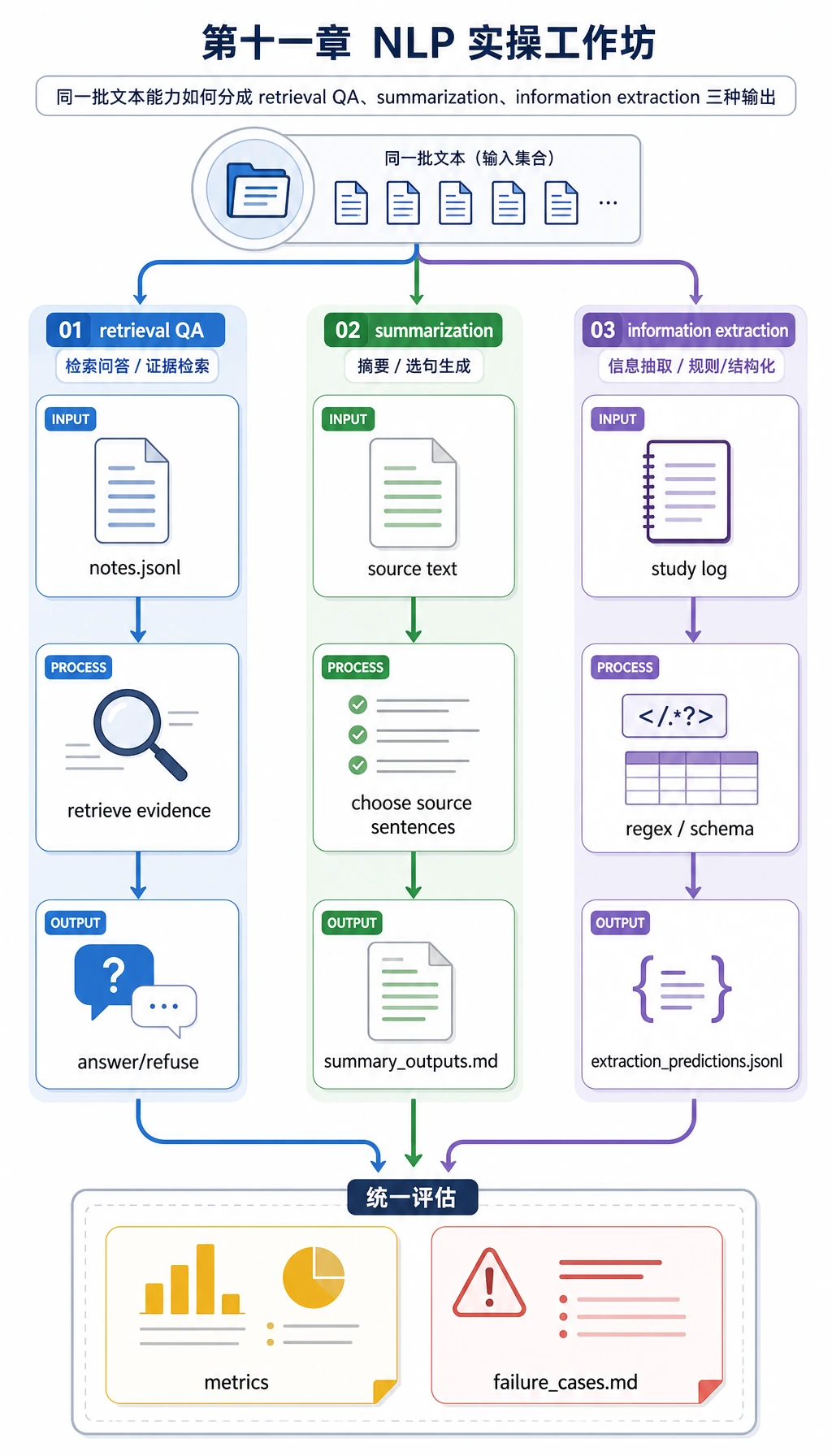
打开 nlp_workshop_run/outputs/qa_predictions.jsonl。其中越界问题是:
Which note explains optimizer momentum?
因为笔记里没有 optimizer momentum,系统应该拒答。这是可靠问答系统最重要的习惯之一:来源不支持时不要猜。
然后打开 nlp_workshop_run/outputs/summary_outputs.md。这里用的是抽取式摘要,所以每句话都来自原文。它比生成式摘要简单,但对新人更容易评估。
最后打开 nlp_workshop_run/outputs/extraction_predictions.jsonl。比较 expected、predicted 和 field_scores。信息抽取不只是找几个词,而是让输出匹配 schema。
Step 7:阅读指标
打开三个指标文件:
nlp_workshop_run/reports/classification_metrics.json
nlp_workshop_run/reports/retrieval_qa_metrics.json
nlp_workshop_run/reports/extraction_metrics.json
关键点是:不同 NLP 任务需要不同指标。
| 任务 | 输出 | 本练习指标 |
|---|---|---|
| 文本分类 | 一个固定标签 | Accuracy 和 confusion matrix |
| 检索问答 | 证据笔记加答案/拒答 | Retrieval accuracy |
| 文本摘要 | 更短文本 | 人工检查是否有来源支持 |
| 信息抽取 | 结构化字段 | Field accuracy |
Step 8:阅读失败报告

打开 nlp_workshop_run/reports/failure_cases.md。这个文件不是为了证明模型差,而是为了告诉你下一步该改哪里。
每个 case 都问自己:
- 任务边界是不是不清楚?
- 标签或 schema 是否太模糊?
- 预处理是否删掉了有用证据?
- 来源笔记里是否缺少答案?
- 阈值是不是太松或太严?
如果你能用具体证据回答这些问题,你做的就不是“调模型”,而是在做 NLP 工程。
Step 9:常见错误
| 现象 | 可能原因 | 修复方向 |
|---|---|---|
| 所有预测都变成一个标签 | 训练数据太少,或不同标签用词太像 | 增加样本,写清标签定义 |
| 准确率高但样例很差 | 数据集太简单或类别不平衡 | 增加边界样本,查看 confusion matrix |
| QA 会回答无依据问题 | 检索阈值太低 | 提高阈值,保留拒答测试 |
| 抽取漏字段 | 正则或 schema 规则不匹配真实文本 | 增加字段样例和边界样本 |
| 摘要流畅但不真实 | 没有和原文核对 | 保留来源句子并检查事实 |
Step 10:练习任务
第一次跑通后,可以继续做这些升级:
- 给
TRAIN_TEXTS和TEST_TEXTS增加两个新标签,再观察 confusion matrix 是否变化。 - 给
QA_EVAL增加一个更难的越界问题,确认系统会拒答。 - 给
EXTRACTION_EVAL增加risk字段,并更新extract_fields()。 - 把质心分类器替换成 scikit-learn 的
TfidfVectorizer和LogisticRegression。 - 把笔记检索替换成 embedding 或 LLM 支持的 RAG,但继续保留同样的输出文件和指标。
完成标准
完成本练习后,你应该能解释:
- 为什么原始文本必须清洗和切词;
- TF-IDF 为什么适合作为透明 baseline;
- 为什么分类、检索问答、摘要和抽取的输出不同;
- 哪些文件能证明流水线真的跑过;
- 失败报告如何指导下一步改进。
如果你能把这些产物写进 README,就已经有了第 11 章的实操 baseline,也为后面的 RAG、LLM 应用和 Agent 记忆打好了桥。