11.5.1 Seq2Seq 路线图:输入序列到输出序列
Seq2Seq 处理输入和输出都是序列的任务:翻译、总结、改写、对话和纠错。
先看生成桥梁

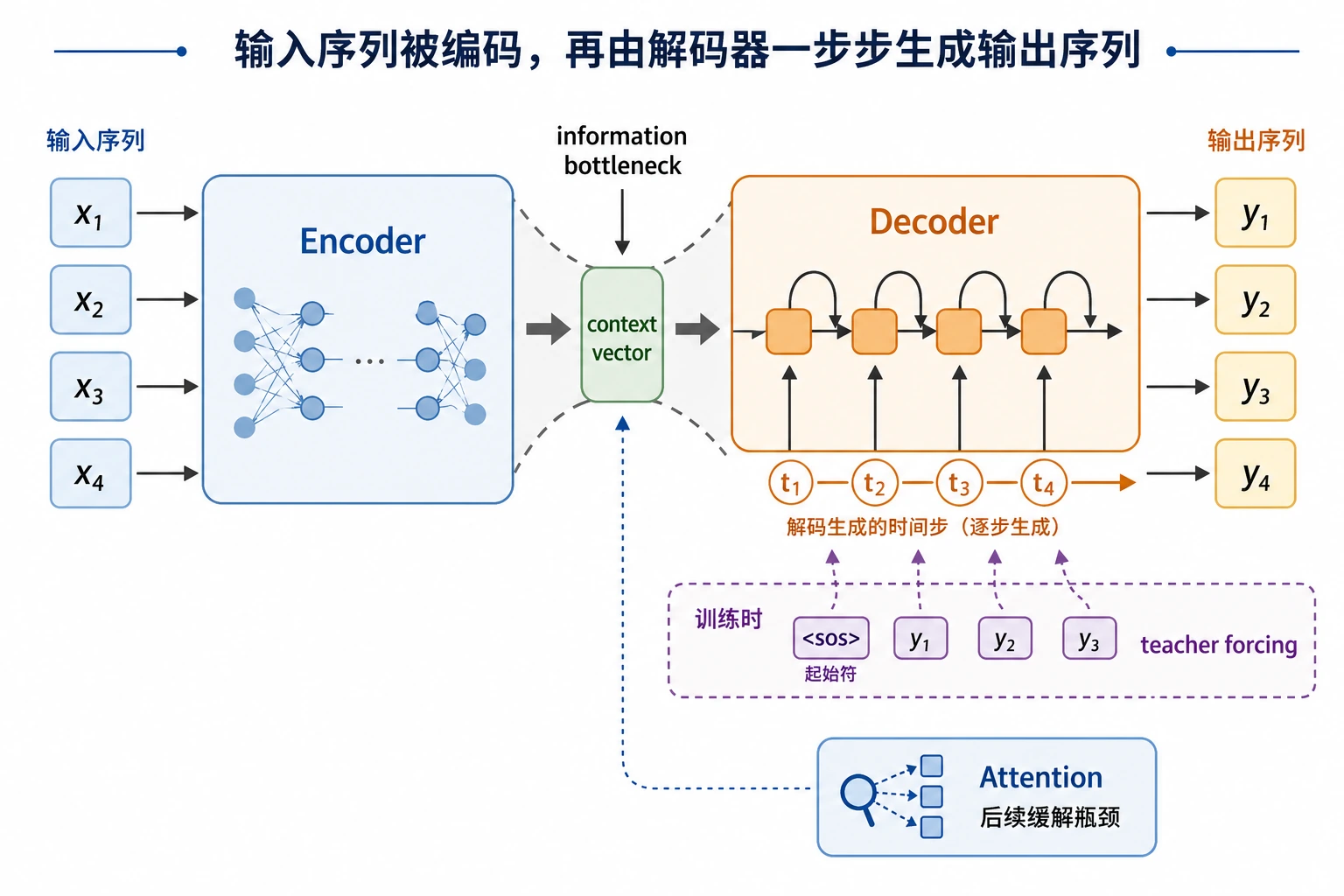
通往现代 LLM 的桥梁很清楚:生成是一步步发生的,Attention 帮助 decoder 回看有用的输入位置。
跑一个输入输出对检查
source = ["I", "love", "NLP"]
target = ["J'aime", "le", "NLP"]
for step, token in enumerate(target, start=1):
print(f"decode_step_{step}:", token)
print("source_length:", len(source))
print("target_length:", len(target))
预期输出:
decode_step_1: J'aime
decode_step_2: le
decode_step_3: NLP
source_length: 3
target_length: 3
生成项目应该记录解码策略、失败案例,以及关键输入信息是否丢失。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | Encoder-Decoder | 解释为什么输入和输出长度可以不同 |
| 2 | Attention | 解释生成时的动态对齐 |
| 3 | 机器翻译 | 连接 teacher forcing、解码、BLEU/错误分析 |
| 4 | CTC 与语音 | 理解输入输出不逐帧对齐时会发生什么 |
通过标准
如果你能解释 Encoder-Decoder、Attention、greedy/beam decoding 和一个生成失败,就通过了本章。