0.1 30 分钟 AI 快速体验
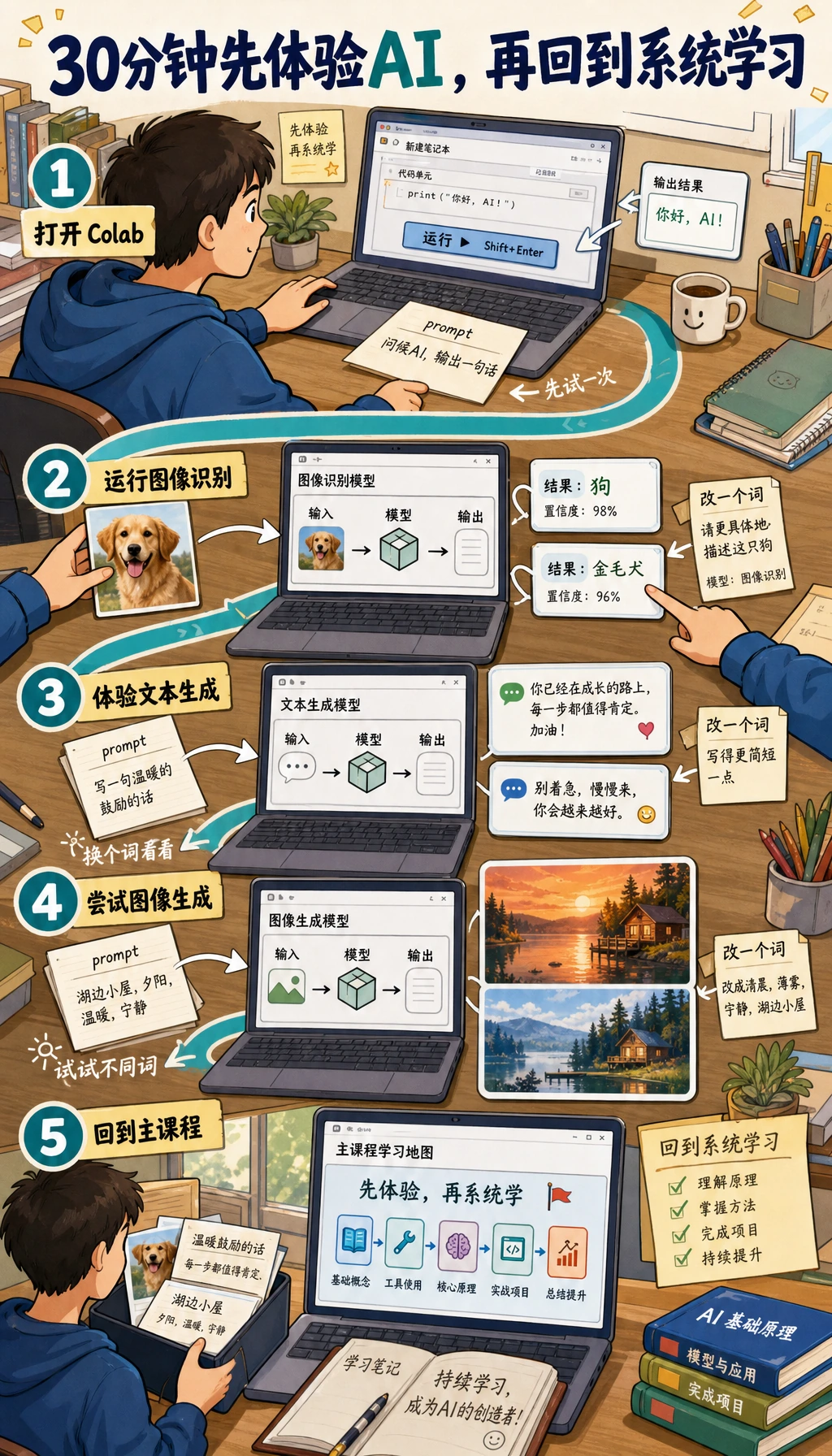
**先感受闭环:**输入 -> 模型 -> 输出 -> 检查。现在不用背术语。
最快无代码体验
打开你能访问的任意 AI 聊天或图像工具,输入:
用一个比喻给新手解释 RAG。
再把“新手”改成“开发者”,比较两次输出有什么不同。目标不是判断 AI 聪不聪明,而是观察一个小小的输入变化,怎样改变结构、用词、例子和自信程度。
| 改什么 | 看什么 |
|---|---|
读者:新手 -> 开发者 | 例子和词汇有没有变化 |
约束:加上80 字以内 | 模型是否遵守长度和重点 |
格式:加上给 3 条要点 | 输出是否更容易扫读 |
证据:加上包含一个局限 | 它是否说明答案不能保证什么 |
这个小比较,是整门课的第一个习惯:不要只看一次输出。改一个条件、做比较、留下更好的结果。
可选 Colab 体验
打开 Google Colab,新建 Notebook,运行:
!pip install transformers torch pillow requests -q
from transformers import pipeline
from PIL import Image
import io
import requests
classifier = pipeline("image-classification", model="google/vit-base-patch16-224")
url = "https://upload.wikimedia.org/wikipedia/commons/thumb/2/26/YellowLabradorLooking_new.jpg/1200px-YellowLabradorLooking_new.jpg"
image = Image.open(io.BytesIO(requests.get(url, headers={"User-Agent": "Mozilla/5.0"}).content))
for row in classifier(image)[:3]:
print(f"{row['label']:30s} {row['score']:.1%}")
预期形状:
Labrador retriever 95.6%
golden retriever 1.0%
kuvasz 0.5%
你的数字可能不同。重要的是输出形状:按分数排序的标签列表。
读懂结果
| 新人问题 | 实用回答 | 更深一层信号 |
|---|---|---|
| 输入是什么 | 一个来自 URL 的图片 | 真实系统要检查文件类型、大小、来源和隐私 |
| 模型是什么 | 一个预训练图像分类器 | 它只认识训练设定里的标签 |
| 输出是什么 | 前几名标签和分数 | 高分不是事实证明,只是模型置信度 |
| 会在哪里失败 | 下载、安装或模型加载可能失败 | 可靠 AI 工作需要日志、备用路径和可复现环境 |
如果 Colab 失败,不要花一整天卡在这里。保存报错信息,先完成无代码体验,学完第 1 章的终端、Python 和环境后再回来。
留下一条笔记
新建一条短笔记,写四行:
试过的输入:
观察到的输出:
我改了什么:
输出怎样变化:
这里的 AI 不神秘:你给输入,训练好的模型处理它,你检查输出。有经验的学习者还要注意隐藏的工程工作:依赖安装耗时、模型下载、输入验证、模型边界,以及证据怎样被记录。下一步去准备最小环境。