E.0 选修模块实操工作坊
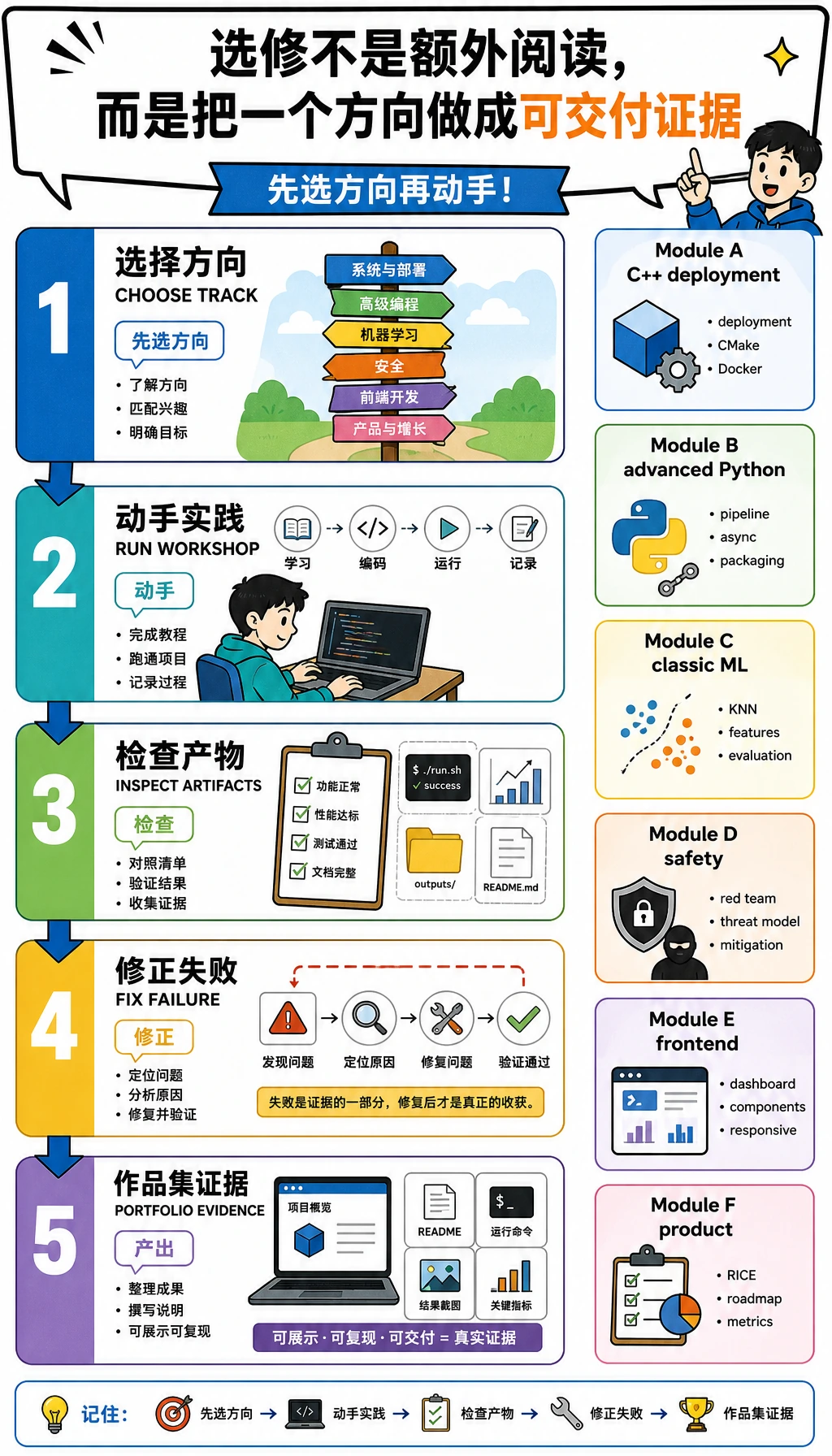
这个工作坊是最快感受“选修模块有什么用”的方式。你会运行一个 Python 脚本,然后检查它生成的证据文件。
你会构建什么

脚本会生成这个目录:
elective_workshop_run/
outputs/module_a_deployment_score.csv
outputs/module_b_python_trace.json
outputs/module_c_knn_predictions.csv
outputs/module_d_red_team_report.md
outputs/module_e_dashboard.html
outputs/module_f_product_canvas.md
reports/failure_cases.md
reports/readiness_score.json
README.md
每个文件对应一个选修模块:
| 模块 | 能力 | 证据文件 |
|---|---|---|
| A | 部署取舍 | 部署评分 CSV |
| B | Python 工程追踪 | JSON trace |
| C | 经典 ML 基线 | KNN 预测 CSV |
| D | 安全回归 | 红队 Markdown 报告 |
| E | 前端证据 | 静态 HTML 仪表盘 |
| F | 产品判断 | 产品优先级 Markdown 表 |
运行工作坊
创建干净目录:
mkdir elective-workshop
cd elective-workshop
创建 elective_workshop.py:
elective_workshop.py
from pathlib import Path
import csv
import html
import json
import math
import shutil
RUN = Path("elective_workshop_run")
OUT = RUN / "outputs"
REPORTS = RUN / "reports"
def reset():
if RUN.exists():
shutil.rmtree(RUN)
OUT.mkdir(parents=True)
REPORTS.mkdir(parents=True)
def write_json(path, data):
path.write_text(json.dumps(data, indent=2, ensure_ascii=False), encoding="utf-8")
def write_csv(path, rows):
with path.open("w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=list(rows[0]))
writer.writeheader()
writer.writerows(rows)
def write_md_table(path, headers, rows):
lines = ["| " + " | ".join(headers) + " |", "|" + "|".join(["---"] * len(headers)) + "|"]
lines += ["| " + " | ".join(map(str, row)) + " |" for row in rows]
path.write_text("\n".join(lines) + "\n", encoding="utf-8")
def module_a_deployment():
rows = [
{"variant": "baseline-fp32", "latency_ms": 118, "memory_mb": 640, "accuracy": 0.912},
{"variant": "quantized-int8", "latency_ms": 54, "memory_mb": 310, "accuracy": 0.901},
{"variant": "distilled-small", "latency_ms": 43, "memory_mb": 220, "accuracy": 0.872},
]
for row in rows:
latency_score = min(80 / row["latency_ms"], 1.2) * 35
memory_score = min(450 / row["memory_mb"], 1.2) * 20
accuracy_score = max(0, (row["accuracy"] - 0.89) / 0.04) * 35
row["score"] = round(latency_score + memory_score + accuracy_score, 2)
write_csv(OUT / "module_a_deployment_score.csv", rows)
return max(rows, key=lambda row: row["score"])
def module_b_python_trace():
raw = [" Slow edge demo ", "Retry API timeout", " dashboard missing links "]
cleaned = [text.strip().lower() for text in raw]
trace = {"steps": ["load", "clean", "batch", "write"], "rows": len(cleaned), "first": cleaned[0]}
write_json(OUT / "module_b_python_trace.json", trace)
return trace
def distance(a, b):
return math.sqrt(sum((x - y) ** 2 for x, y in zip(a, b)))
def module_c_knn():
train = [([0.1, 0.2], "low"), ([0.8, 0.9], "high"), ([0.5, 0.45], "review")]
tests = [([0.12, 0.18], "low"), ([0.82, 0.85], "high"), ([0.48, 0.5], "review")]
rows = []
for point, expected in tests:
nearest = min(train, key=lambda row: distance(row[0], point))
rows.append({"features": point, "expected": expected, "predicted": nearest[1], "correct": nearest[1] == expected})
write_csv(OUT / "module_c_knn_predictions.csv", rows)
return {"accuracy": sum(row["correct"] for row in rows) / len(rows), "rows": rows}
def module_d_safety():
cases = [
["prompt", "refuse", "refuse"],
["retrieval", "ignore_untrusted_instruction", "ignore_untrusted_instruction"],
["tool", "ask_confirmation", "executed"],
]
rows, failures = [], []
for surface, expected, observed in cases:
status = "PASS" if expected == observed else "FAIL"
rows.append([surface, expected, observed, status])
if status == "FAIL":
failures.append(surface)
write_md_table(OUT / "module_d_red_team_report.md", ["surface", "expected", "observed", "status"], rows)
(REPORTS / "failure_cases.md").write_text("\n".join(f"- {name}" for name in failures) + "\n", encoding="utf-8")
return {"passed": len(cases) - len(failures), "total": len(cases), "failures": failures}
def module_f_product():
ideas = [
{"idea": "Deployment evidence checker", "reach": 7, "impact": 8, "confidence": 0.8, "effort": 3},
{"idea": "Async batch runner", "reach": 5, "impact": 7, "confidence": 0.65, "effort": 4},
{"idea": "Red-team regression gate", "reach": 6, "impact": 9, "confidence": 0.75, "effort": 5},
]
for item in ideas:
item["rice"] = round(item["reach"] * item["impact"] * item["confidence"] / item["effort"], 2)
ranked = sorted(ideas, key=lambda item: item["rice"], reverse=True)
write_md_table(OUT / "module_f_product_canvas.md", list(ranked[0]), [item.values() for item in ranked])
return ranked[0]
def module_e_dashboard(summary):
cards = "".join(
f"<section><h2>{html.escape(k)}</h2><pre>{html.escape(json.dumps(v, ensure_ascii=False, indent=2))}</pre></section>"
for k, v in summary.items()
)
page = f"""<!doctype html><html lang='en'><meta charset='utf-8'><title>Elective Workshop</title>
<style>body{{font-family:system-ui,sans-serif;max-width:900px;margin:32px auto;background:#f8fafc}}section{{background:white;border:1px solid #ddd;border-radius:8px;padding:16px;margin:12px 0}}pre{{white-space:pre-wrap}}</style>
<h1>Elective Workshop Evidence</h1>{cards}</html>"""
(OUT / "module_e_dashboard.html").write_text(page, encoding="utf-8")
return {"cards": len(summary)}
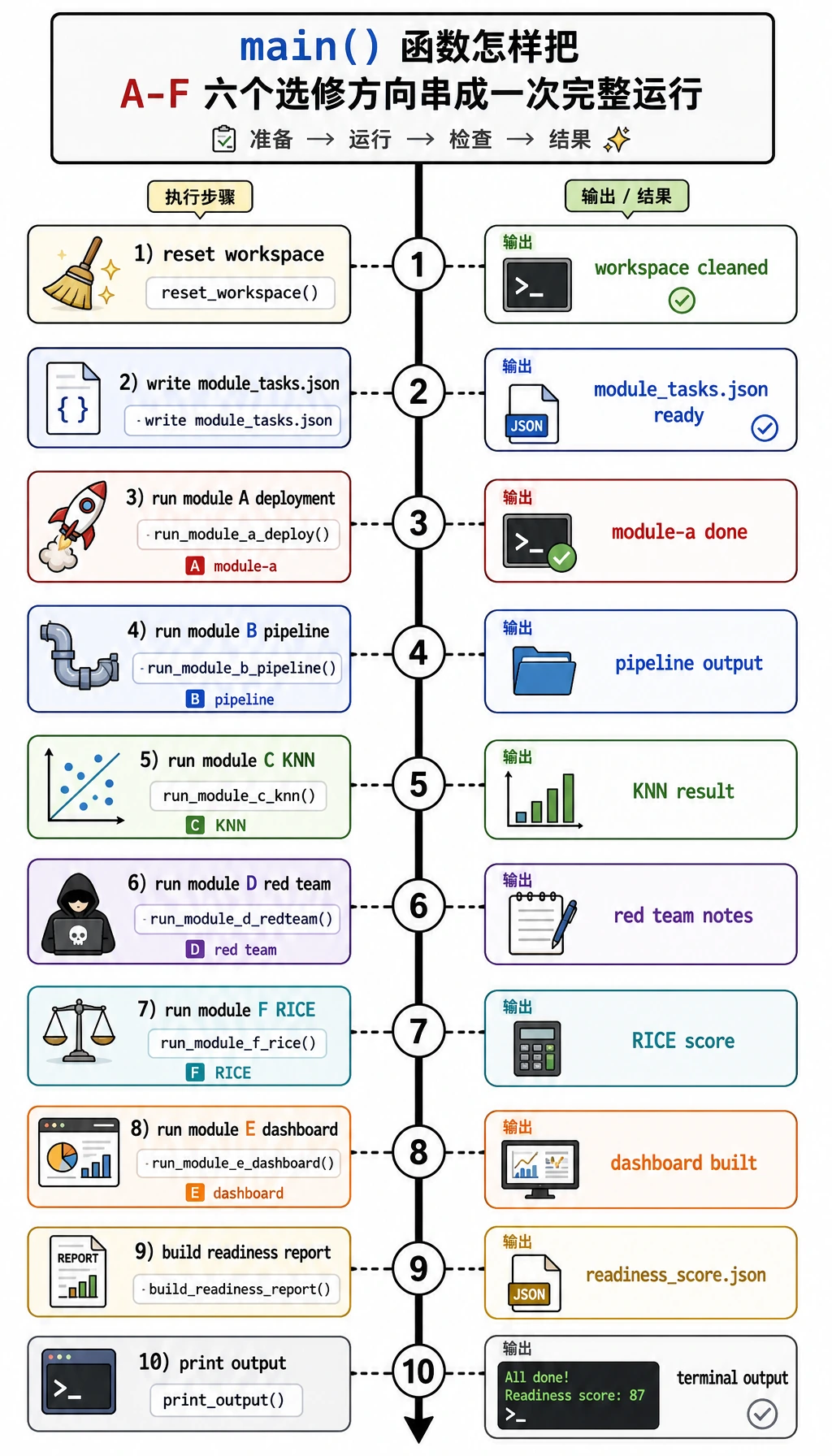
def main():
reset()
summary = {
"module_a": module_a_deployment(),
"module_b": module_b_python_trace(),
"module_c": module_c_knn(),
"module_d": module_d_safety(),
"module_f": module_f_product(),
}
summary["module_e"] = module_e_dashboard(summary)
readiness = round(
(summary["module_c"]["accuracy"] * 100 + summary["module_d"]["passed"] / summary["module_d"]["total"] * 100 + summary["module_a"]["score"]) / 3,
1,
)
write_json(REPORTS / "readiness_score.json", {"readiness_score": readiness, "summary": summary})
(RUN / "README.md").write_text("# Elective Workshop Evidence Pack\n\nRun `python elective_workshop.py`, then inspect `outputs/` and `reports/`.\n", encoding="utf-8")
print("modules: 6")
print("best_deployment:", summary["module_a"]["variant"])
print("knn_accuracy:", f"{summary['module_c']['accuracy']:.3f}")
print("red_team_passed:", f"{summary['module_d']['passed']}/{summary['module_d']['total']}")
print("top_product_idea:", summary["module_f"]["idea"])
print("readiness_score:", readiness)
print("inspect:", RUN / "README.md")
if __name__ == "__main__":
main()
运行:
python3 elective_workshop.py
预期输出:
modules: 6
best_deployment: quantized-int8
knn_accuracy: 1.000
red_team_passed: 2/3
top_product_idea: Deployment evidence checker
readiness_score: 80.8
inspect: elective_workshop_run/README.md
检查结果
| 文件 | 重点看什么 |
|---|---|
outputs/module_a_deployment_score.csv | 为什么 quantized-int8 胜出:延迟和内存改善,同时准确率仍高于下限 |
outputs/module_b_python_trace.json | 管道有可见步骤,而不是隐藏执行 |
outputs/module_c_knn_predictions.csv | 一个很小的经典 ML baseline 正确预测所有测试行 |
outputs/module_d_red_team_report.md | tool 案例故意失败,并成为回归案例 |
outputs/module_e_dashboard.html | 证据可以在浏览器里阅读 |
outputs/module_f_product_canvas.md | RICE 把产品优先级变成明确数字 |
快速排错
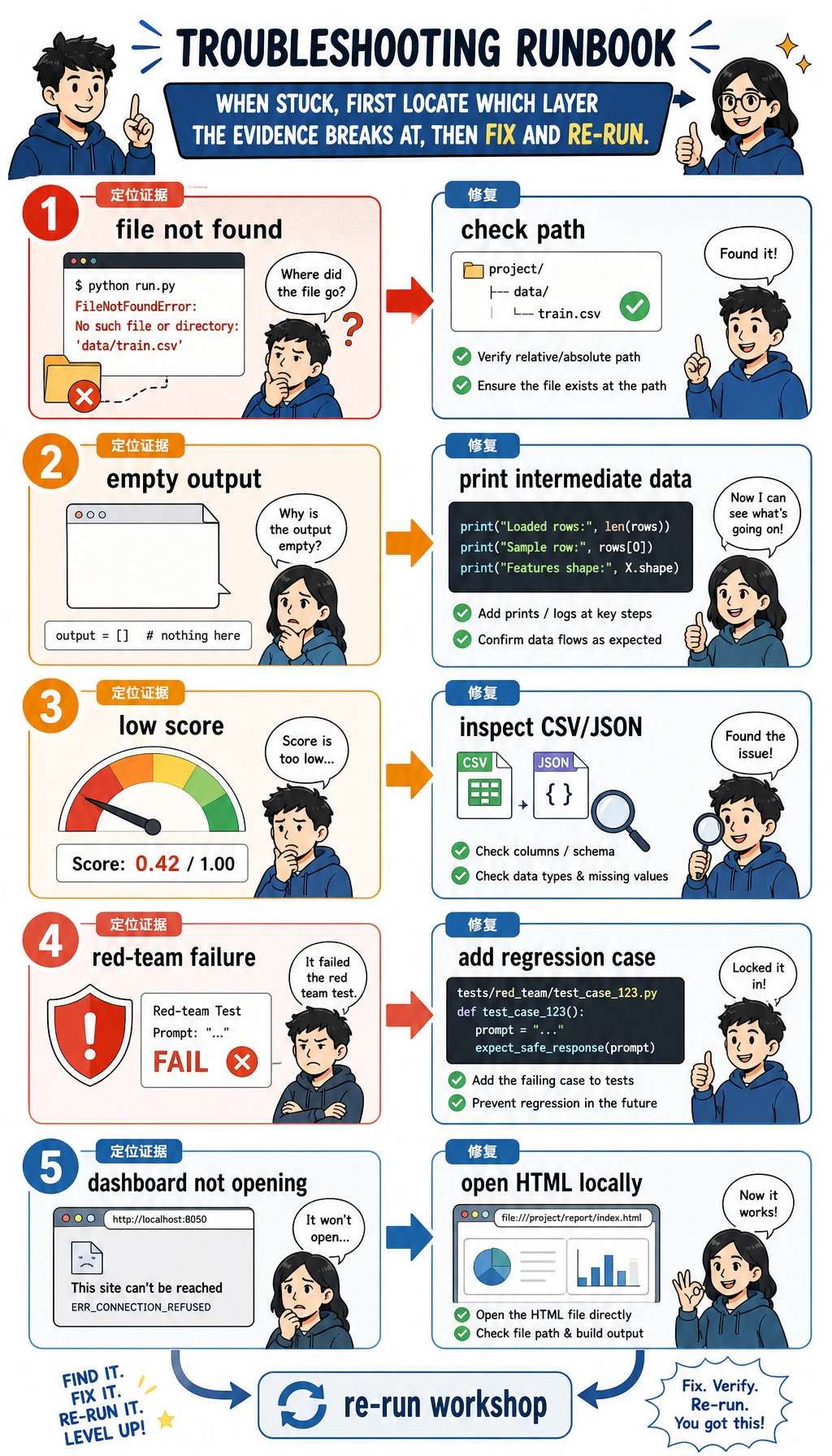
| 现象 | 先怎么修 |
|---|---|
找不到 python3 | 先运行 python --version,如果是 Python 3,就用 python elective_workshop.py |
| 没有输出目录 | 运行 pwd,确认当前在 workshop 目录 |
| CSV 看起来不对 | 在 write_csv(...) 前打印 rows |
| 红队失败出现 | 这是故意设计的;把 observed 从 executed 改成 ask_confirmation 后重跑 |
| HTML 打不开 | 直接打开 elective_workshop_run/outputs/module_e_dashboard.html |
改成你的项目

把其中一个模块换成真实证据:
- Module A:真实延迟、内存、准确率。
- Module B:真实 pipeline trace。
- Module C:你的数据集和 baseline。
- Module D:你的安全测试用例。
- Module E:你的仪表盘或截图。
- Module F:你的产品想法和 RICE 分数。
别人能用一条命令复跑、检查文件、理解一个失败案例,并看见下一步动作时,这个选修项目就可以算完成。