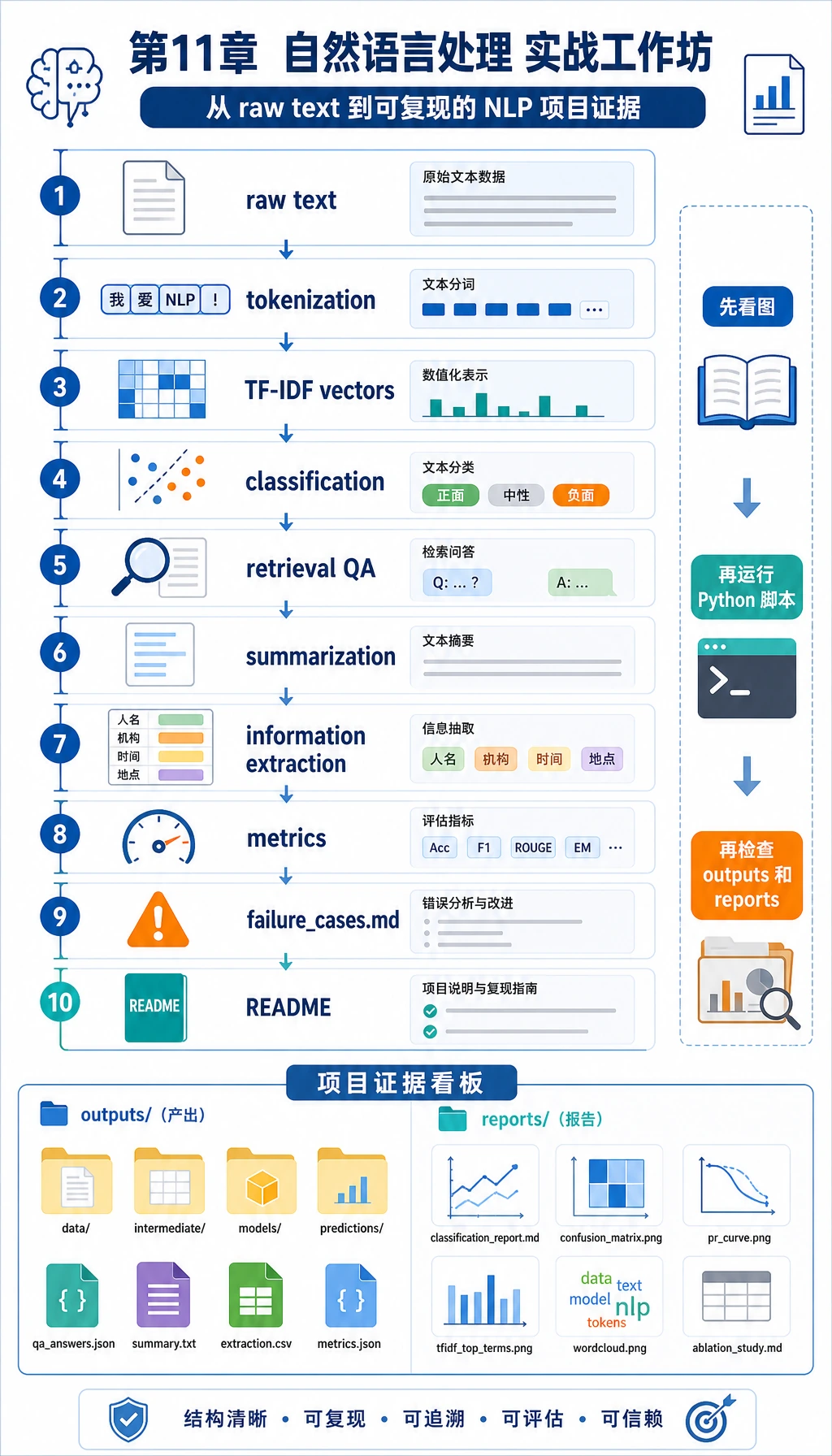
11.7.1 项目路线图:构建可评估 NLP 流水线
NLP 项目不是一段流畅输出,而是清晰任务边界、数据来源、baseline、评估方法、失败分析和结构化交付物。
先看项目证据闭环
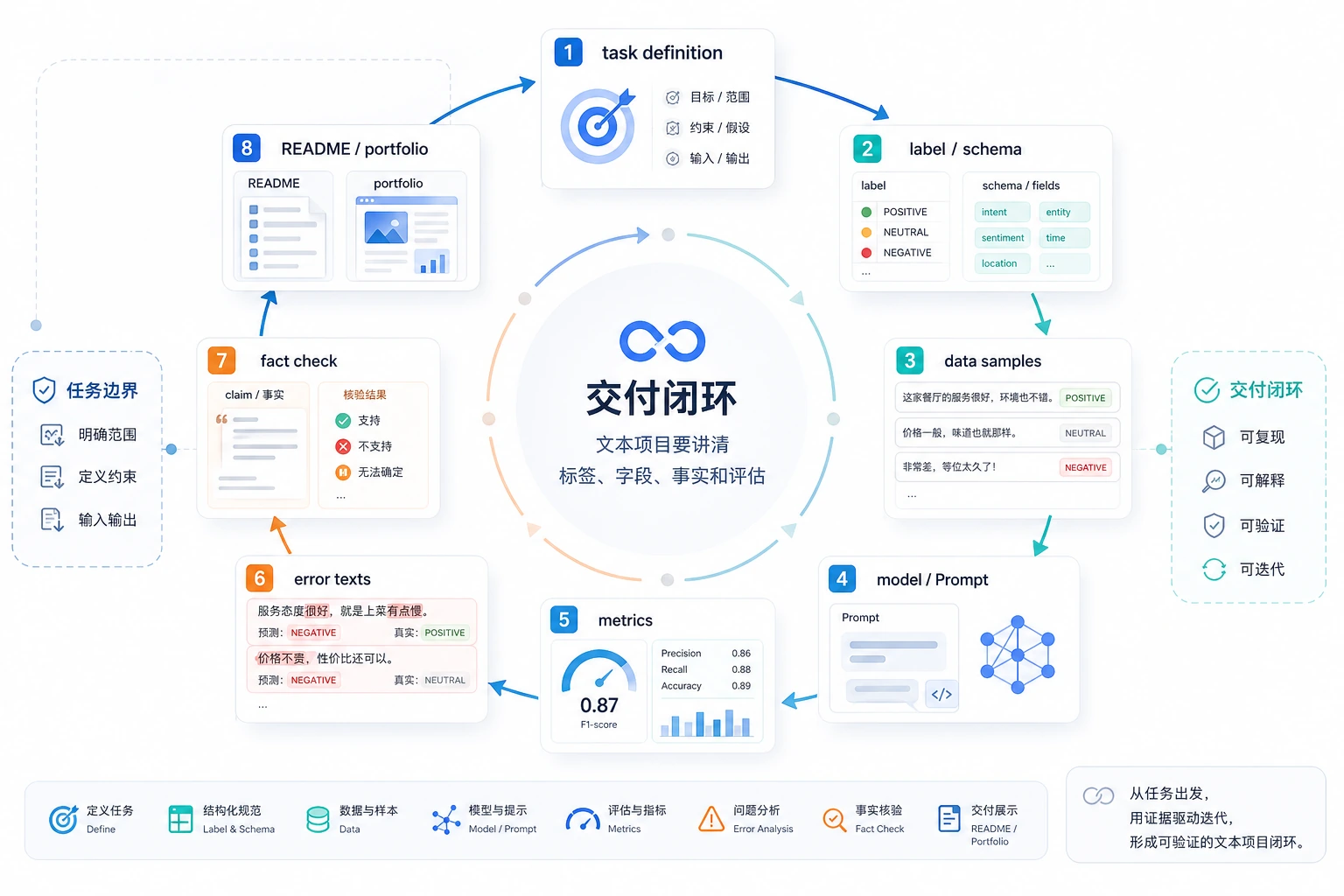
如果要清晰标签,从信息抽取或分类开始。能评估事实性、拒答、引用和边界后,再做总结和问答。
跑一个项目就绪检查
project = {
"task": "information extraction",
"has_schema": True,
"has_baseline": True,
"has_eval_cases": True,
"has_failure_case": True,
}
ready = all(project[key] for key in ["has_schema", "has_baseline", "has_eval_cases", "has_failure_case"])
print("task:", project["task"])
print("portfolio_ready:", ready)
预期输出:
task: information extraction
portfolio_ready: True
如果标签、字段或知识边界不清楚,先修任务定义,再换模型。
按这个顺序学
| 步骤 | 项目 | 证据 |
|---|---|---|
| 1 | 信息抽取 | Schema、字段边界、precision/recall、失败样例 |
| 2 | 文本分类 | 标签、baseline、F1、歧义案例 |
| 3 | 文本总结 | 压缩率、事实性、可读性、遗漏事实 |
| 4 | 问答 | 检索、引用、拒答、无答案评估 |
| 5 | 实操工作坊 | 在大项目页前先跑可复现迷你流水线 |
扩展项目前,先运行 11.7.6 实操:构建可复现 NLP 迷你流水线。
项目交付物标准
| 交付物 | 最低要求 | 更强的作品集版本 |
|---|---|---|
| README | 目标、运行命令、依赖、示例 | 增加任务边界、数据来源、方案取舍、复盘总结 |
| 标签/schema | 标签、实体边界或输出字段 | 增加正例、反例、边界例、一致性说明 |
| Baseline | 关键词、TF-IDF、规则或简单模型 | 增加模型对比和错误归因 |
| 评估 | Accuracy、recall、F1、人工评分或事实性检查 | 按标签、长度、领域、噪声类型分析 |
| 失败案例 | 至少 1 个真实失败 | 增加原因、修复动作、回归检查 |
| 展示 | 截图或短 GIF 证明能运行 | 构建清晰的文本理解项目页面 |
通过标准
如果你的 NLP 项目有任务定义、数据示例、评估指标、baseline、失败案例和下一步改进计划,就通过了本章。