11.6.1 预训练模型路线图:BERT、GPT、T5
预训练模型让 NLP 从单任务训练进入可复用基础模型:先在大规模文本上预训练,再迁移到下游任务。
先看范式地图
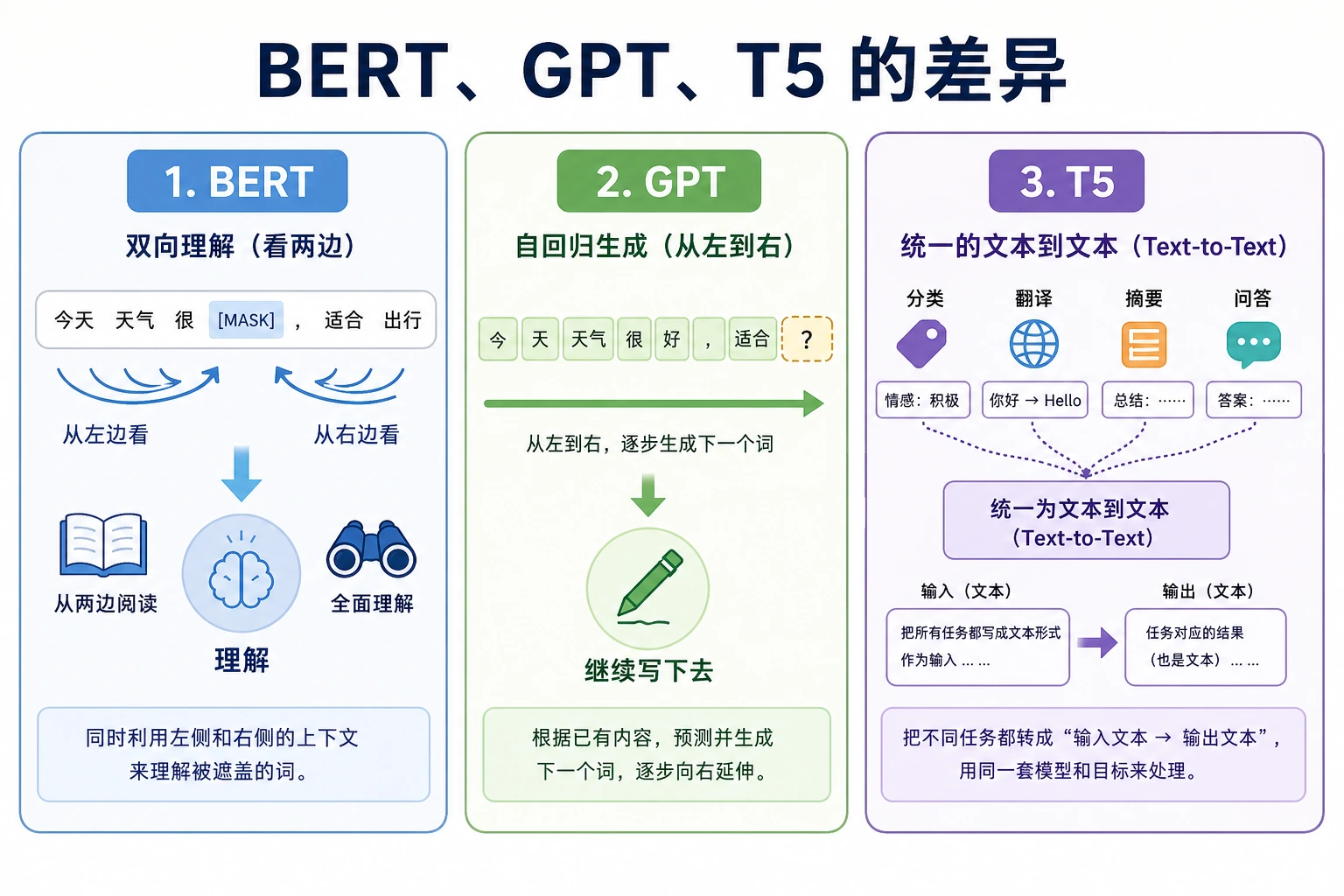
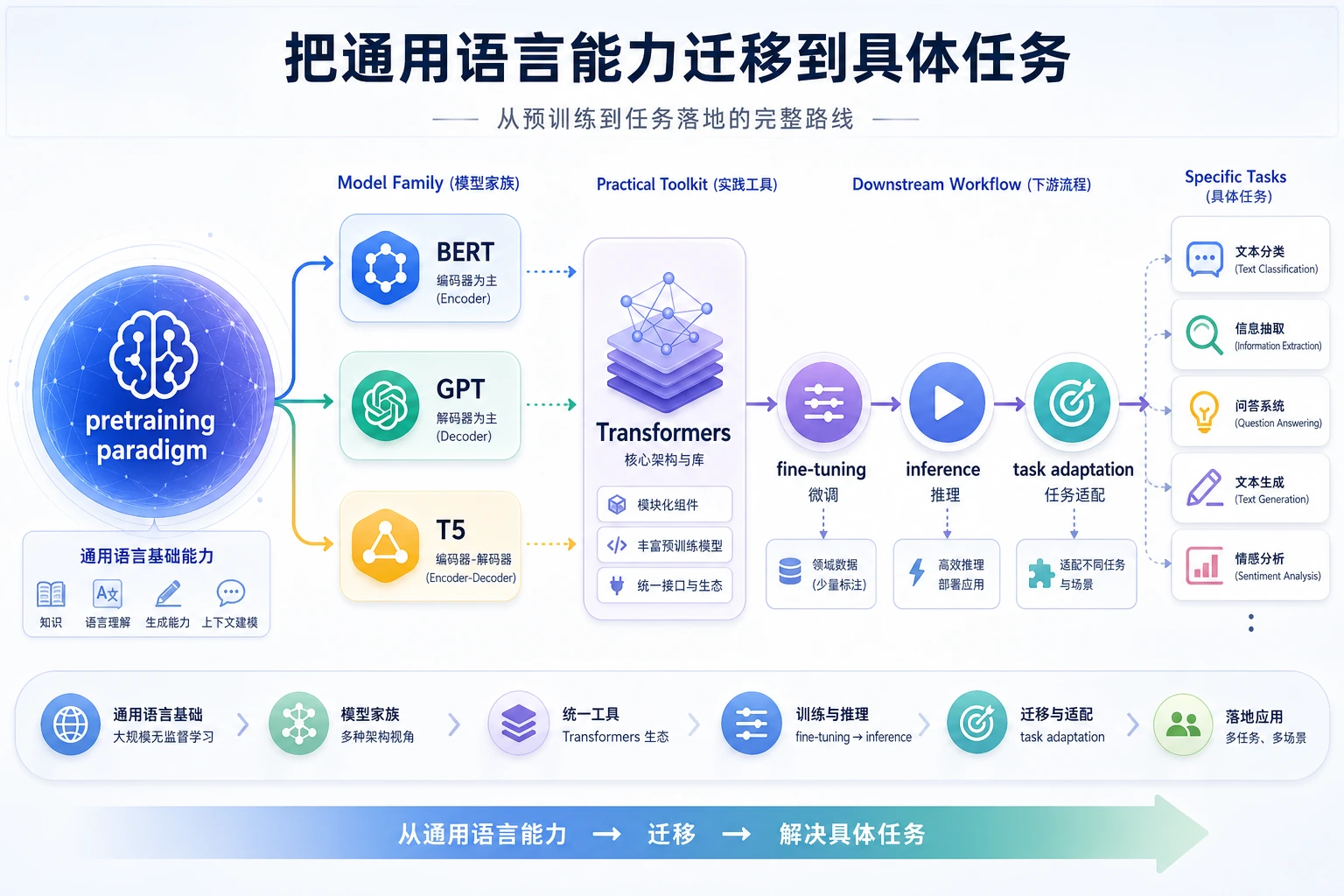

BERT 偏理解,GPT 偏生成,T5 把很多任务改写成 text-to-text。
跑一个模型家族选择检查
task = {
"needs_generation": True,
"needs_sentence_label": False,
"needs_text_to_text": True,
}
if task["needs_text_to_text"]:
family = "T5-style text-to-text"
elif task["needs_generation"]:
family = "GPT-style autoregressive"
else:
family = "BERT-style understanding"
print("family:", family)
print("reason:", "match model objective to task output")
预期输出:
family: T5-style text-to-text
reason: match model objective to task output
不要只按模型名称选择。要匹配 tokenizer、训练目标、输出格式、成本和部署约束。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 预训练范式 | 解释 pretrain → transfer → fine-tune/infer |
| 2 | BERT | 理解 mask prediction 和双向表示 |
| 3 | GPT | 理解 next-token generation 和上下文窗口 |
| 4 | T5 | 把任务改写成 text-to-text 形式 |
| 5 | Transformers 实战 | 连接 tokenizer、model、pipeline、input、output |
通过标准
如果你能解释不同训练目标为什么带来不同优势,并运行或设计一个小型预训练模型对比实验,就通过了本章。