11.4.1 序列标注路线图:每个 Token 一个标签
序列标注为每个 token 预测一个标签。NER、分词、词性标注和槽位填充都属于这个思路。
先看标签路径
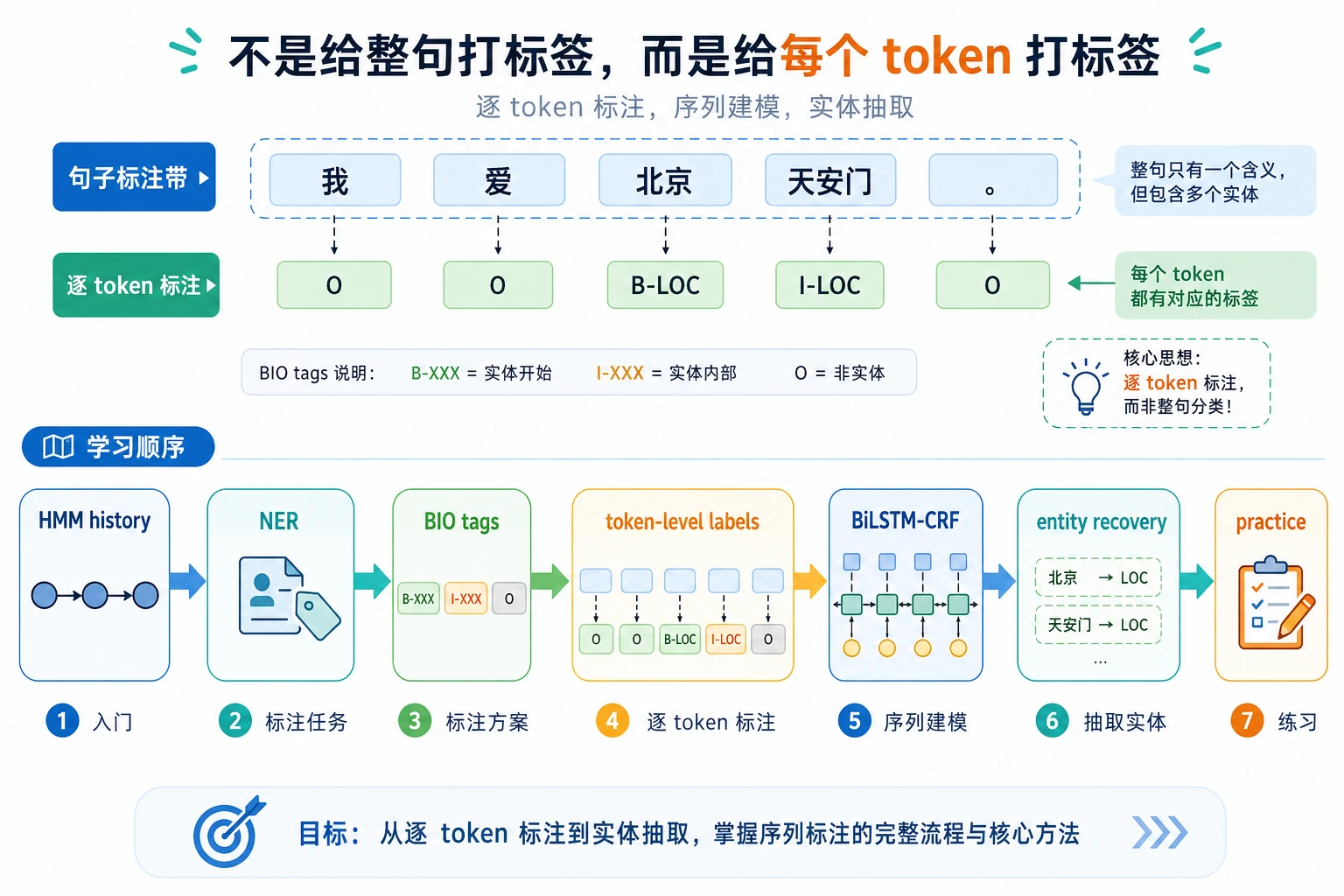
关键输出不是一个句子标签,而是对齐 token 的标签,例如 B-PER、I-PER 和 O。
跑一个 BIO 标签检查
tokens = ["Ada", "Lovelace", "wrote", "notes"]
tags = ["B-PER", "I-PER", "O", "O"]
for token, tag in zip(tokens, tags):
print(token, tag)
预期输出:
Ada B-PER
Lovelace I-PER
wrote O
notes O
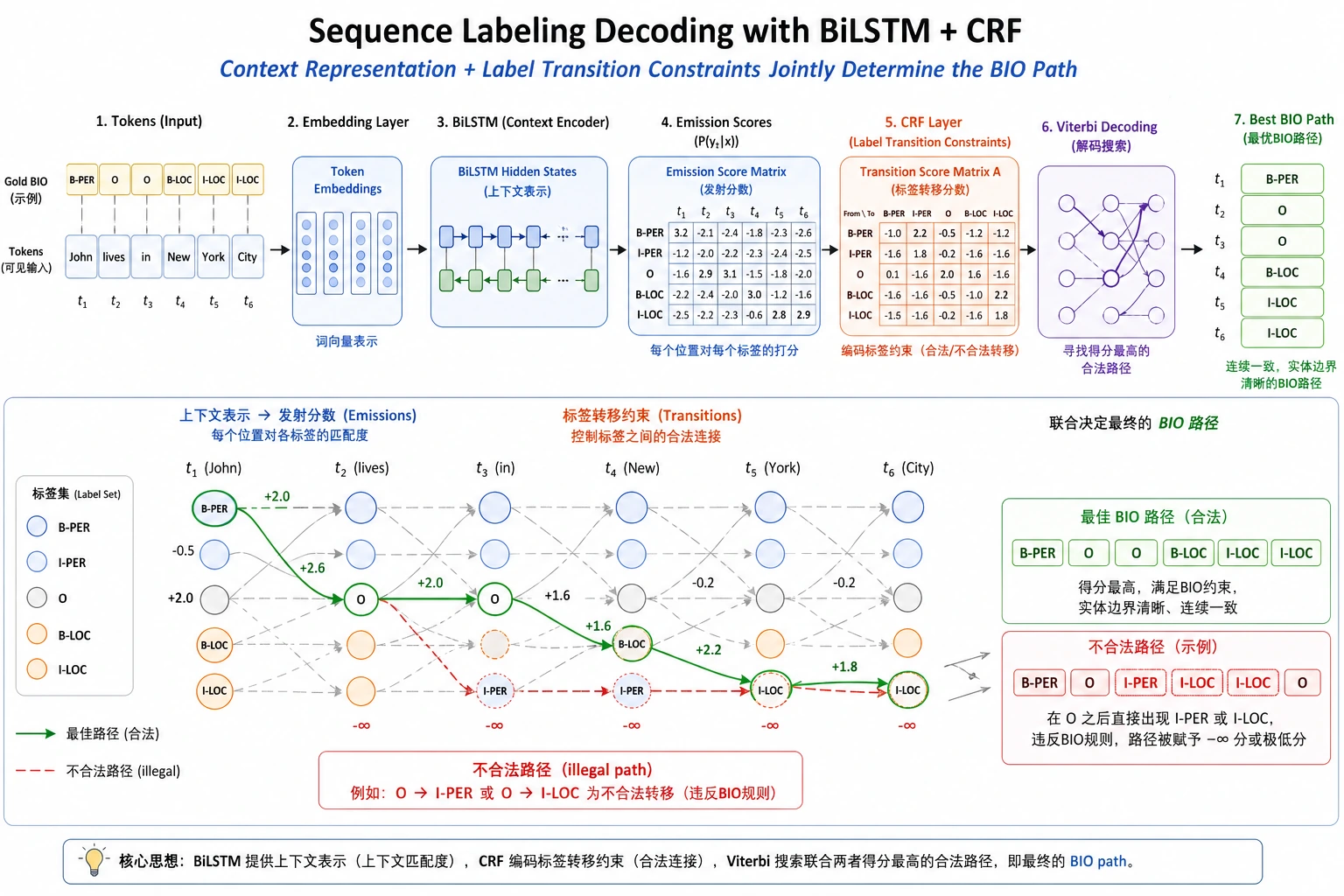
如果分词变化,标签必须仍然对齐。很多序列标注 bug 本质上是对齐 bug。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | NER 与 BIO | 创建 token 级标签和实体 span |
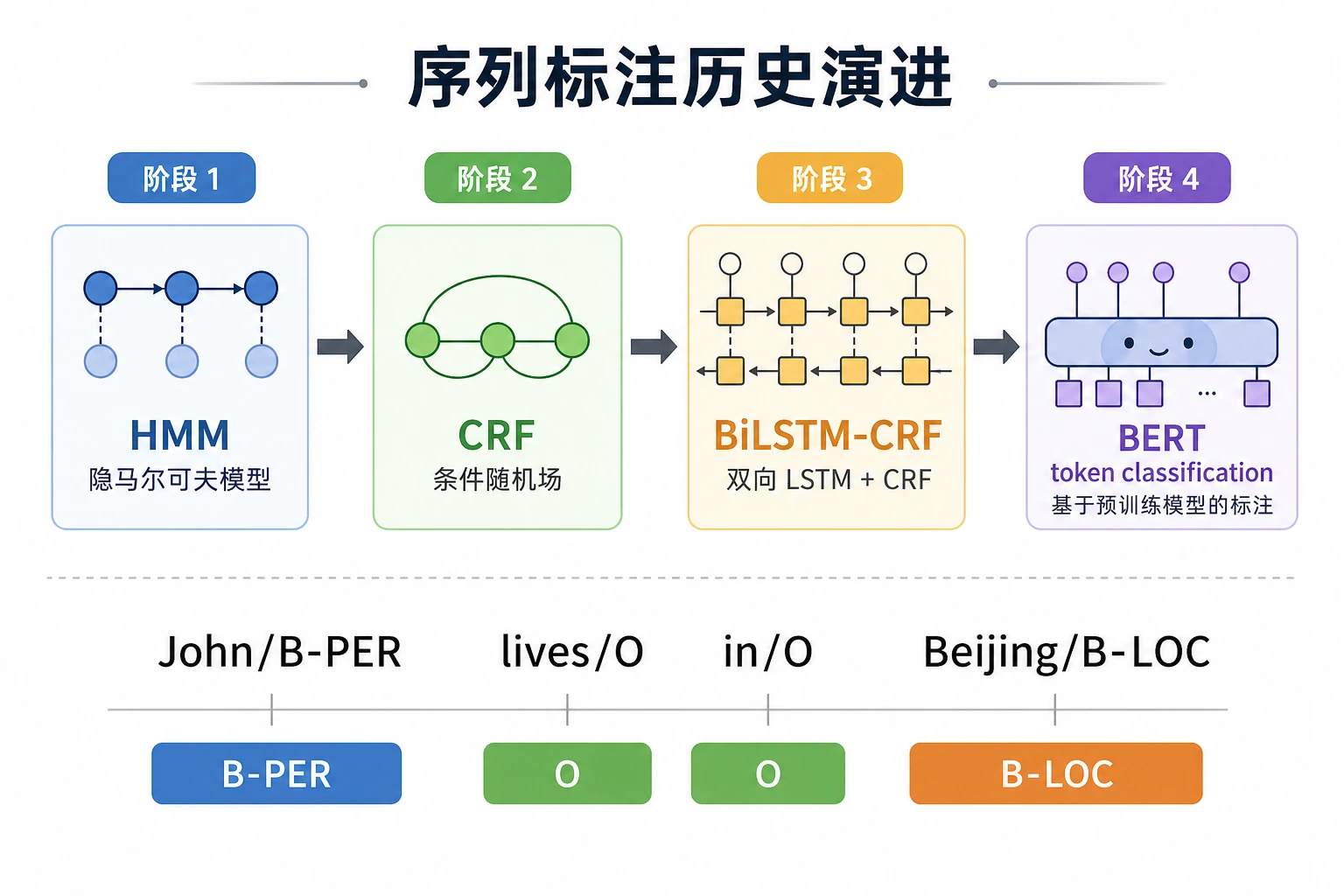
| 2 | HMM/CRF 历史 | 理解序列约束和标签转移 |
| 3 | BiLSTM-CRF | 连接上下文特征和合法标签路径 |
| 4 | 项目实战 | 评估 precision、recall、F1、边界错误 |
通过标准
如果你能检查 token/tag 对齐,并解释一个边界错误或非法标签转移,就通过了本章。