11.4.1 系列ラベリングロードマップ:Token ごとにラベルを付ける
分類は文全体に 1 つのラベルを付けます。系列ラベリングは、文の中の各 token にラベルを付けます。NER(Named Entity Recognition、固有表現認識)は代表例です。
先に全体像を見る
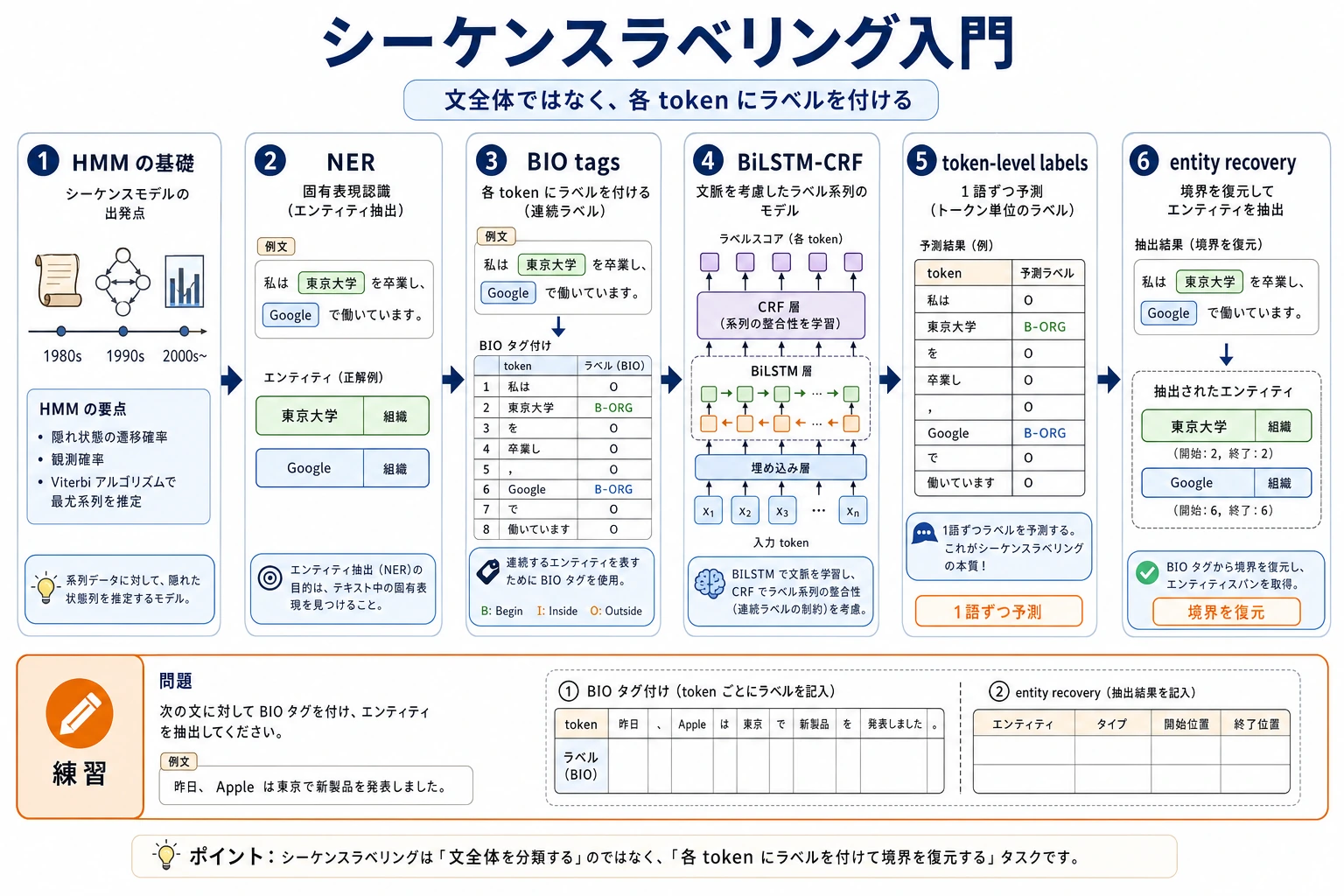
重要な出力は文全体のラベルではなく、B-PER、I-PER、O のように token ごとにそろったタグ列です。
BIO ラベルを手で見る
B-PER は人物名の開始、I-PER は人物名の続き、O は対象外を表します。まずは小さな文で、token とラベルの対応を確認します。
tokens = ["Ada", "Lovelace", "wrote", "notes"]
tags = ["B-PER", "I-PER", "O", "O"]
for token, tag in zip(tokens, tags):
print(token, tag)
期待される出力:
Ada B-PER
Lovelace I-PER
wrote O
notes O
操作のコツ:系列ラベリングでは token 数と tag 数が一致している必要があります。ここがずれると、学習データとして使えません。
学ぶ順番
| ステップ | 読む内容 | 実践で作るもの |
|---|---|---|
| 1 | NER と BIO | token 単位ラベルとエンティティ span を作る |
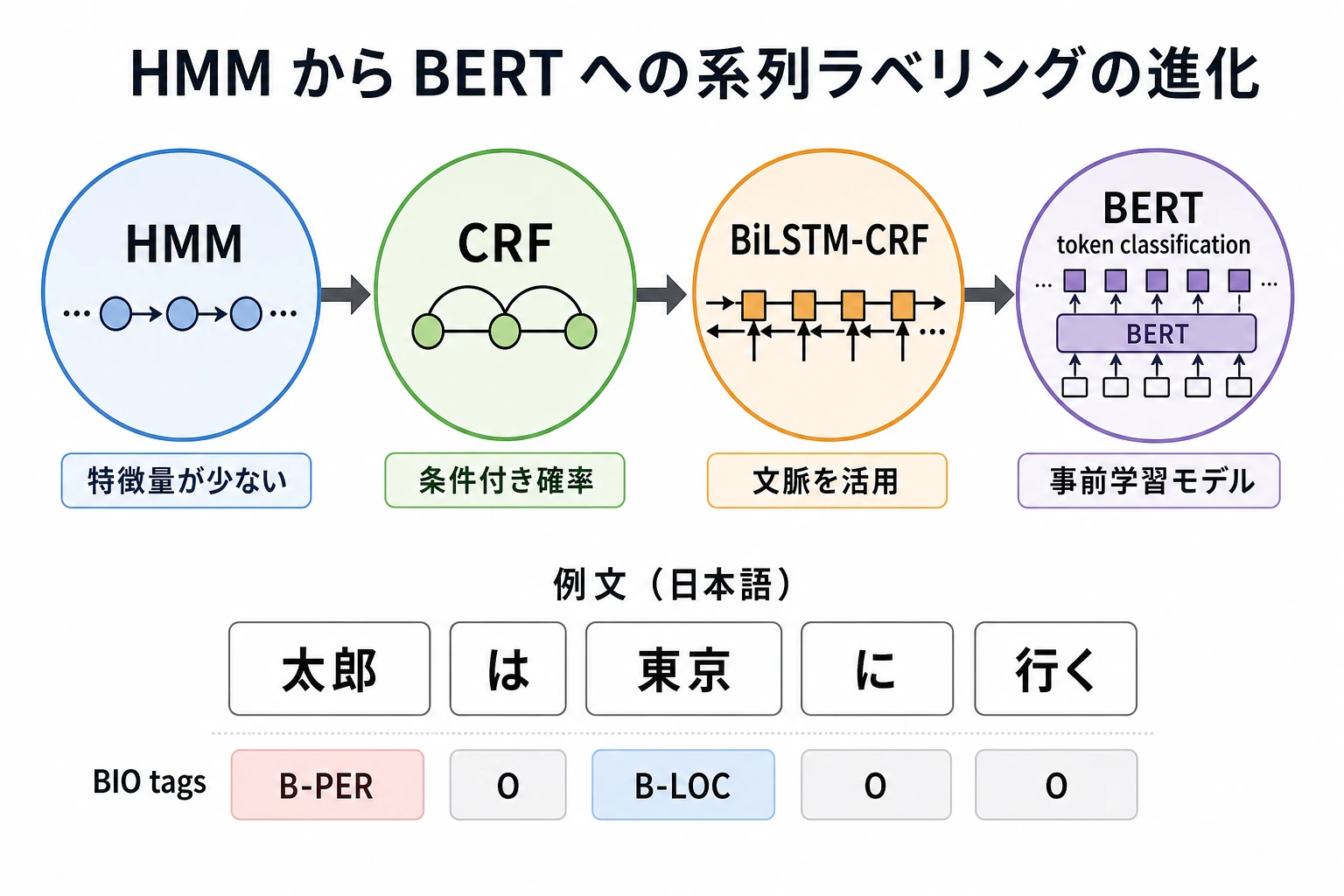
| 2 | HMM / CRF の歴史 | 系列制約とラベル遷移を理解する |
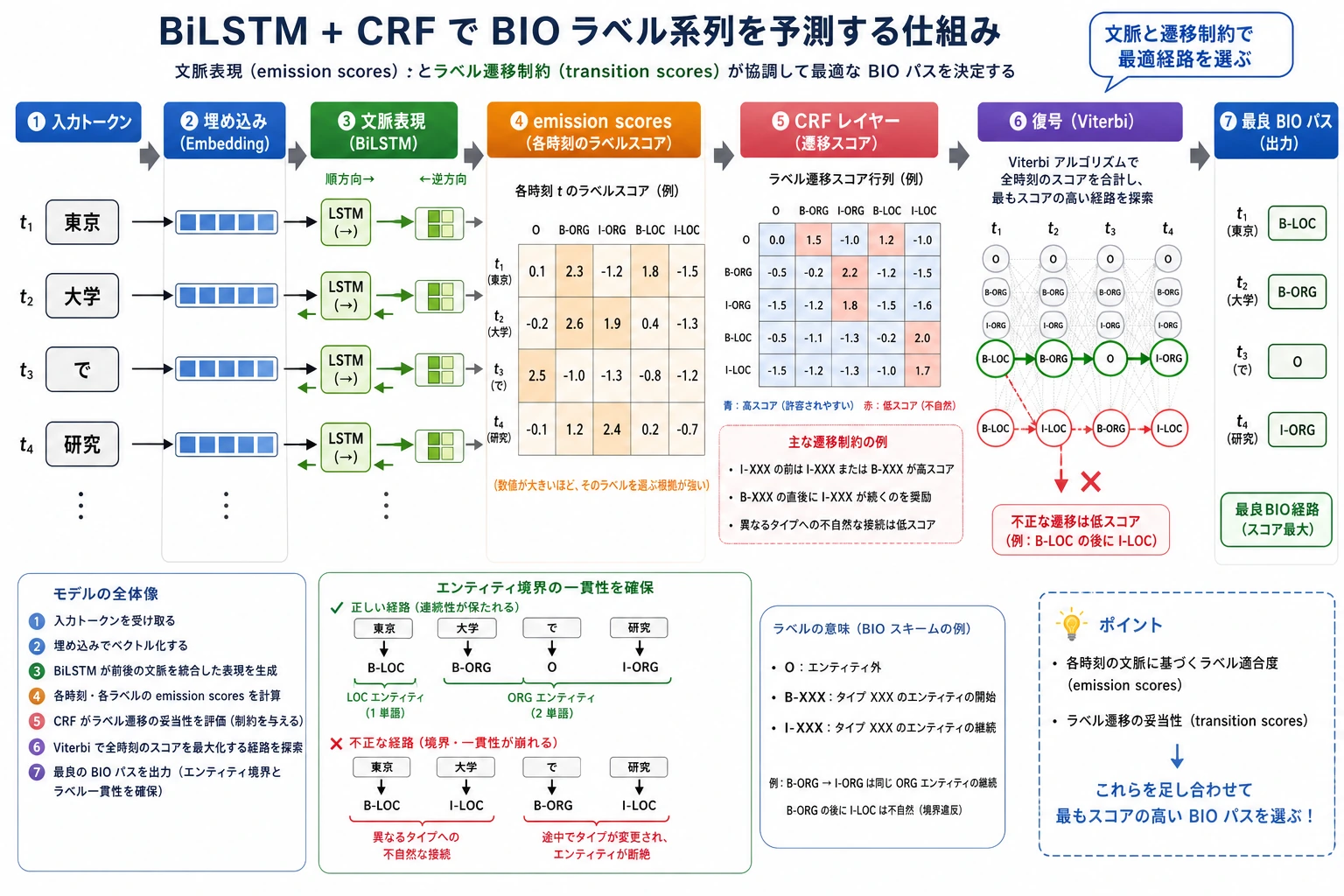
| 3 | BiLSTM-CRF | 文脈特徴と正しいラベル経路をつなげる |
| 4 | プロジェクト実践 | precision、recall、F1、境界エラーを評価する |
通過条件
token/tag の対応を確認でき、境界ミスまたは不正なタグ遷移を1つ説明できれば、この章は通過です。