11.3.4 テキスト分類実践
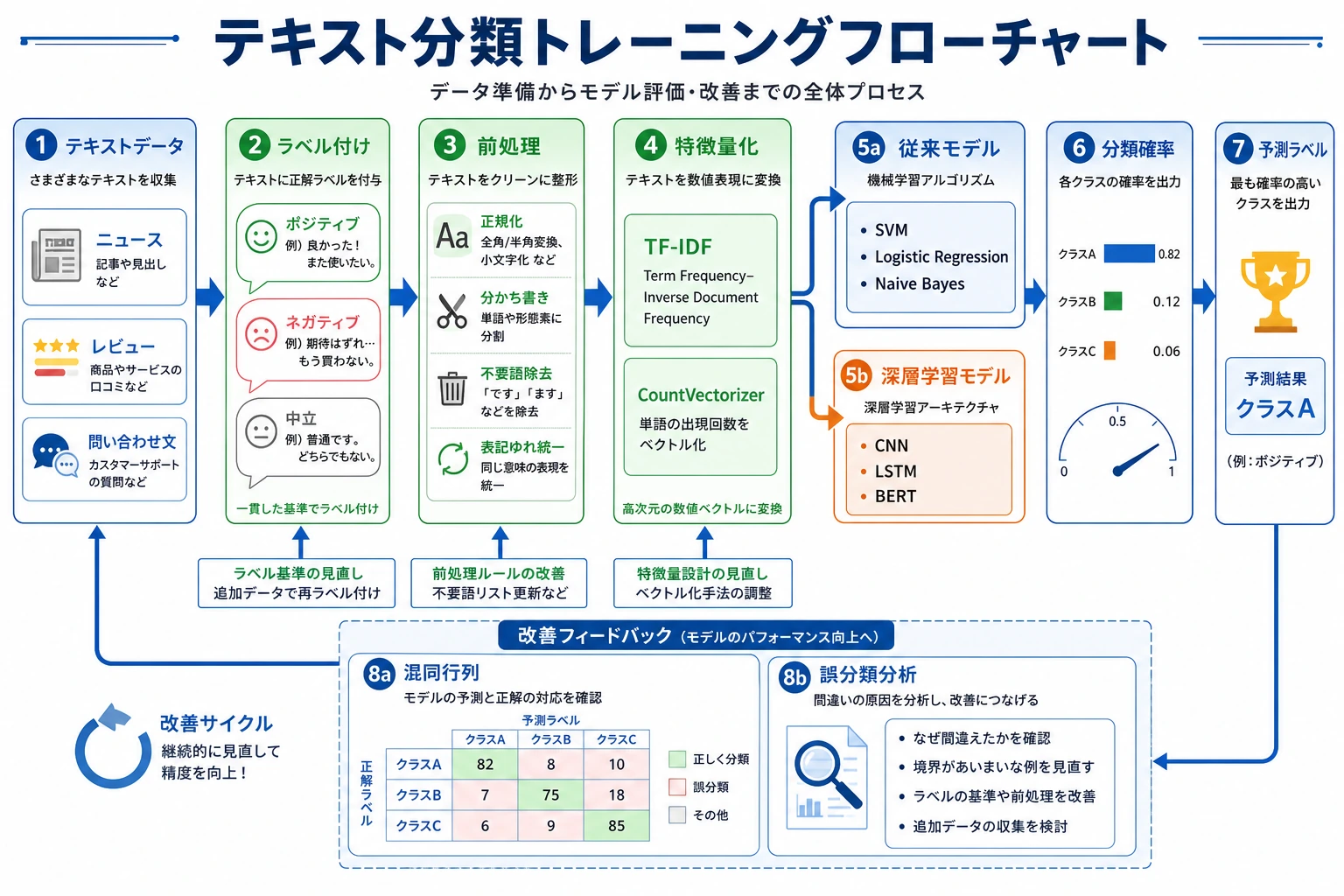
前の2節では、それぞれ次の内容を学びました。
- 伝統的なテキスト分類
- 深層学習によるテキスト分類
この節では、それらを実際のプロジェクトに戻して考えます。
本当のテキスト分類プロジェクトでは、難しさはモデルだけではなく、次の点にもあります。
- ラベルをどう決めるか
- データをどう作るか
- ベースラインをどう比較するか
- エラーをどう分析するか
このレッスンでは、小さなカスタマーサポートの意図分類タスクを題材に、この一連の流れを体験します。
学習目標
- テキスト分類タスクのラベル境界をはっきり定義できるようになる
- 結果を説明できる軽量なベースラインを作れるようになる
- エラーケースからデータやラベルの問題を見つけられるようになる
- 実行可能なサンプルを通して、プロジェクトの全体構成をつかむ
一、まずプロジェクトの問題をはっきり定義する
シナリオ
ここでは、最小構成のカスタマーサポート問い合わせ意図分類器を作ります。対象カテゴリは次の3つです。
refundinvoicepassword
なぜこの題材が練習に向いているのか?
理由は、次の条件をすべて満たしているからです。
- 入力が明確:ユーザーの一文
- 出力が明確:意図カテゴリ
- エラー分析がしやすい:分類ミスの原因を、単語やラベル境界までたどりやすい
最初の重要ポイントはモデルではなく、ラベル境界
たとえば、次のように考えます。
- 「返金はいつ入金されますか」 は
refund - 「請求書はいつ発行できますか」 は
invoice - 「パスワードを忘れた場合はどうすればよいですか」 は
password
この定義を、最初にきちんと決めておく必要があります。
二、まずは説明しやすいベースラインを作る
ここでは外部依存を使わず、
最小構成のキーワード統計ベースラインをそのまま書いて、まず全体の流れを見えるようにします。
from collections import Counter, defaultdict
train_data = [
("返金はいつ入金されますか", "refund"),
("返金はどう申請しますか", "refund"),
("請求書はいつ発行できますか", "invoice"),
("電子請求書はどこに送られますか", "invoice"),
("パスワードを忘れた場合はどうすればよいですか", "password"),
("パスワード再設定の入口はどこですか", "password"),
]
test_data = [
("返金はどう処理されますか", "refund"),
("電子請求書はいつ発行されますか", "invoice"),
("パスワード再設定にはどれくらいかかりますか", "password"),
("返金の請求書はどう発行しますか", "invoice"),
]
def tokenize(text):
return list(text)
class KeywordClassifier:
def __init__(self):
self.class_word_counts = defaultdict(Counter)
self.class_counts = Counter()
def fit(self, data):
for text, label in data:
self.class_counts[label] += 1
self.class_word_counts[label].update(tokenize(text))
def predict_one(self, text):
tokens = tokenize(text)
scores = {}
for label, word_counts in self.class_word_counts.items():
score = 0
for token in tokens:
score += word_counts[token]
scores[label] = score
return max(scores, key=scores.get), scores
def evaluate(self, data):
correct = 0
details = []
for text, gold in data:
pred, scores = self.predict_one(text)
correct += int(pred == gold)
details.append({"text": text, "gold": gold, "pred": pred, "scores": scores})
return correct / len(data), details
clf = KeywordClassifier()
clf.fit(train_data)
acc, details = clf.evaluate(test_data)
print("accuracy:", round(acc, 4))
for item in details:
print(item)
実行結果の例:
accuracy: 0.75
{'text': '返金はどう処理されますか', 'gold': 'refund', 'pred': 'refund', 'scores': {'refund': 17, 'invoice': 10, 'password': 12}}
{'text': '電子請求書はいつ発行されますか', 'gold': 'invoice', 'pred': 'invoice', 'scores': {'refund': 13, 'invoice': 21, 'password': 10}}
{'text': 'パスワード再設定にはどれくらいかかりますか', 'gold': 'password', 'pred': 'password', 'scores': {'refund': 15, 'invoice': 17, 'password': 29}}
{'text': '返金の請求書はどう発行しますか', 'gold': 'invoice', 'pred': 'refund', 'scores': {'refund': 17, 'invoice': 17, 'password': 11}}

最後のサンプルは、あえて曖昧にしています。返金 と 請求書 の手がかりが同時に出るため、単純な baseline では同点になり、先に登録された refund が選ばれます。
この例に価値がある理由
このコードには、分類プロジェクトの最も重要な4つの要素が入っています。
- 学習データ
- テストデータ
- 実行可能なベースライン
- 詳細な出力
なぜ、あえて「とてもシンプルな」ベースラインから始めるのか?
その方が、次のことがわかりやすいからです。
- 予測がなぜそうなったのか理解しやすい
- データの問題を見つけやすい
- より強いモデルが、ベースラインより何を改善したのか把握しやすい
三、テキスト分類プロジェクトで最も価値があるのは、総合スコアではなくエラー分析
まずは全体の正解率を見る
正解率を見ると、次のことがわかります。
- このバージョンのシステムがおおよそ使えるかどうか
でも、本当に洞察があるのは1件ずつの詳細
次の点を確認する必要があります。
- どの種類のサンプルが間違いやすいか
- 単語の見た目が似ているのか、ラベルが重なっているのか、それとも学習データが足りないのか
かんたんなエラー分析関数
details = [
{"text": "返金はどう処理されますか", "gold": "refund", "pred": "refund", "scores": {"refund": 17, "invoice": 10, "password": 12}},
{"text": "電子請求書はいつ発行されますか", "gold": "invoice", "pred": "invoice", "scores": {"refund": 13, "invoice": 21, "password": 10}},
{"text": "パスワード再設定にはどれくらいかかりますか", "gold": "password", "pred": "password", "scores": {"refund": 15, "invoice": 17, "password": 29}},
{"text": "返金の請求書はどう発行しますか", "gold": "invoice", "pred": "refund", "scores": {"refund": 17, "invoice": 17, "password": 11}},
]
def error_cases(details):
return [item for item in details if item["gold"] != item["pred"]]
errors = error_cases(details)
print("errors:", errors)
実行結果の例:
errors: [{'text': '返金の請求書はどう発行しますか', 'gold': 'invoice', 'pred': 'refund', 'scores': {'refund': 17, 'invoice': 17, 'password': 11}}]
このエラーから、モデルを強くする前に「返金に関係する請求書」を請求書ラベルに入れるのか、返金ラベルに入れるのか、あるいは混合意図として分けるのかを確認できます。
エラーが多いなら、まず次のように考えてみてください。
- カテゴリの境界があいまいではないか
- 学習サンプルの偏りが大きくないか
- キーワードベースラインの限界ではないか
四、いつ伝統的な手法から深層学習へ進むべきか?
エラーの主な原因が、意味表現の違いにあるとき
たとえば、次のような場合です。
- 学習時によく出るキーワードが含まれていない
- でも意味としては同じカテゴリ
Bag-of-Words 特徴では足りなくなったとき
たとえば、次のような場面です。
- 文が長くなる
- 否定や文脈の影響が大きくなる
- カテゴリ境界がより微妙になる
ただし、アップグレードの前にベースラインは残す
ベースラインはとても重要です。なぜなら、次の問いに答える助けになるからです。
- 深層学習モデルは何をどれだけ改善したのか
五、プロジェクトの一連の流れはどう説明すればよいか?
タスク定義
まず、次の点をはっきり説明します。
- 入力は何か
- 出力は何か
- ラベルをどう決めたか
ベースライン
次の点を説明します。
- どんな最小手法を使ったか
- なぜそれを選んだか
評価とエラー分析
少なくとも、次の内容を示します。
- 正解率
- 典型的な成功例をいくつか
- 典型的な失敗例をいくつか
次に改善する方向
たとえば、次のような方向です。
- データを増やす
- TF-IDF + 線形モデルを導入する
- さらに embedding / 深層学習モデルへ進む
六、よくある落とし穴
落とし穴1:最初から最も複雑なモデルを使う
これだと、タスクそのものの理解があいまいになりやすいです。
落とし穴2:全体の正解率だけを見る
エラーの詳細を見ないと、本当の改善はしにくくなります。
落とし穴3:ラベル定義があいまい
ラベルがあいまいだと、どんなに強いモデルでも安定して学習しにくくなります。
まとめ
この節で最も大切なのは、プロジェクトの習慣を身につけることです。
テキスト分類プロジェクトでは、最初にラベル境界、説明可能なベースライン、エラー分析をしっかり作ることが重要で、いきなり最も複雑なモデルを目指すべきではありません。
この習慣が身につけば、あとでより複雑な NLP プロジェクトに進んでも、ずっと安定して進められます。
練習
- サンプルに
shippingという新しいカテゴリを追加して、学習サンプルも数件増やしてください。 - エラーの詳細を見て、どの予測が混同しやすいか確認し、その理由を考えてみてください。
- このキーワードベースラインから深層学習モデルへ切り替えるのは、どんな場合だと思いますか?
- ラベル定義そのものがあいまいな場合、まずモデルを直しますか、それともデータを直しますか? なぜですか?