11.3.3 深層学習によるテキスト分類
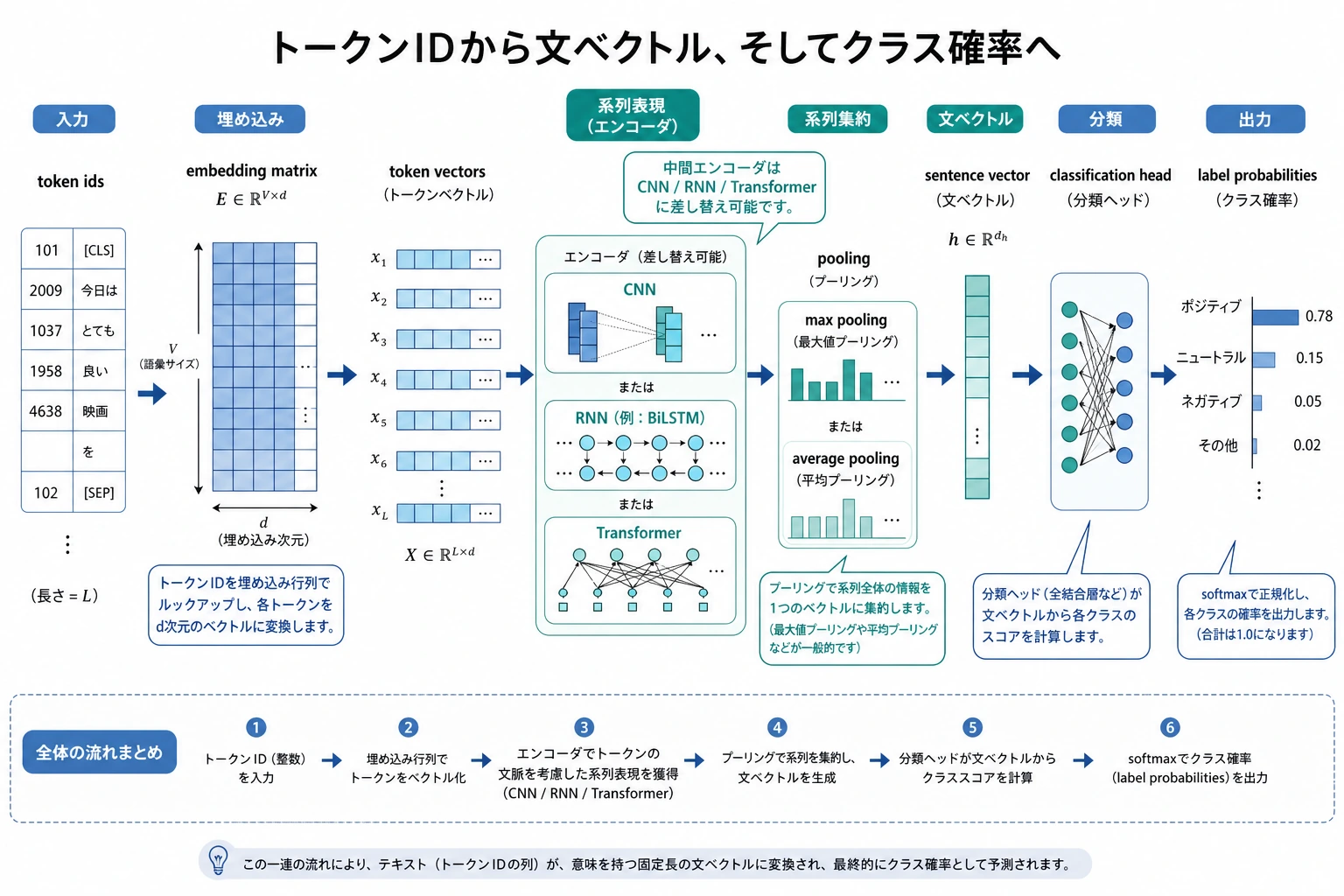
深層テキスト分類は、まずとてもシンプルな流れとして考えられます。token id が embedding に入り、文は pooling を通して全体ベクトルになり、最後に分類ヘッドへ渡されて確率を出します。まずこの主線をつかんでから、CNN、RNN、Transformer を見るとずっと理解しやすくなります。
従来のテキスト分類でも多くの問題は解決できます。
しかし、タスクが次のような要素に依存し始めると:
- 意味的に近い表現
- 多義語
- 文脈情報
従来の特徴量ベースの方法では、少し苦しくなってきます。
そのとき、深層学習によるテキスト分類の価値が見えてきます。
明示的な単語頻度だけを見るのではなく、より連続的で抽象的なテキスト表現を学習できる。
学習目標
- 深層学習によるテキスト分類と従来手法の本質的な違いを理解する
- embedding、pooling、分類ヘッドという最小の深層分類の流れを理解する
- 実行可能な例を通して「ニューラルテキスト分類器」の最初の直感をつかむ
- 表現学習がなぜ分類性能の上限を変えるのかを理解する
まずは全体地図を作ろう
深層学習によるテキスト分類は、「入力がどう流れるか」で考えると理解しやすいです。
この節で本当に解きたいのは、次の2点です。
- ニューラルテキスト分類器は、従来手法よりどんな能力を1段多く持っているのか
- なぜ「先に表現を学習してから分類する」ことで、性能の上限が変わるのか
一、深層学習によるテキスト分類は、従来手法より何が増えるのか?
手作業の特徴量だけに頼らない
従来手法は、だいたい次のような流れです。
- まず人が手でテキスト特徴を定義する
- それから分類器を学習する
深層学習では、だいたい次のようになります。
- 表現を学びながら
- 同時に分類も学ぶ
最小構成は意外とシンプル
最小の深層テキスト分類器は、通常次の3つに分けられます。
- token -> embedding
- 一連の token 表現を集約する
- 線形分類ヘッドにつなぐ
たとえで理解する
従来手法は、文をまずキーワードの表に分解してから判断するイメージです。
深層学習は、文をまず連続した意味表現に変換してから判断するイメージです。
初学者向けの、よりわかりやすい比喩
2つの方法は、こんなふうにも考えられます。
- 従来手法は、チェック項目に印をつけていく感じ
- 深層学習は、まず話の内容をざっくり理解してから結論を出す感じ
前者は次のような点に強く依存します。
- どんな特徴を見るかを事前に設計していること
後者は次のような点を重視します。
- モデルが、どの表現同士が近いかを自分で学べること
二、最も基本的なニューラルテキスト分類器はどんな形か?
Embedding 層
token id をベクトルに変えます。
Pooling
一連の token 表現を1つの文表現にまとめます。
いちばん簡単なのは:
- 平均プーリング
分類ヘッド
線形層を使って、文表現をクラススコアに変換します。
この構造はとてもシンプルですが、
それでも純粋な bag-of-words より、連続表現を活かしやすいです。
三、まずは純 Python のニューラルテキスト分類器の前向き計算を動かしてみよう
このコードはパラメータを学習しません。
ただし、次の流れを一通り示します。
- token id -> embedding
- pooling
- 線形スコア計算
これで、「ニューラルテキスト分類器」の最小骨格が本当に見えてきます。
vocab = {
"返金": 0,
"請求書": 1,
"パスワード": 2,
"申請": 3,
"発行": 4,
"再設定": 5,
}
embedding_table = {
0: [0.9, 0.8, 0.1],
1: [0.2, 0.9, 0.1],
2: [0.1, 0.2, 0.95],
3: [0.8, 0.7, 0.2],
4: [0.2, 0.85, 0.15],
5: [0.1, 0.25, 0.9],
}
classifier_weights = {
"refund": [1.0, 0.6, 0.1],
"invoice": [0.2, 1.0, 0.1],
"password": [0.1, 0.1, 1.0],
}
def encode(tokens):
return [vocab[token] for token in tokens if token in vocab]
def mean_pool(vectors):
dim = len(vectors[0])
return [sum(vec[i] for vec in vectors) / len(vectors) for i in range(dim)]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
tokens = ["返金", "申請"]
token_ids = encode(tokens)
token_vectors = [embedding_table[token_id] for token_id in token_ids]
sentence_vector = mean_pool(token_vectors)
scores = {
label: round(dot(sentence_vector, weight), 4)
for label, weight in classifier_weights.items()
}
prediction = max(scores, key=scores.get)
print("token_ids:", token_ids)
print("sentence_vector:", [round(x, 4) for x in sentence_vector])
print("scores:", scores)
print("prediction:", prediction)
実行結果の例:
token_ids: [0, 3]
sentence_vector: [0.85, 0.75, 0.15]
scores: {'refund': 1.315, 'invoice': 0.935, 'password': 0.31}
prediction: refund
順番に見ると、token が ID になり、ID から埋め込みベクトルを取り出し、複数の token ベクトルを平均して文ベクトルにし、最後に分類ヘッドが refund に最も高いスコアを付けています。
この例が、単に nn.Sequential より役立つ理由
この例では、3つの重要なステップが分かれて見えます。
- embedding
- pooling
- classification
これによって、まず構造を理解してから、より複雑なフレームワーク実装を見ることができます。
なぜ pooling がそれほど重要なのか?
分類では、最終的にたいてい文レベルの表現が必要になります。
pooling がなければ、token ベクトルが並んでいるだけなので、そのまま分類ヘッドにつなぐのは難しいです。
もう1つ、最小の「同じ意味の表現は近づきやすい」例
sentences = {
"返金申請": [0.85, 0.75, 0.15],
"返品処理": [0.82, 0.72, 0.18],
"パスワード再設定": [0.12, 0.15, 0.92],
}
def l1_distance(a, b):
return round(sum(abs(x - y) for x, y in zip(a, b)), 4)
print("返金申請 vs 返品処理:", l1_distance(sentences["返金申請"], sentences["返品処理"]))
print("返金申請 vs パスワード再設定:", l1_distance(sentences["返金申請"], sentences["パスワード再設定"]))
実行結果の例:
返金申請 vs 返品処理: 0.09
返金申請 vs パスワード再設定: 2.1
距離が小さいほど、2つの文表現は近いと読めます。このおもちゃの例では、返金申請 と 返品処理 が近く、ニューラル分類器がデータから学びたい幾何関係を簡略化して見せています。
これは初学者にとても向いています。なぜなら、次の感覚を直感的につかみやすいからです。
- 文表現がうまく学習できていれば
- 同じような意味の表現は、より近くなりやすい
四、なぜ深層学習のほうが、従来手法より強くなりやすいのか?
連続した意味関係を使える
「返金申請」と「返品処理」のように、見た目の単語は違っても意味が近い場合、
embedding はそれらを近づけやすいです。
文脈をより自然に扱える
たとえ単純なモデルでも、純粋な bag-of-words よりは、表現学習の流れに近づきます。
その先に、さらに強い構造を積み上げられる
後から次のような構造を追加できます。
- CNN
- RNN
- Transformer
これが、深層分類と従来分類の拡張性の違いです。
五、どんなときに深層テキスト分類を使うと特に価値があるか?
表現のバリエーションが多いとき
同じ意図に対して、いろいろな言い回しがある場合、
深層学習のほうが有利になりやすいです。
明示的なキーワードより意味が重要なとき
キーワードだけでは判定しにくいなら、
深い表現を使う価値があります。
より高い学習コストを受け入れられるとき
従来手法と比べると、深層学習では通常、次のものが必要になります。
- より多くの学習リソース
- より複雑なデバッグ
初めてテキスト分類プロジェクトを作るときの、いちばん堅い順番
おすすめの順番は、だいたい次の通りです。
- まず従来の baseline を作る
- 次に最小の embedding + pooling モデルを試す
- まずは誤分類例が減るか、より安定するかを見る
- 最後に、より強い構造や事前学習モデルを検討する
こうすると、最初から複雑なネットワークを追うより、
どこに効果があるのかが見えやすくなります。
六、よくある誤解
誤解1:深層学習は必ず従来手法より全面的に優れている
そうとは限りません。
データが少ない、文が短い、ルールがはっきりしているタスクでは、従来手法のほうが十分に良いことがあります。
誤解2:embedding があれば自動的に文脈を理解できる
最小の embedding + pooling 構造は、bag-of-words より強いです。
しかし、それがそのまま最強の文脈理解になるわけではありません。
誤解3:モデル構造だけを見て、データを見ない
データ品質とラベル定義は、今でも非常に重要です。
これをプロジェクトとして作るなら、何を見せるとよいか
見せる価値が高いのは、単に次のように言うことではありません。
- 「深層学習モデルを使いました」
それよりも、次のような点を見せるほうが有益です。
- 従来 baseline と深層 baseline の比較
- テキストがどのように文ベクトルになるか
- どんな表現が深層モデルでより正しく判定されやすいか
- 失敗サンプルに、まだどんな問題が残っているか
そうすると、相手にも次のことが伝わりやすくなります。
- あなたが理解しているのは「表現学習がなぜ有効か」
- 単にモデル名を変えただけではない
まとめ
この節でいちばん大事なのは、深層学習によるテキスト分類を次のように理解することです。
まずテキストの連続表現を学習し、その上で分類する。だから従来の bag-of-words 手法より、意味の近い表現、表現の多様性、より複雑な文脈を扱うのに向いている。
この直感ができれば、次に BERT による分類や、より大きな事前学習モデルを学ぶときも、かなりスムーズになります。
練習
- 例の
tokensを["請求書", "発行"]に変えて、分類結果がどう変わるか見てみましょう。 - なぜ pooling が、token 表現から文分類へ進むための重要な一歩なのかを説明してください。
- 自分の言葉で説明してみましょう。深層分類手法が従来の bag-of-words 手法より持っている、中心的な能力は何でしょうか。
- どんなタスクなら、いきなり深層モデルではなく、まず従来の baseline を試したほうがよいでしょうか。