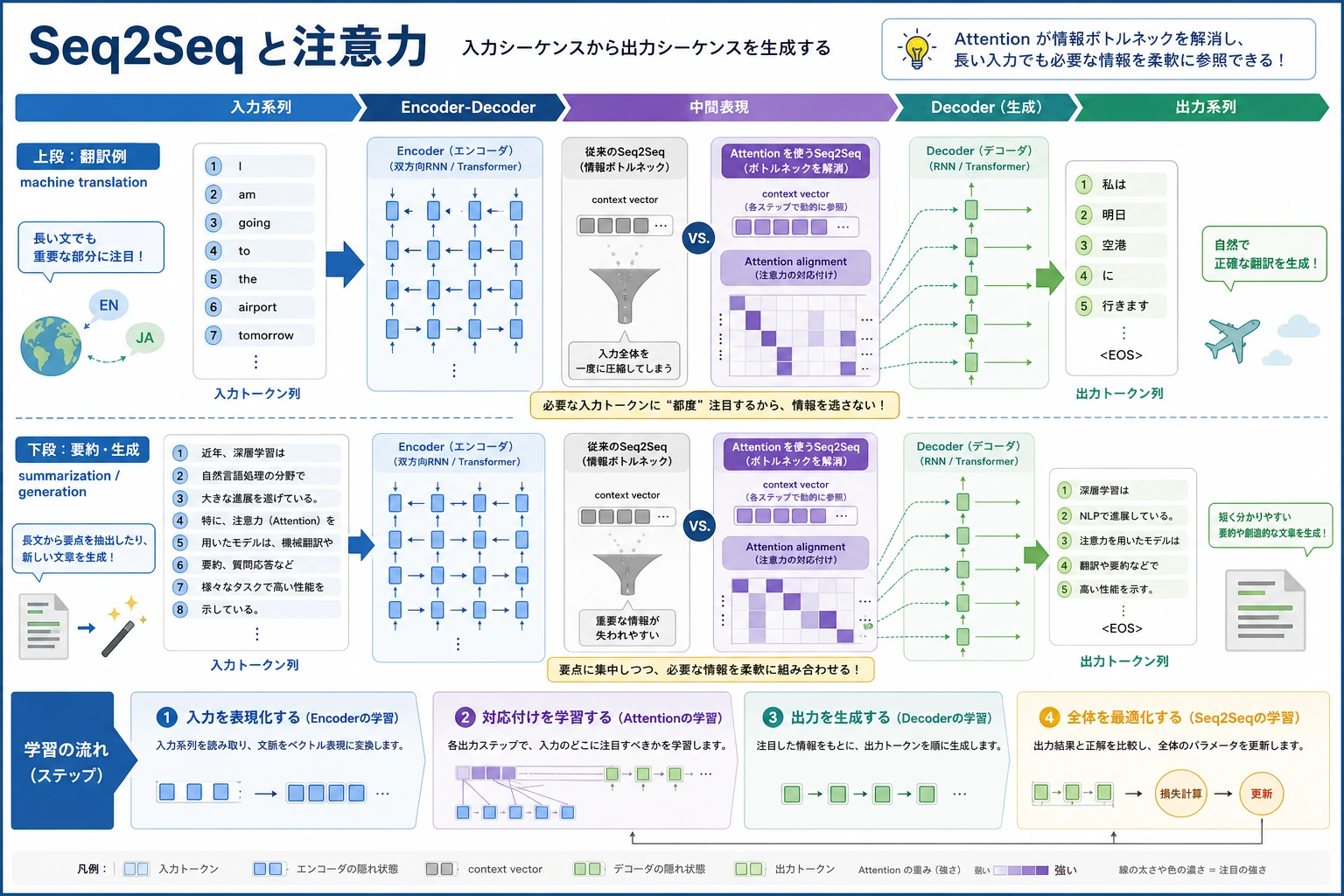
11.5.1 Seq2Seq ロードマップ:入力系列から出力系列へ
Seq2Seq は、token の列を受け取り、別の token の列を返す考え方です。翻訳、要約、言い換え、質問応答生成はこの形で理解できます。
先に全体像を見る
| 順番 | 学ぶこと | 目的 |
|---|---|---|
| 1 | Encoder-Decoder | 入力列を読み、出力列を生成する |
| 2 | Attention | 出力時に入力の重要な位置を見直す |
| 3 | デコード | 1 token ずつ出力を作る |
生成は 1 token ずつ進む
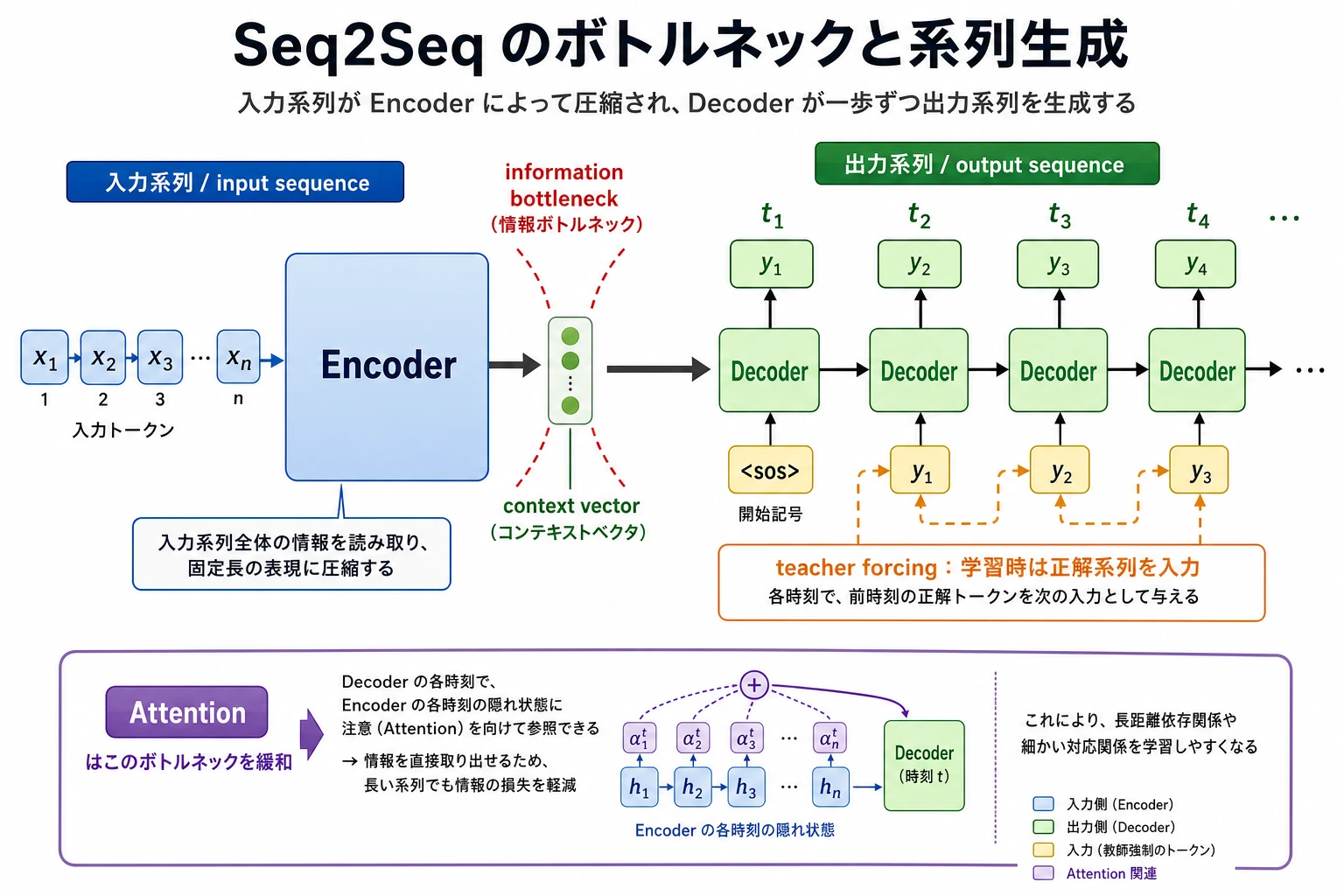
分類ではラベルを 1 つ出しました。Seq2Seq では、出力 token を順番に作ります。次のコードで、デコードの最小イメージを確認します。
source = ["I", "love", "NLP"]
target = ["J'aime", "le", "NLP"]
for step, token in enumerate(target, start=1):
print(f"decode_step_{step}:", token)
print("source_length:", len(source))
print("target_length:", len(target))
期待される出力:
decode_step_1: J'aime
decode_step_2: le
decode_step_3: NLP
source_length: 3
target_length: 3
操作のコツ:実際のモデルは、前に生成した token と入力文脈を使って次の token を予測します。ここでは順番に出る感覚だけを確認します。
T5 へのつながり
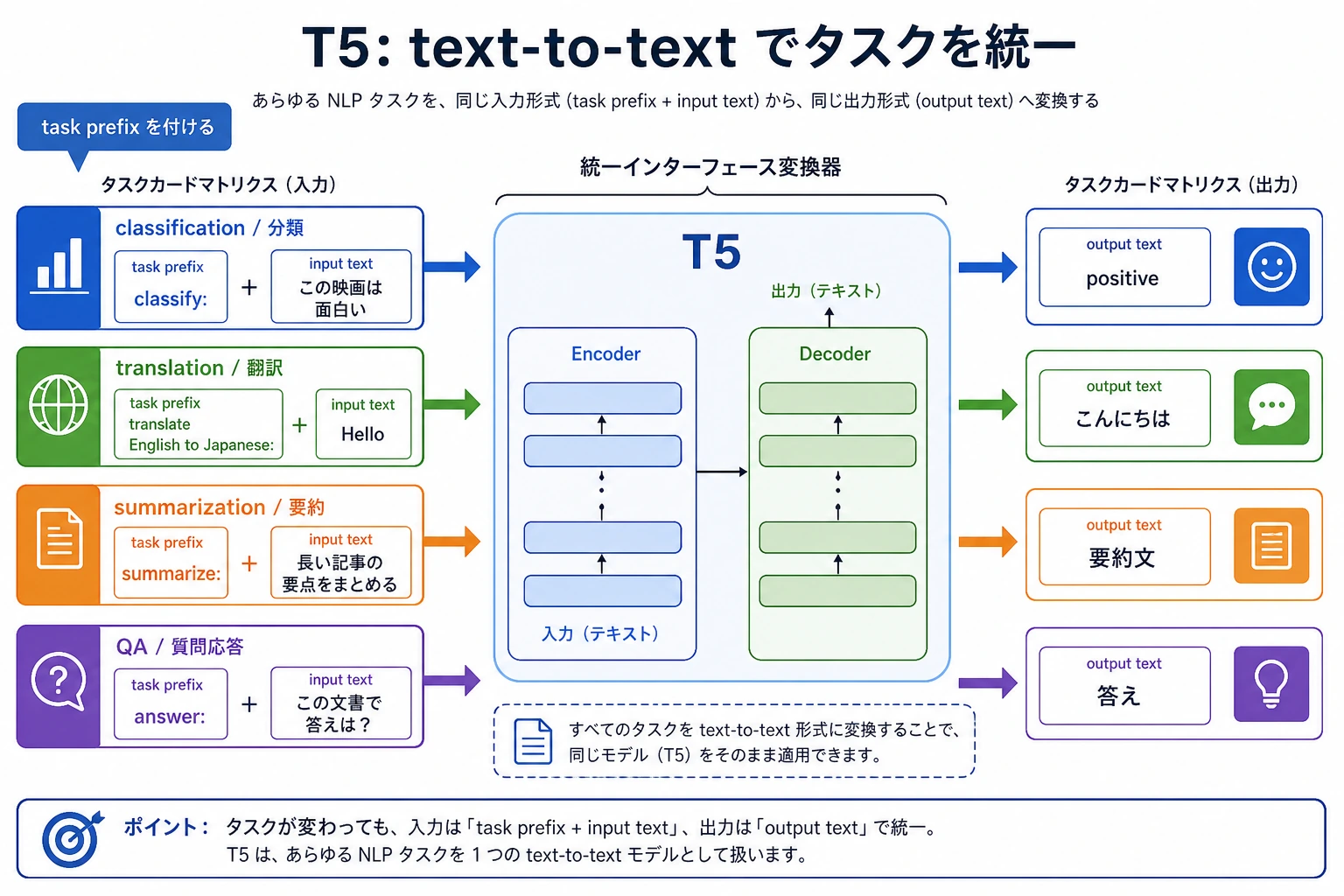
T5 は翻訳、要約、分類、QA をすべて text-to-text として扱います。つまり、タスク説明も入力テキストに入れ、出力もテキストとして返します。
通過条件
| チェック | 合格ライン |
|---|---|
| Seq2Seq | 入力列から出力列を作る問題だと説明できる |
| Encoder-Decoder | 読む部分と生成する部分の役割を分けて言える |
| Attention | 長い入力で重要位置を見直す仕組みだと説明できる |
| デコード | 出力が 1 token ずつ作られる流れを説明できる |