5 機械学習入門から実践まで

第 5 章の目的は 1 つです。データの問題を、学習でき、評価でき、改善できる機械学習プロジェクトに変えることです。
まずモデリングループを見る
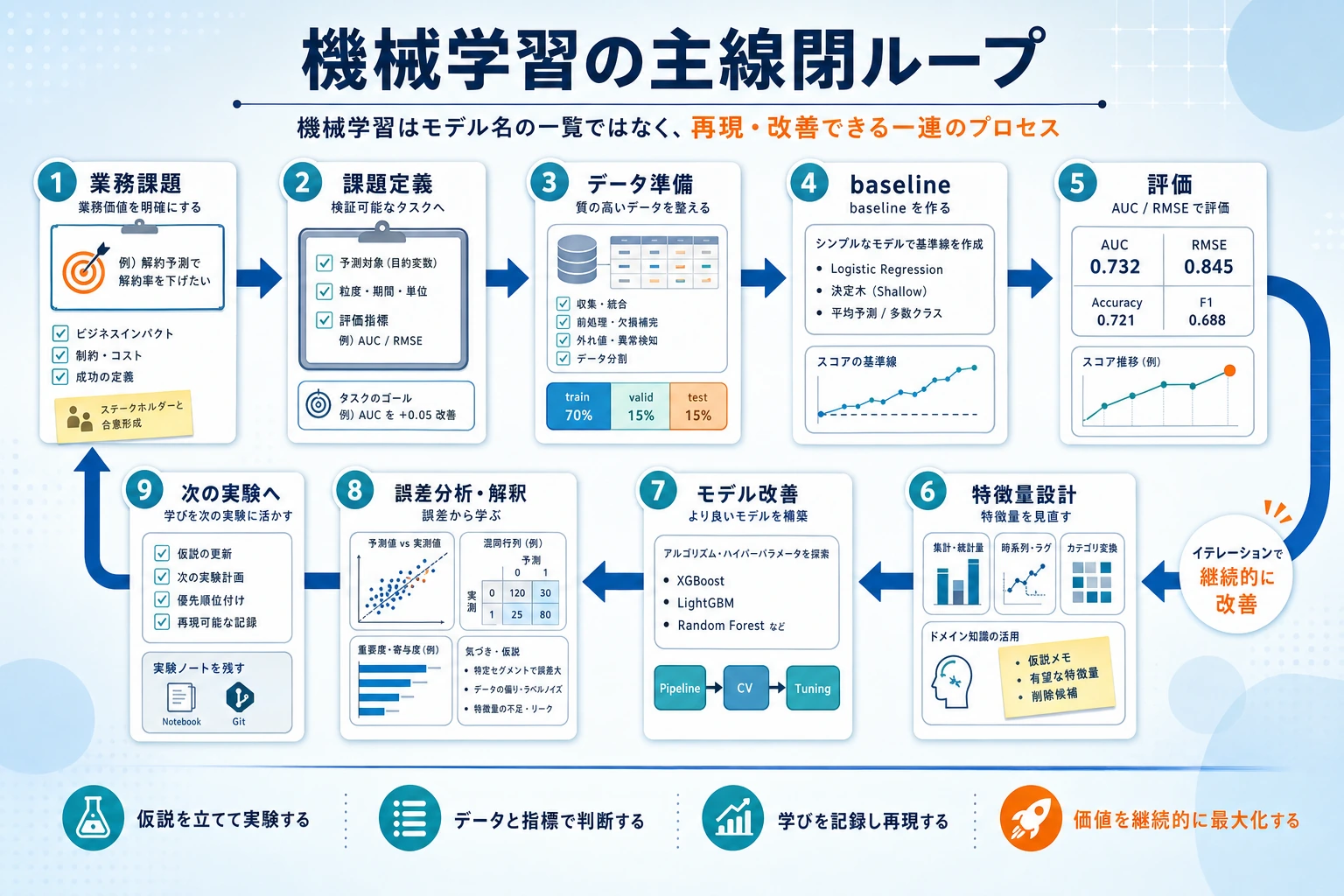
先に図を見てください。信頼できる機械学習の多くは、この流れです。
タスクを定義する -> データを分ける -> baseline を学習する -> 評価する -> エラーを見る -> 改善する
モデル名を追う前に baseline を作ります。baseline があると、後の変更が本当に改善したか判断できます。
学習順序とタスクリスト
この表を、本章の学習ガイド兼タスクリストとして使います。
| ページ | 手を動かすこと | 残す証拠 |
|---|---|---|
| 5.1 機械学習の基礎 | 分類、回帰、クラスタリング、異常検知、特徴量、ラベル、train/test 分割、sklearn の流れを見分ける | 問題定義メモ |
| 5.1.5 機械学習の歴史 | 任意の背景:古典アルゴリズムがなぜ現れたかを軽く読む | 「このアルゴリズムがある理由」のメモ |
| 5.2 教師あり学習 | 多数のモデル比較の前に、回帰と分類の例を動かす | baseline スコアと改善後スコア |
| 5.3 教師なし学習 | ラベルがないときにクラスタリング、次元削減、異常検知を試す | グラフまたはクラスタ解釈 |
| 5.4 評価 | 指標を選び、交差検証を使い、バイアス/バリアンスを診断し、慎重に調整する | 指標選択メモとエラーサンプル |
| 5.5 特徴量エンジニアリング | 欠損値、カテゴリ、スケーリング、特徴量作成、特徴量選択、Pipeline を扱う | 特徴量処理ログとリーク確認 |
| 5.6 プロジェクト と 5.6.6 ワークショップ | 住宅価格、離反、分群、Kaggle の前に、再現可能な証拠パックを作る | README、モデル比較、エラー分析、次の計画 |
本章でよく使う用語:
| 用語 | 意味 |
|---|---|
feature | モデルが使える入力列 |
label / target | モデルが予測する答え |
baseline | まず超えるべき最も単純なモデルやルール |
metric | F1、AUC、MAE、RMSE など、モデルを測るものさし |
leakage | テストデータや答えの情報が学習へ漏れること |
Pipeline | 前処理とモデルをまとめ、リークを減らす仕組み |
最初の実行ループ
sklearn がなければ先に入れます。
python -m pip install scikit-learn
次の自己完結した baseline を実行します。内蔵データセットを使い、データを分割し、dummy baseline と実モデルを学習して比較します。
from sklearn.datasets import load_breast_cancer
from sklearn.dummy import DummyClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
baseline = DummyClassifier(strategy="most_frequent")
baseline.fit(X_train, y_train)
print("Baseline")
print(classification_report(y_test, baseline.predict(X_test), zero_division=0))
model = make_pipeline(StandardScaler(), LogisticRegression(max_iter=1000))
model.fit(X_train, y_train)
print("Logistic regression")
print(classification_report(y_test, model.predict(X_test), zero_division=0))
期待される形:
Baseline
...
Logistic regression
...
最終スコアだけを比べないでください。どのクラスが簡単で、どのクラスが難しく、実運用でどのエラーが重要かを考えます。
よくある失敗
| 症状 | 最初に確認すること | よくある修正 |
|---|---|---|
| スコアが妙に高い | リークまたは train/test 分割ミス | 学習前に特徴量と分割方法を確認する |
| 学習スコアは高いがテストスコアが低い | 過学習 | モデルを単純にする、正則化する、データを増やす |
| すべてのモデルが弱い | ラベルが悪い、特徴量が弱い、指標が合っていない | エラーサンプルとラベル定義を見る |
| accuracy はよいが実務リスクが高い | クラス不均衡または false negative のコストが高い | recall、precision、F1、AUC、しきい値確認を使う |
| 結果を再現できない | random seed、データ版本、依存関係が変わった | seed を固定し、バージョンを記録する |
通過チェック
次の 5 つに答えられたら、第 6 章へ進めます。
- このタスクは分類、回帰、クラスタリング、異常検知のどれですか?
- baseline は何で、実モデルはどのスコアを超える必要がありますか?
- 目的に合う指標は何で、accuracy はいつ誤解を招きますか?
- データリークをどう確認しましたか?
- モデルは何が得意で、何が苦手で、次にどこを改善しますか?
印刷用のチェックリストが必要なときは、5.0 学習ガイドとタスクリスト を使ってください。次の章では sklearn モデルからニューラルネットワークと深層学習へ進みます。