5.2.1 教師あり学習ロードマップ:ラベル付き例から学ぶ
教師あり学習は、ラベル付きの例があるとき、新しい例のラベルを予測するモデルをどう学ぶかを扱います。
まずモデル選択マップを見る
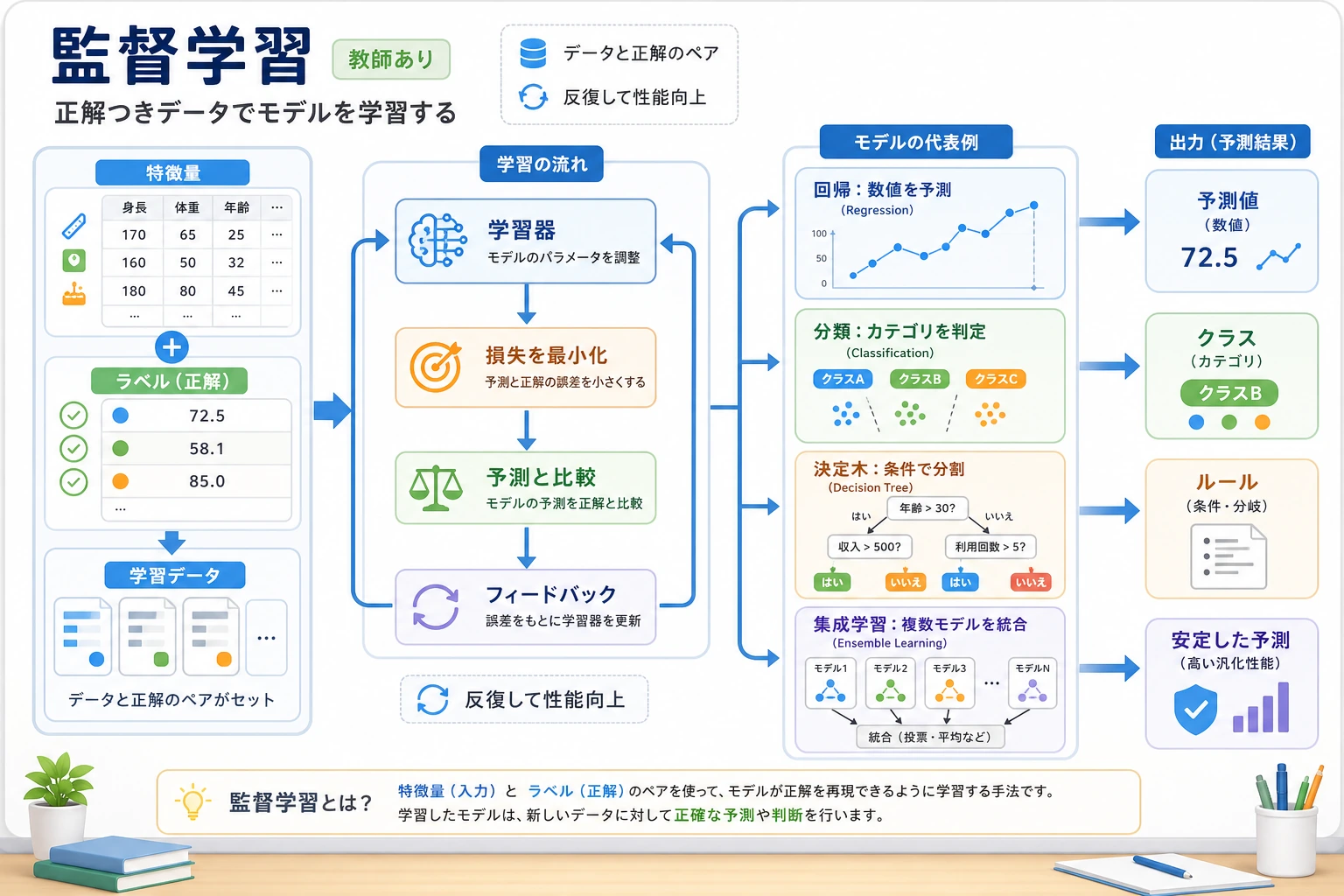
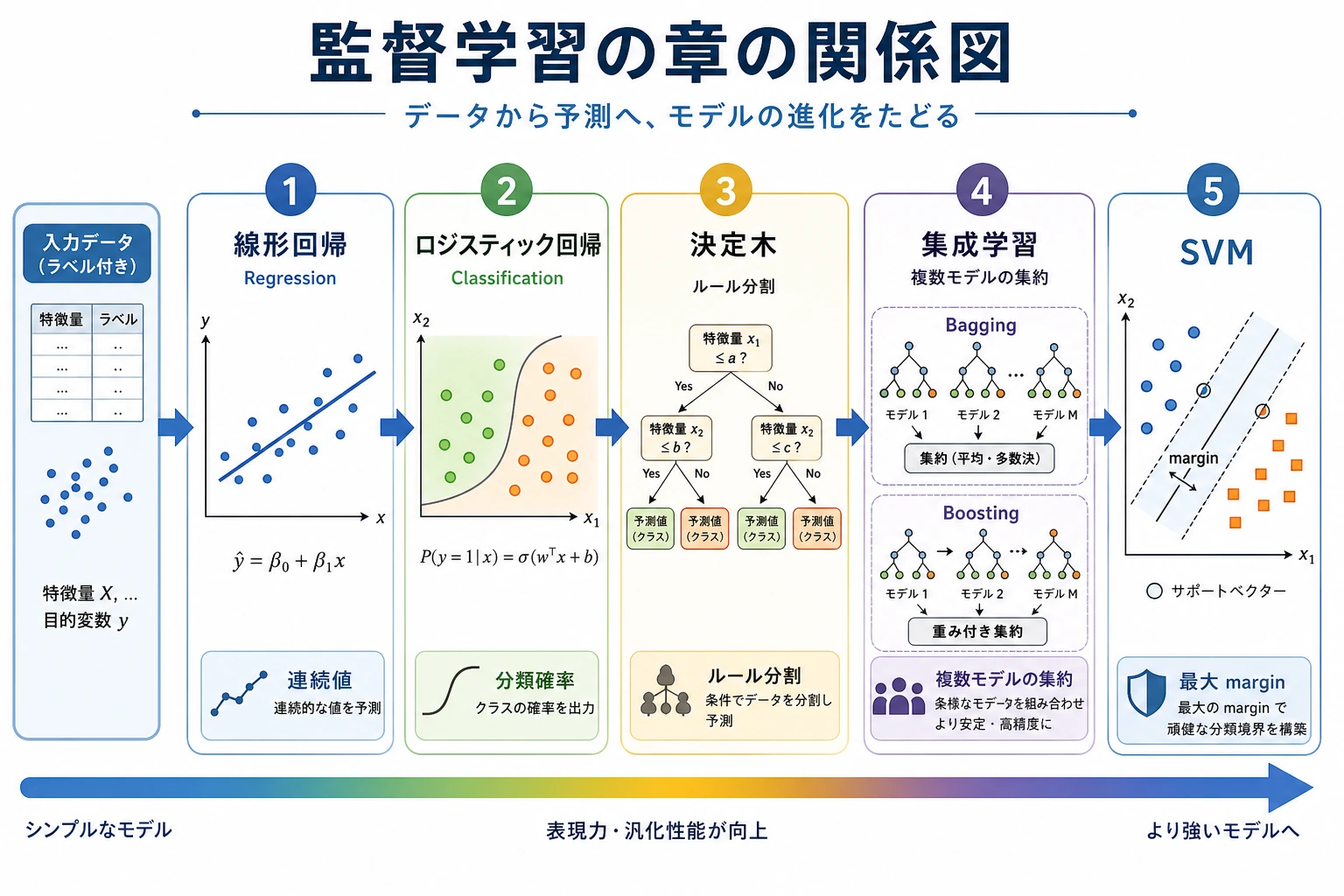
| モデル系統 | 最初の用途 |
|---|---|
| 線形回帰 | 連続値を予測する |
| ロジスティック回帰 | シンプルな確率モデルで分類する |
| 決定木 | 読みやすいルールでデータを分ける |
| アンサンブルモデル | 多くのモデルを組み合わせ、表データの強い baseline を作る |
| SVM | マージンの直感で安定した境界を学ぶ |
回帰 baseline を1つ動かす
supervised_first_loop.py を作り、scikit-learn をインストールしてから実行します。
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = LinearRegression().fit(X_train, y_train)
predictions = model.predict(X_test)
print("task: regression")
print("r2:", round(r2_score(y_test, predictions), 3))
print("first_prediction:", round(predictions[0], 1))
出力:
task: regression
r2: 0.485
first_prediction: 137.9
スコアが完璧でなくても価値があります。baseline は、後のモデルや特徴量改善がどこを超えるべきかを教えてくれます。
この順番で学ぶ
| 順番 | 読む | 比較すること |
|---|---|---|
| 1 | 5.2.2 線形回帰 | シンプルな数値予測 |
| 2 | 5.2.3 ロジスティック回帰 | 分類確率 |
| 3 | 5.2.4 決定木 | ルール、非線形、過学習 |
| 4 | 5.2.5 アンサンブル学習 | bagging、boosting、強い表データモデル |
| 5 | 5.2.6 サポートベクターマシン | マージン、境界、古典的分類器の直感 |
合格ライン
ラベル付きタスクが回帰か分類かを判断でき、baseline を1つ動かし、モデルが失敗しそうな理由を1つ説明できれば合格です。