5.5.1 特徴量エンジニアリングロードマップ:学びやすいデータにする
特徴量エンジニアリングは、入力をモデルにとって有用で、安定し、安全な形にする作業です。モデルの問題に見えるものが、実は特徴量の問題であることはよくあります。
まず特徴量フローを見る
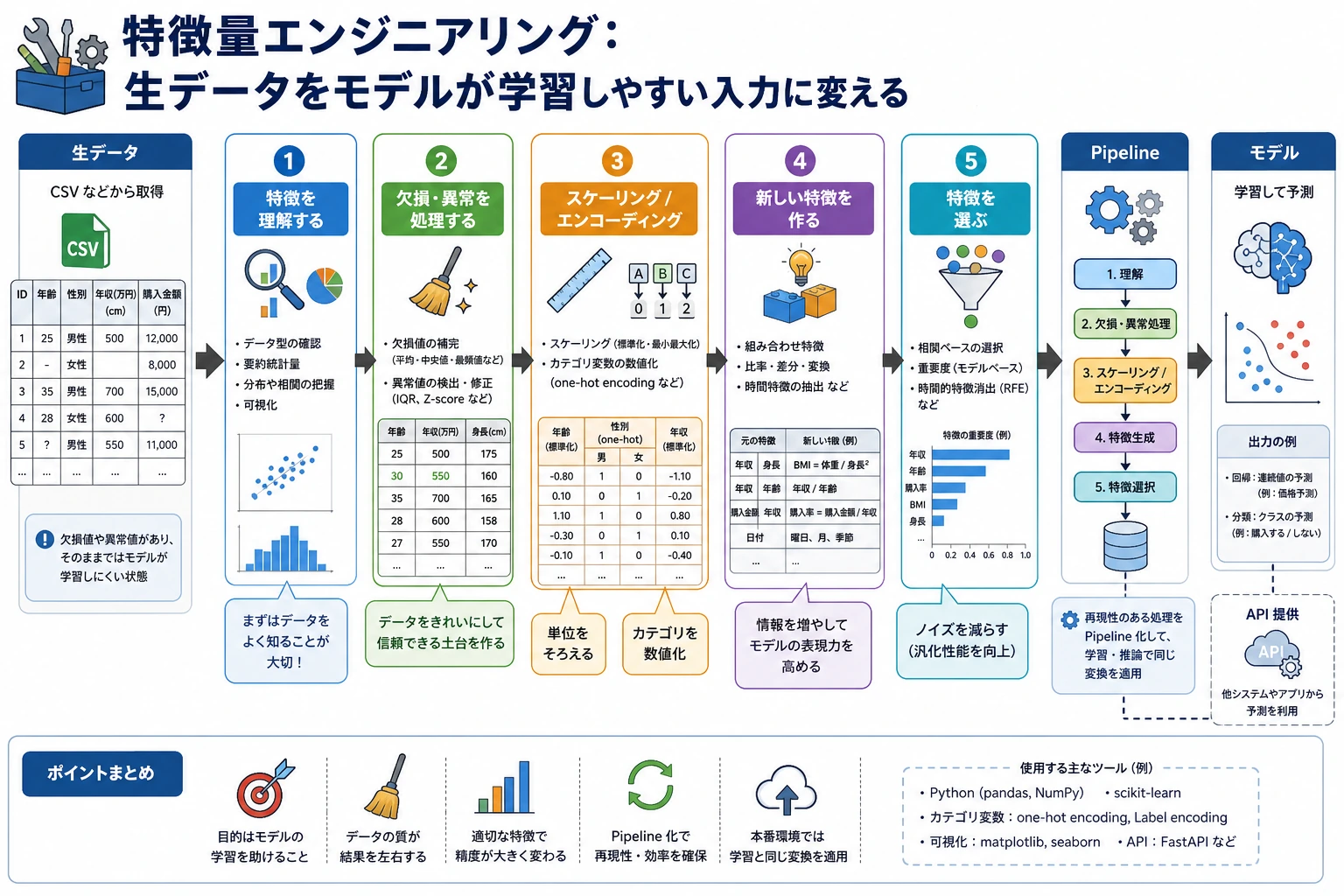

列を理解 -> 前処理 -> 作成 -> 選択 -> Pipeline 化
| 手順 | 最初の行動 |
|---|---|
| 理解 | 数値、カテゴリ、テキスト、日付、target 列を分ける |
| 前処理 | スケーリング、エンコード、欠損補完 |
| 作成 | 比率、カウント、日付、交互作用を作る |
| 選択 | 役に立たない特徴量やリーク特徴量を外す |
| Pipeline | 前処理を再現可能にする |
Pipeline を一度動かす
feature_first_loop.py を作り、pandas と scikit-learn をインストールしてから実行します。
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
X = pd.DataFrame(
{
"age": [22, 35, 47, 52, 28, 41],
"city": ["A", "B", "A", "C", "B", "C"],
"visits": [2, 6, 5, 9, 3, 7],
}
)
y = [0, 1, 1, 1, 0, 1]
preprocess = ColumnTransformer(
transformers=[
("num", StandardScaler(), ["age", "visits"]),
("cat", OneHotEncoder(handle_unknown="ignore"), ["city"]),
]
)
pipe = Pipeline([("preprocess", preprocess), ("model", LogisticRegression())])
pipe.fit(X, y)
print("pipeline_steps:", list(pipe.named_steps))
print("training_accuracy:", round(pipe.score(X, y), 3))
出力:
pipeline_steps: ['preprocess', 'model']
training_accuracy: 1.0
このデータは小さすぎるため、本物の評価には使えません。ここで見るのは、前処理とモデルを一緒に運ぶ流れです。
この順番で学ぶ
| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 5.5.2 特徴量理解 | 特徴量タイプ、target、リークリスク |
| 2 | 5.5.3 データ前処理 | スケーリング、エンコード、欠損値 |
| 3 | 5.5.4 特徴量作成 | 比率、ビン分割、日付、交互作用 |
| 4 | 5.5.5 特徴量選択 | ノイズ、冗長性、リークを減らす |
| 5 | 5.5.6 Pipeline | 再現可能な前処理と学習 |
合格ライン
特徴量タイプを列挙し、前処理 Pipeline を1つ作り、train/test の流れの外で前処理するとリークにつながる理由を説明できれば合格です。