6 深層学習と Transformer 基礎

第 6 章の目的は 1 つです。モデルが損失、勾配、反復する学習ステップによってどう学ぶのかを理解することです。
まず学習ループを見る
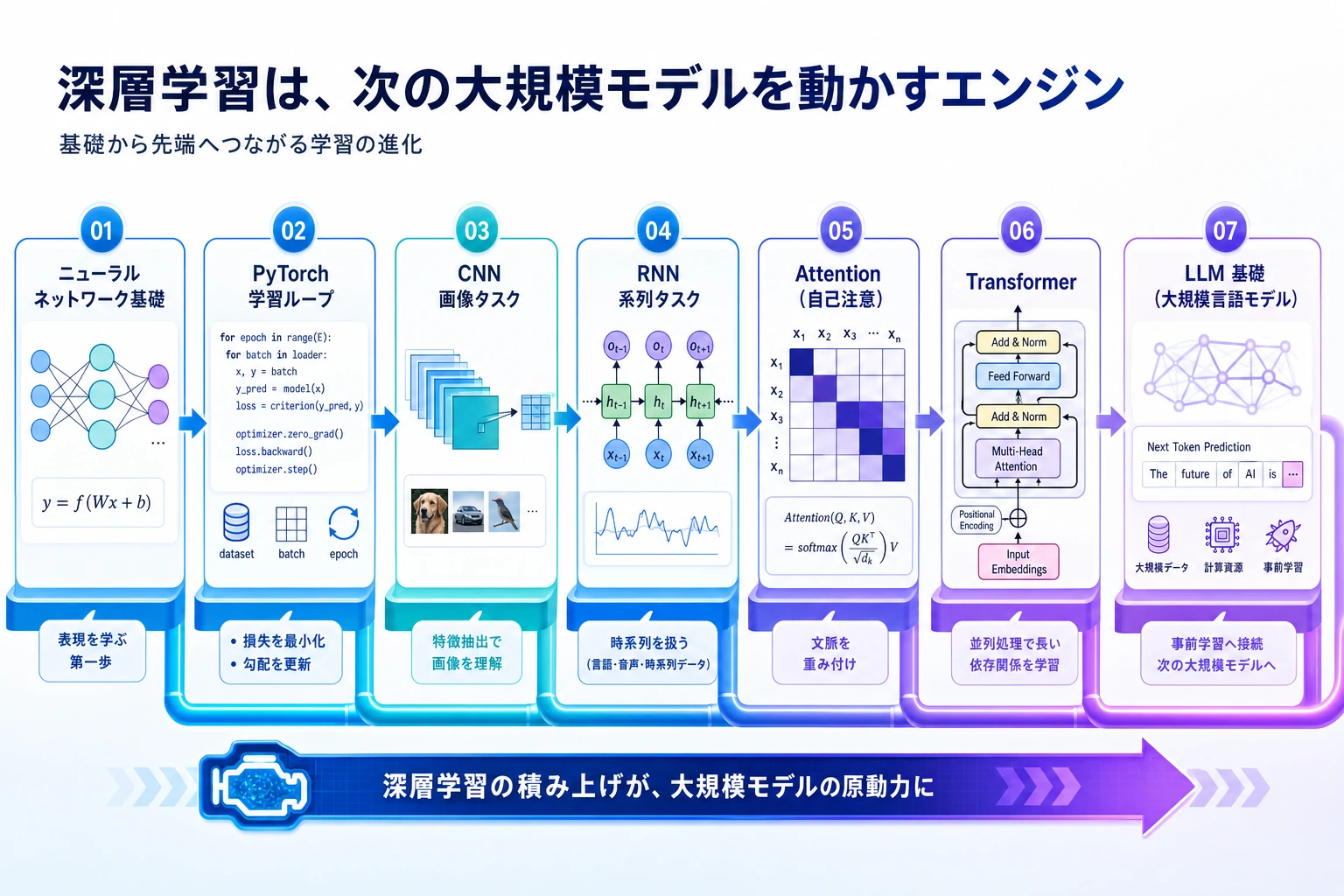
先に図を見てください。深層学習の学習コードの多くは、この流れです。
batch データ -> モデル forward -> loss -> 勾配 backward -> optimizer step -> 曲線
最初から大きなモデルを追わないでください。まず小さなモデルを学習させ、何が起きたかを記録し、なぜ改善または失敗したかを説明します。
学習順序とタスクリスト
この表を、本章の学習ガイド兼タスクリストとして使います。
| ページ | 手を動かすこと | 残す証拠 |
|---|---|---|
| 6.1 ニューラルネットワーク基礎 | ニューロン、活性化、forward/backward、optimizer、正則化、初期化を理解する | 手書きの学習ループ説明 |
| 6.2 PyTorch | tensor、autograd、nn.Module、Dataset、DataLoader、最小学習ループを練習する | 実行できる PyTorch スクリプト |
| 6.3 CNN | 画像分類でデータ形状、畳み込み、プーリング、転移学習をつなげる | shape メモと画像分類の実行結果 |
| 6.4 RNN | 系列データに記憶が必要な理由、LSTM/GRU が Transformer 前に解いた問題を理解する | 系列モデルメモ |
| 6.5 Transformer | Query、Key、Value、self-attention、位置エンコーディング、Transformer block を学ぶ | attention の入出力図 |
| 6.1.8 任意の深層学習史 | 主な学習ループを理解してから、backprop、CNN、RNN、Attention、Transformer がなぜ現れたかを読む | 「この構造がある理由」のメモ |
| 6.6 生成モデル と 6.7 学習テクニック | 学習ループが安定してから拡張として扱う | チューニングまたは診断メモ |
| 6.8 プロジェクト と 6.8.5 ワークショップ | 画像、感情分析、生成プロジェクトの前に PyTorch 証拠パックを作る | ログ、曲線、checkpoint、shape trace、README |
本章でよく使う用語:
| 用語 | 意味 |
|---|---|
tensor | PyTorch が使う多次元配列 |
forward | データがモデルを通り、予測を作る流れ |
loss | 予測誤差を測る数値 |
backward | loss から勾配を計算すること |
optimizer | 勾配を使ってパラメータを更新するもの |
epoch | 学習データ全体を 1 回見ること |
batch | 一度に処理する小さなサンプル群 |
最初の実行ループ
PyTorch がなければ公式セレクタで先にインストールします。PyTorch が使える状態で、次の小さな学習ループを実行してください。
import torch
from torch import nn
torch.manual_seed(42)
x = torch.tensor([[0.0], [1.0], [2.0], [3.0]])
y = torch.tensor([[0.0], [2.0], [4.0], [6.0]])
model = nn.Linear(1, 1)
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(20):
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch in {0, 1, 5, 19}:
print(epoch, round(loss.item(), 4))
期待される形:
0 ...
1 ...
5 ...
19 ...
具体的な数値は環境で変わることがありますが、loss はおおむね下がるはずです。下がれば、学習ループが動いていることを確認できています。
よくある失敗
| 症状 | 最初に確認すること | よくある修正 |
|---|---|---|
| shape mismatch | 入力 shape、batch 次元、出力クラス数 | 各層で tensor shape を表示する |
| loss が下がらない | 学習率、ラベル、正規化、損失関数 | まず小さな batch を過学習できるか試す |
| 学習は良いが検証が悪い | 過学習またはデータ分割の問題 | 検証曲線、データ拡張、正則化、early stopping を使う |
| メモリ不足 | batch サイズ、画像サイズ、モデルサイズ | batch/解像度を下げる、軽いモデルにする |
| Transformer が抽象的 | Q/K/V と系列長 | コード前に attention 表を描く |
通過チェック
次の 5 つに答えられたら、第 7 章へ進めます。
forward、loss.backward()、optimizer.step()はそれぞれ何をしますか?- Dataset と DataLoader はそれぞれ何を解決しますか?
- 学習曲線と検証曲線は、過学習をどう示しますか?
- Attention はなぜ文脈を扱えますか?
- Transformer は後の大規模モデルとどうつながりますか?
印刷用のチェックリストが必要なときは、6.0 学習ガイドとタスクリスト を使ってください。後の LLM、RAG、多モーダルモデルは、すべてこの表現学習の考え方の上にあります。