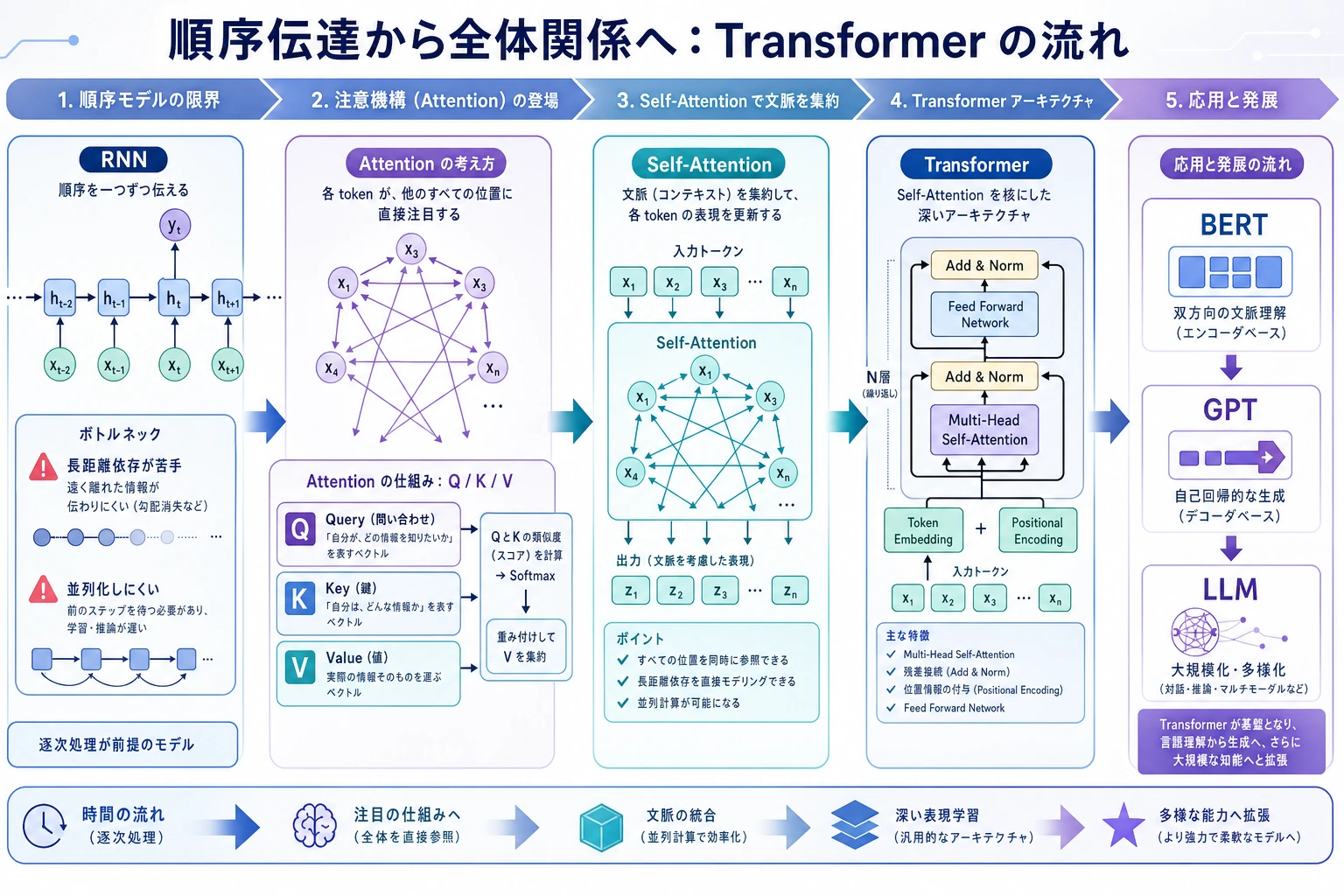
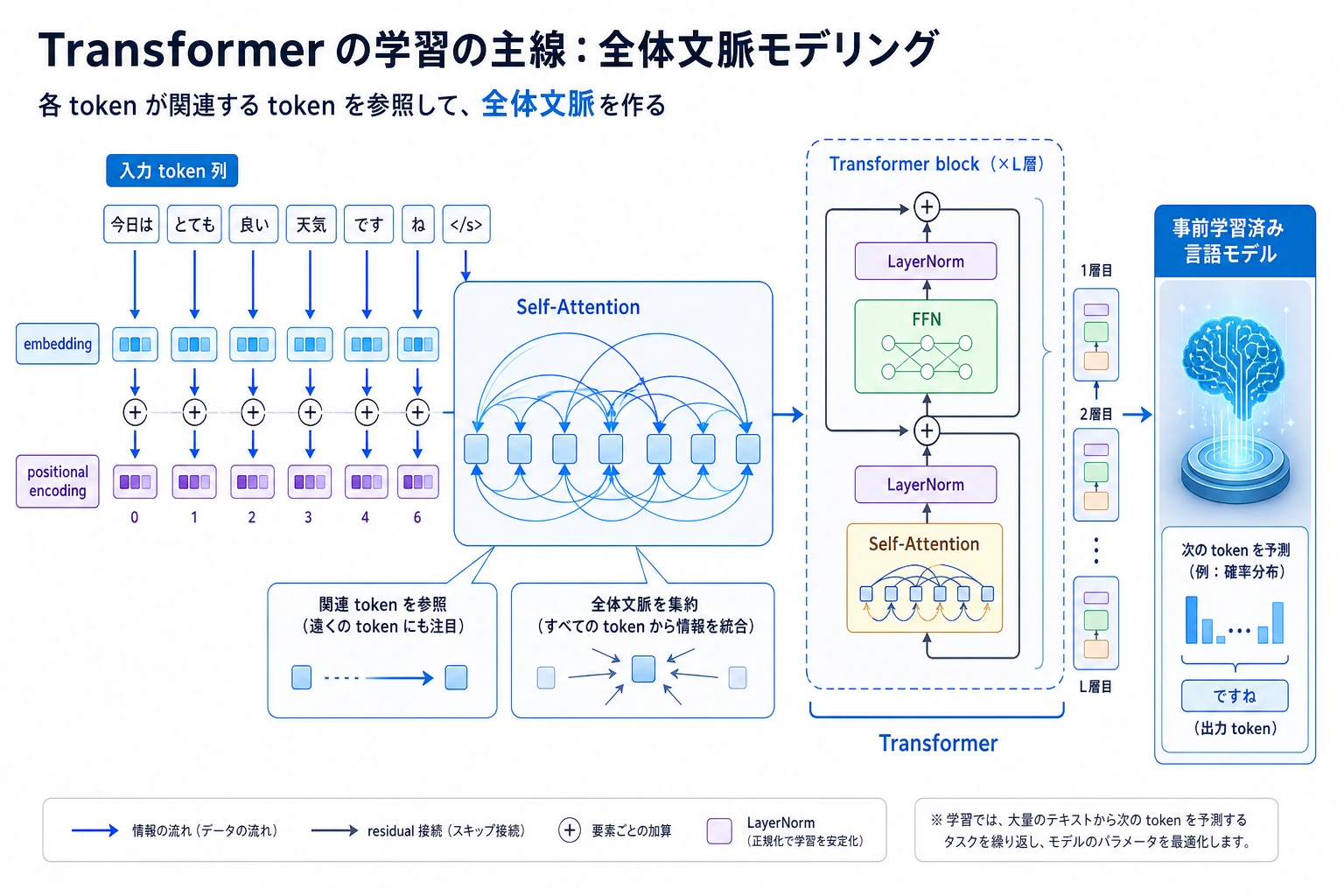
6.5.1 Transformer ロードマップ:Attention で token 同士を見る
Transformer は深層学習から現代 LLM への橋です。最初の直感は単純です。各 token が、どの他 token を重要視するかを決めます。
まず Attention の流れを見る
| 概念 | 最初の意味 |
|---|---|
| token | 系列内の1つの位置 |
| Q / K / V | token の query、key、value 視点 |
| attention weight | ある token が別の token をどれくらい見るか |
| block | attention と feed-forward による表現の更新 |
| mask | 生成時に未来 token を見ないための制御 |
Attention の形を一度確認する
transformer_first_loop.py を作り、torch をインストールしてから実行します。
import torch
attention = torch.nn.MultiheadAttention(embed_dim=8, num_heads=2, batch_first=True)
tokens = torch.randn(1, 4, 8)
output, weights = attention(tokens, tokens, tokens)
print("tokens_shape:", tuple(tokens.shape))
print("output_shape:", tuple(output.shape))
print("attention_shape:", tuple(weights.shape))
出力:
tokens_shape: (1, 4, 8)
output_shape: (1, 4, 8)
attention_shape: (1, 4, 4)
attention_shape は [batch, query_position, key_position] です。4つの位置それぞれが4つの位置を見られます。
この順番で学ぶ
| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 6.5.2 Attention 機構 | QKV、attention 重み、mask |
| 2 | 6.5.3 Transformer アーキテクチャ | block 構造、残差、feed-forward 層 |
合格ライン
attention 重みの形を読み、attention がなぜグローバル文脈を持てるかを説明し、mask をテキスト生成と結びつけられれば合格です。