6.5.1 Transformer 路线图:Attention 让 token 互相看见
Transformer 是从深度学习走向现代 LLM 的桥。第一直觉很简单:每个 token 可以决定哪些其他 token 更重要。
先看 Attention 流程
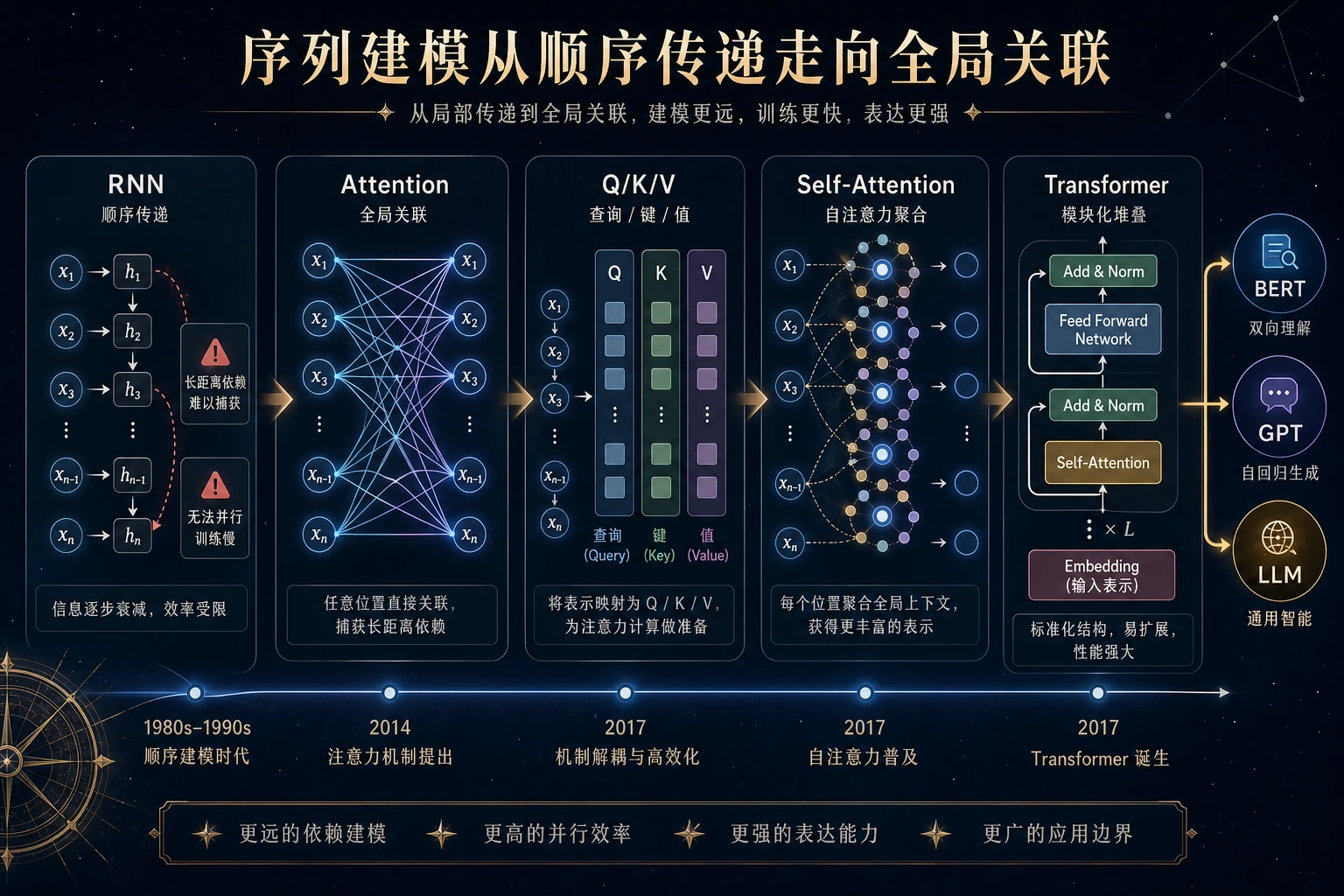
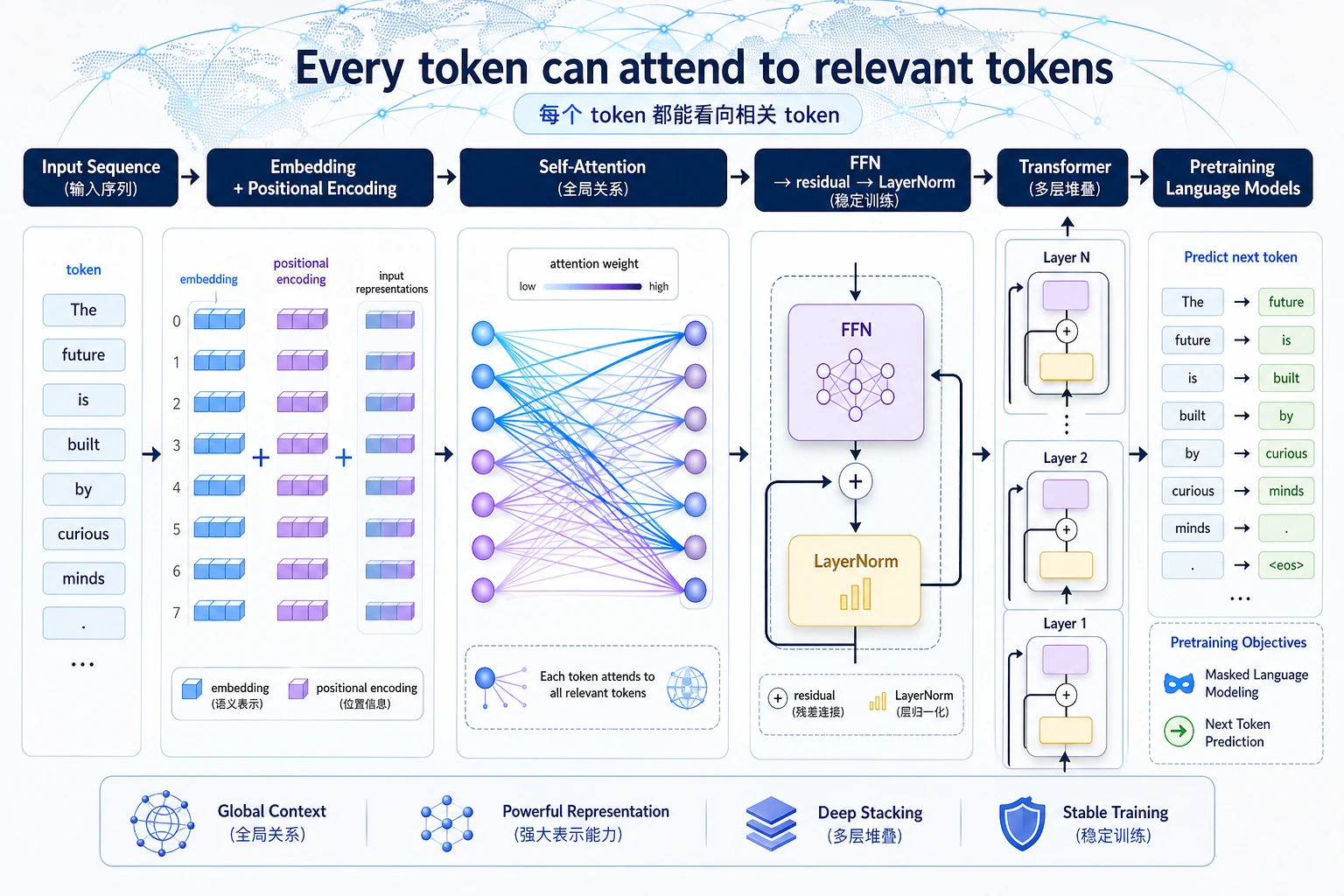
| 概念 | 第一层意思 |
|---|---|
| token | 序列里的一个位置 |
| Q / K / V | token 的 query、key、value 视角 |
| attention weight | 一个 token 看另一个 token 的程度 |
| block | attention 加前馈层反复精炼表示 |
| mask | 生成时防止看见未来 token |
跑一次 Attention 形状检查
创建 transformer_first_loop.py,安装 torch 后运行。
import torch
attention = torch.nn.MultiheadAttention(embed_dim=8, num_heads=2, batch_first=True)
tokens = torch.randn(1, 4, 8)
output, weights = attention(tokens, tokens, tokens)
print("tokens_shape:", tuple(tokens.shape))
print("output_shape:", tuple(output.shape))
print("attention_shape:", tuple(weights.shape))
预期输出:
tokens_shape: (1, 4, 8)
output_shape: (1, 4, 8)
attention_shape: (1, 4, 4)
attention_shape 是 [batch, query_position, key_position]:4 个位置里的每个位置都能看 4 个位置。
按这个顺序学
| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 6.5.2 Attention 机制 | QKV、attention 权重、mask |
| 2 | 6.5.3 Transformer 架构 | block 结构、残差、前馈层 |
通过标准
能读懂 attention 权重形状,解释为什么 attention 带来全局上下文,并把 mask 和文本生成联系起来,就算通过。