6.5.3 Transformer 架构
本节定位
注意力是心脏,但 Transformer block 能稳定工作,是因为多个工程部件一起配合:残差保信息,归一化稳数值,FFN 加工每个 token,位置信号补上顺序。
学习目标
- 把 Transformer block 读成一条可执行的数据流。
- 不靠死记层名,解释残差连接、LayerNorm 和 FFN。
- 跑通 PyTorch 示例,读懂主要 shape。
- 分清 encoder-only、decoder-only、encoder-decoder。
- 理解现代 LLM decoder 为什么常用 pre-norm、RMSNorm、RoPE、GQA/MQA 和 SwiGLU。
先看 Block 图
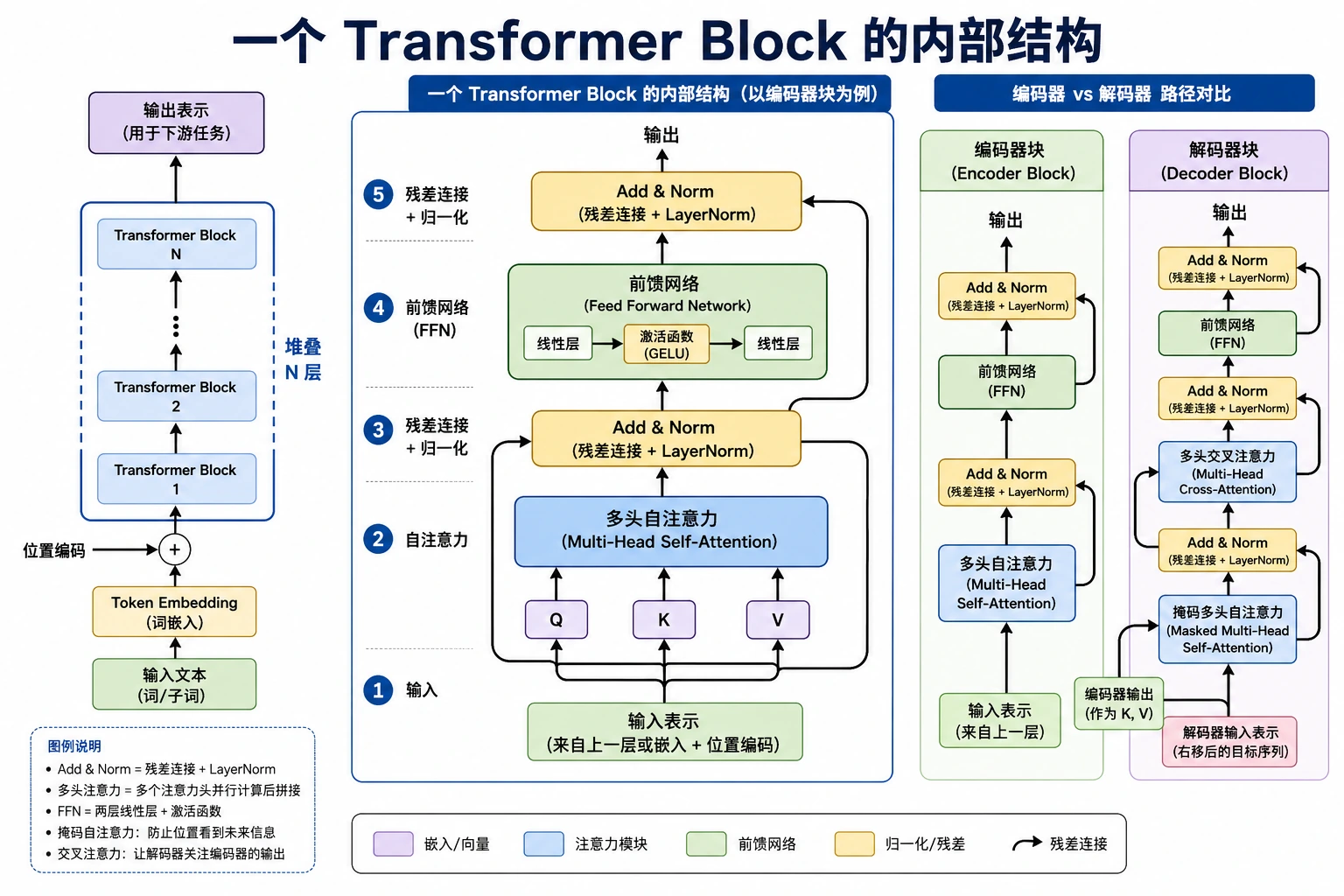
一个 Transformer block 通常保持外层 shape 不变:
[batch, seq_len, d_model] -> [batch, seq_len, d_model]
shape 常常没变,但表示会变得更理解上下文。
| 部件 | 做什么 | 为什么重要 |
|---|---|---|
| Multi-head attention | 在 token 位置之间混合信息 | 建立上下文 |
| 残差连接 | 把输入加回去 | 保护信息和梯度 |
| LayerNorm / RMSNorm | 稳定特征尺度 | 让深层训练更容易 |
| FFN | 独立变换每个位置 | 增加非线性加工能力 |
| 位置信息 | 告诉模型 token 顺序 | 注意力本身不够懂顺序 |
实验 1:检查 PyTorch Transformer Block
import torch
from torch import nn
torch.manual_seed(42)
layer = nn.TransformerEncoderLayer(
d_model=16,
nhead=4,
dim_feedforward=32,
batch_first=True,
norm_first=True,
dropout=0.0,
)
print("block_parts")
print(type(layer.self_attn).__name__)
print("linear1:", tuple(layer.linear1.weight.shape))
print("linear2:", tuple(layer.linear2.weight.shape))
print("norm_first:", layer.norm_first)
print("norm:", type(layer.norm1).__name__)
预期输出:
block_parts
MultiheadAttention
linear1: (32, 16)
linear2: (16, 32)
norm_first: True
norm: LayerNorm
参数读法:
d_model=16:每个 token 表示有 16 个特征。nhead=4:注意力分成 4 个 head。dim_feedforward=32:FFN 先从 16 扩到 32,再投影回 16。batch_first=True:张量使用[batch, seq_len, d_model]。norm_first=True:使用 pre-norm,这是深层堆叠里常见的稳定模式。
残差与归一化
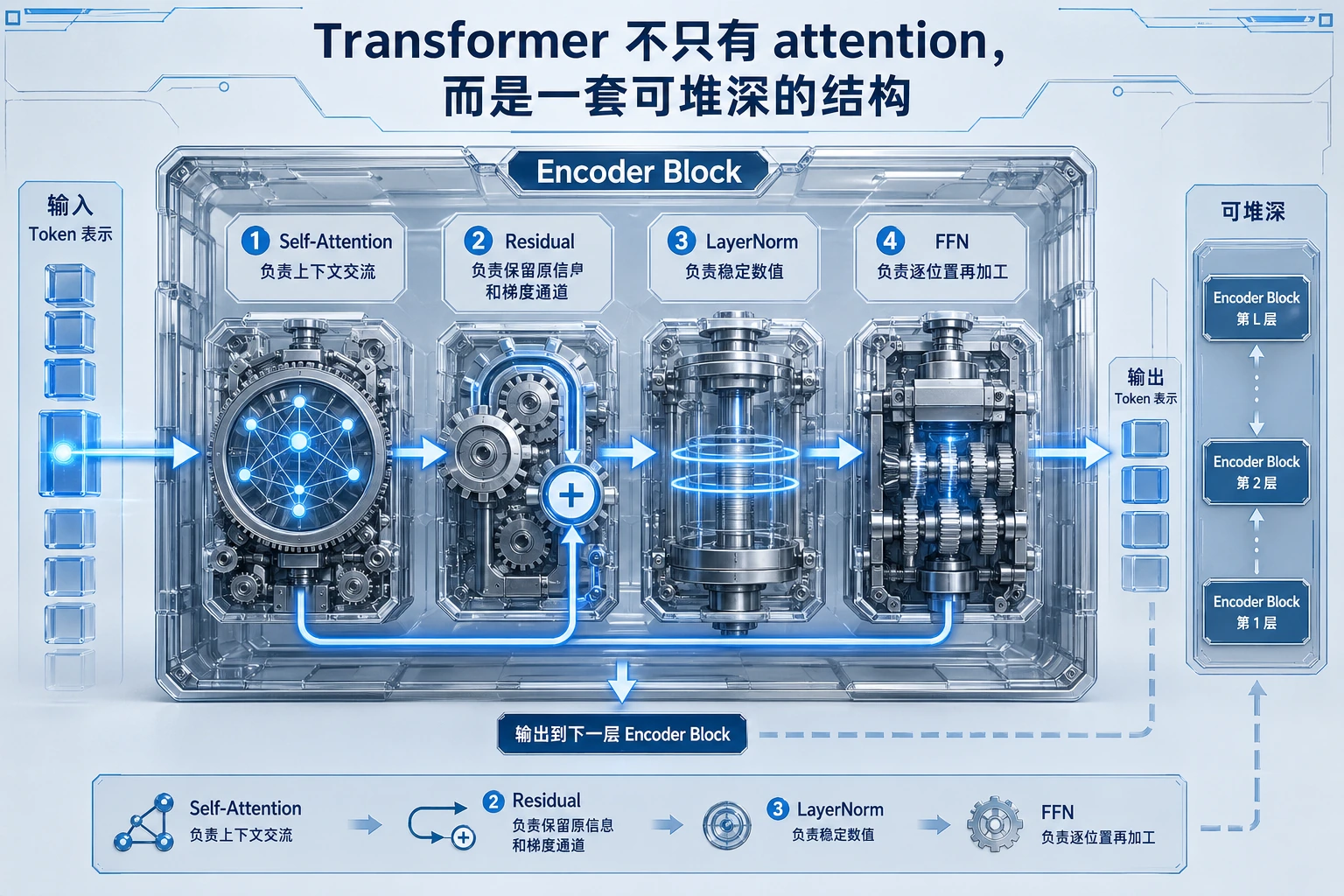
残差连接和归一化不是装饰。它们让 block 可以堆深,同时不轻易丢失原始信号,也不让数值变得难以训练。
实验 2:残差连接
import torch
x = torch.tensor([[1.0, 2.0, 3.0]])
f_x = torch.tensor([[0.1, -0.2, 0.3]])
y = x + f_x
print("residual_lab")
print(y)
预期输出:
residual_lab
tensor([[1.1000, 1.8000, 3.3000]])
这一层只需要学习一个有用的更新量 f(x)。旧表示 x 仍然通过短路保留下来。
实验 3:LayerNorm
import torch
from torch import nn
x = torch.tensor(
[
[1.0, 2.0, 3.0, 10.0],
[2.0, 2.5, 3.5, 9.0],
]
)
ln = nn.LayerNorm(4)
y = ln(x)
print("layernorm_lab")
print(torch.round(y.detach(), decimals=3))
print("row_means:", torch.round(y.mean(dim=1).detach(), decimals=4))
print("row_stds:", torch.round(y.std(dim=1, unbiased=False).detach(), decimals=4))
预期输出:
layernorm_lab
tensor([[-0.8490, -0.5660, -0.2830, 1.6970],
[-0.8050, -0.6260, -0.2680, 1.6990]])
row_means: tensor([0., 0.])
row_stds: tensor([1., 1.])
LayerNorm 是对每个 token 的特征维度做归一化,不是跨 batch 做归一化。
FFN:同一个位置,更强的非线性加工
注意力负责跨位置混合信息。前馈网络在混合之后,对每个位置独立加工。
import torch
from torch import nn
torch.manual_seed(42)
x = torch.randn(2, 5, 8)
ffn = nn.Sequential(
nn.Linear(8, 32),
nn.GELU(),
nn.Linear(32, 8),
)
y = ffn(x)
print("ffn_lab")
print("input:", tuple(x.shape))
print("output:", tuple(y.shape))
预期输出:
ffn_lab
input: (2, 5, 8)
output: (2, 5, 8)
FFN 会在内部扩展 hidden size,再投影回来。序列长度不变。
位置信息
Self-attention 可以比较 token,但它天然不知道某个 token 是第一个、第二个还是最后一个。位置信息用来补上顺序。
import torch
positions = torch.arange(5).float().unsqueeze(1)
dims = torch.arange(0, 8, 2).float()
angle_rates = 1 / (10000 ** (dims / 8))
angles = positions * angle_rates
pe = torch.zeros(5, 8)
pe[:, 0::2] = torch.sin(angles)
pe[:, 1::2] = torch.cos(angles)
print("positional_lab")
print(torch.round(pe[:3], decimals=4))
预期输出:
positional_lab
tensor([[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.0998, 0.9950, 0.0100, 1.0000, 0.0010, 1.0000],
[ 0.9093, -0.4161, 0.1987, 0.9801, 0.0200, 0.9998, 0.0020, 1.0000]])
现代 LLM 常用 RoPE,而不是这种经典 sinusoidal 风格。实际目标一样:让注意力获得可用的顺序和相对距离感。
实验 4:运行一个 Encoder Block
import torch
from torch import nn
torch.manual_seed(42)
encoder_layer = nn.TransformerEncoderLayer(
d_model=16,
nhead=4,
dim_feedforward=32,
batch_first=True,
norm_first=True,
dropout=0.0,
)
tokens = torch.randn(2, 6, 16)
out = encoder_layer(tokens)
print("encoder_shape_lab")
print("input:", tuple(tokens.shape))
print("output:", tuple(out.shape))
print("changed:", bool(torch.not_equal(tokens, out).any()))
预期输出:
encoder_shape_lab
input: (2, 6, 16)
output: (2, 6, 16)
changed: True
shape 没变,但每个 token 都已经被其他 token 的上下文重写过。
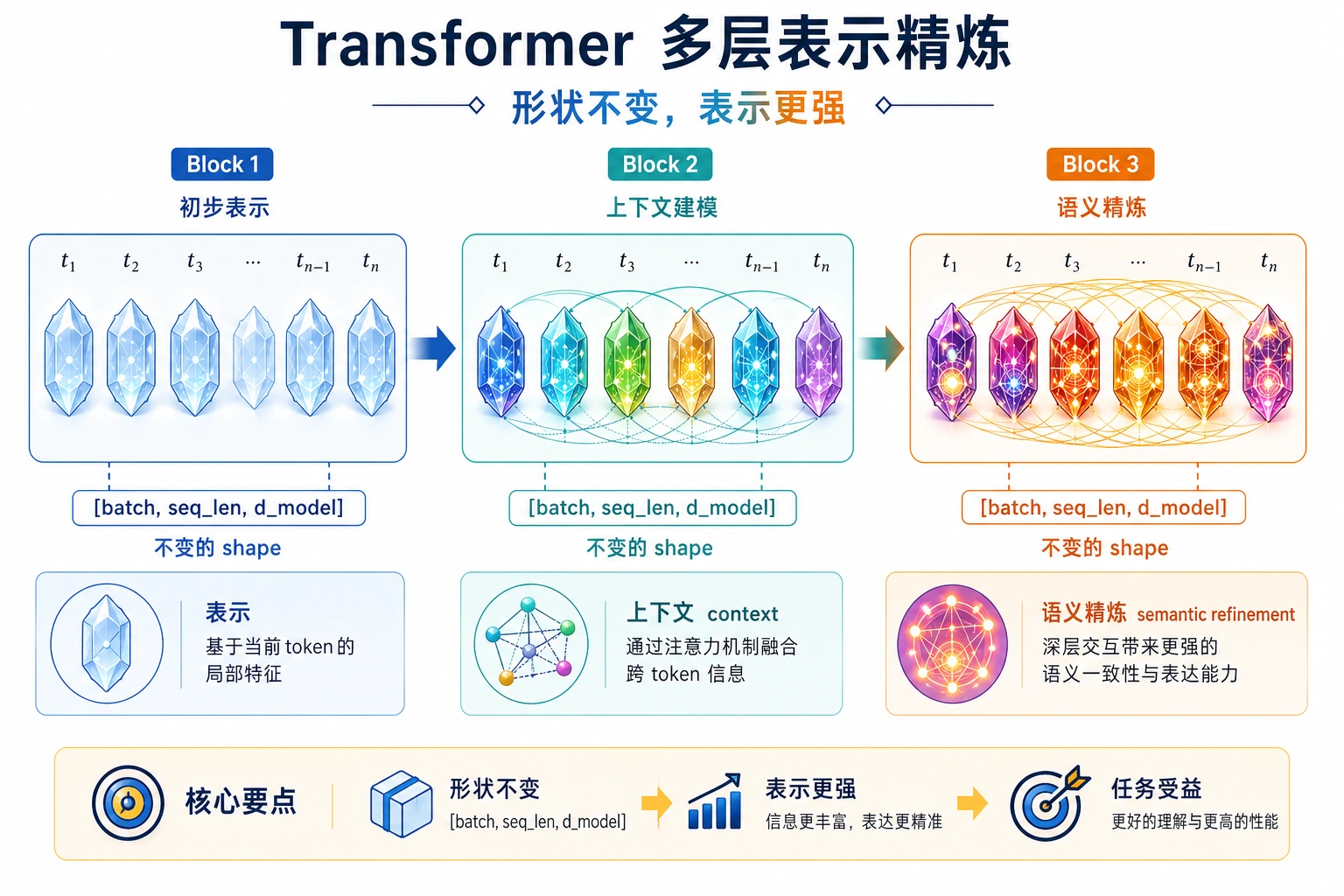
Encoder、Decoder 与 Encoder-Decoder
| 路线 | 代表模型 | 主要用途 | 注意力模式 |
|---|---|---|---|
| Encoder-only | BERT | 理解与分类 | 双向 self-attention |
| Decoder-only | GPT 类 LLM | 生成 | causal self-attention |
| Encoder-decoder | T5、原版 Transformer | 读一个序列,生成另一个序列 | encoder self-attention 加 decoder cross-attention |
实验 5:Decoder Shape 与 Cross-Attention
import torch
from torch import nn
torch.manual_seed(42)
decoder_layer = nn.TransformerDecoderLayer(
d_model=16,
nhead=4,
dim_feedforward=32,
batch_first=True,
norm_first=True,
dropout=0.0,
)
target = torch.randn(2, 3, 16)
memory = torch.randn(2, 5, 16)
causal_mask = nn.Transformer.generate_square_subsequent_mask(target.size(1))
out = decoder_layer(target, memory, tgt_mask=causal_mask)
print("decoder_shape_lab")
print("target:", tuple(target.shape))
print("memory:", tuple(memory.shape))
print("mask:", tuple(causal_mask.shape))
print("output:", tuple(out.shape))
预期输出:
decoder_shape_lab
target: (2, 3, 16)
memory: (2, 5, 16)
mask: (3, 3)
output: (2, 3, 16)
这样读:
target是 decoder 已经生成到的位置。memory是 encoder 输出。causal_mask防止 decoder 内部偷看未来。- Cross-attention 让 decoder 能看编码后的输入。
早期 Transformer 与现代 LLM Decoder
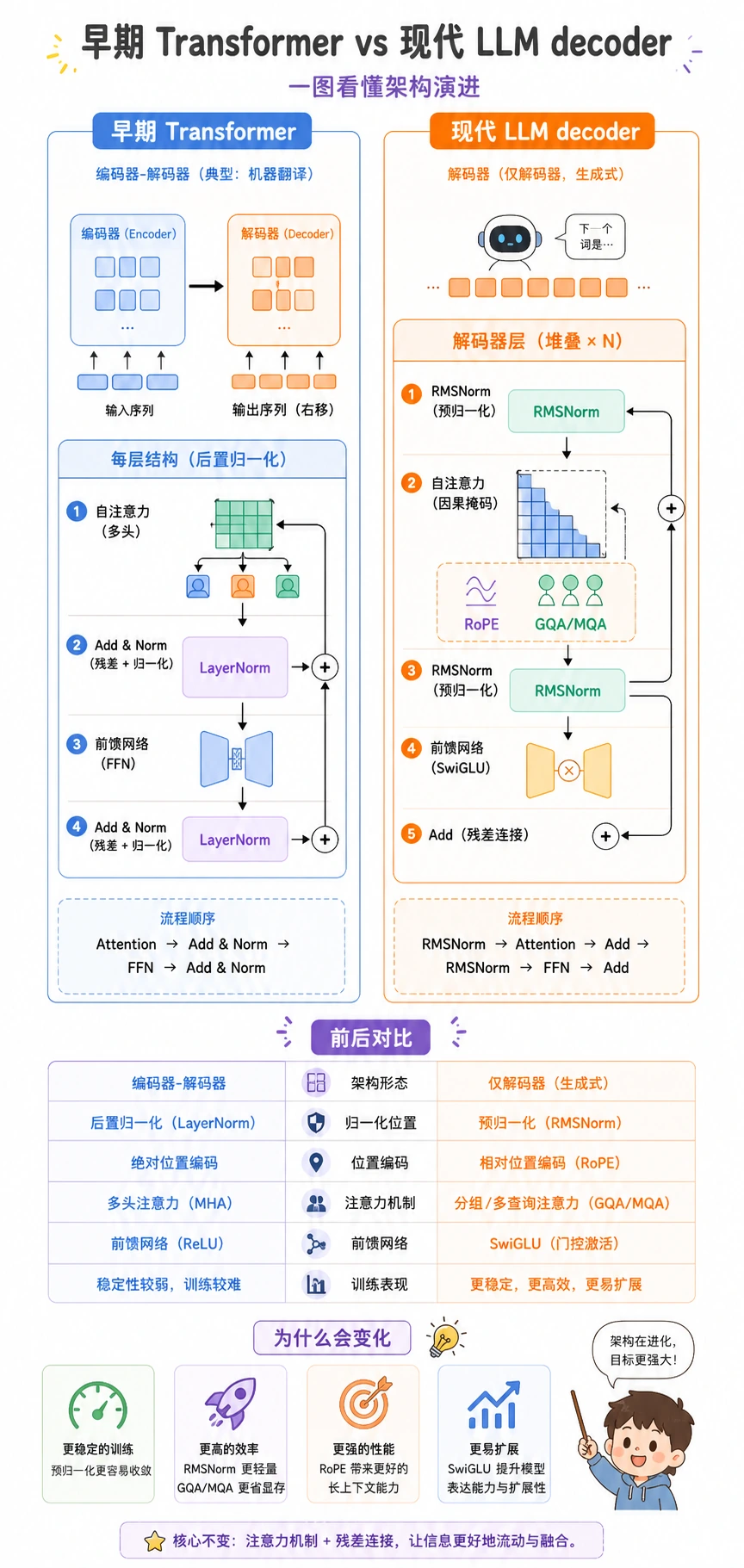
| 部分 | 早期 Transformer | 现代 LLM decoder | 为什么变化 |
|---|---|---|---|
| 归一化 | attention/FFN 后做 LayerNorm | pre-norm,常见 RMSNorm | 深层堆叠更稳定 |
| 位置信号 | absolute 或 sinusoidal position | RoPE | 更适合相对位置 |
| 注意力头 | 完整 multi-head attention | 很多模型用 GQA 或 MQA | 推理时降低 KV-cache 内存 |
| FFN | ReLU/GELU FFN | 常见 SwiGLU 门控 FFN | 扩展效果更好 |
| 架构 | 常见 encoder-decoder | 常见 decoder-only | next-token prediction 更容易规模化 |
术语白话解释:
- RMSNorm:用特征的均方根稳定尺度,通常比完整 LayerNorm 更轻。
- RoPE:把位置信息旋转进 attention 空间,让相对距离更好用。
- GQA:grouped-query attention,让多组 query head 共享 key/value head。
- MQA:multi-query attention,让多个 query head 共享一组 key/value。
- SwiGLU:带门控的 FFN,控制加工后的信息通过多少。
关键理解:
原版 Transformer 证明了 block 模式。
现代 LLM decoder 调整了 block,让超深生成模型更容易训练和推理。
常见错误
| 错误 | 修复 |
|---|---|
| 以为 Transformer 只有注意力 | 同时看残差、归一化、FFN 和位置信息 |
| 只看 tensor shape | 记住 shape 不变时,表示内容也可能已经变了 |
| 混淆 encoder 和 decoder | 看未来 token 是否可见,以及有没有 cross-attention |
忽略 batch_first | 总是确认张量是 [batch, seq, dim] 还是 [seq, batch, dim] |
| 把现代 LLM block 当作 2017 原版 block | 学会 pre-norm、RMSNorm、RoPE、GQA/MQA 和门控 FFN |
练习
- 在实验 4 中把
d_model改成32。还有哪些参数必须跟着改? - 在实验 1 中设置
norm_first=False。这代表哪一种架构模式? - 解释为什么 FFN 内部扩展了维度,但输出 shape 仍然和输入一样。
- 在实验 5 中把
target长度从3改成4。causal_mask必须怎样变化? - 用一段话解释 GQA/MQA 为什么能帮助推理内存。
小结
- Transformer block 是注意力加上一整套稳定与变换机制。
- 残差连接保留旧信息,让层只需学习更新量。
- 归一化让深层堆叠更容易训练。
- FFN 在注意力混合上下文之后,继续加工每个 token。
- 现代 LLM decoder 保留 Transformer 思路,但针对规模化和推理效率做了优化。