6.1.1 神经网络路线图:线性层、激活、损失、更新
神经网络不神秘。层先做加权求和,再用激活函数改变信号形状,训练时再调整权重以降低 loss。
先看流程
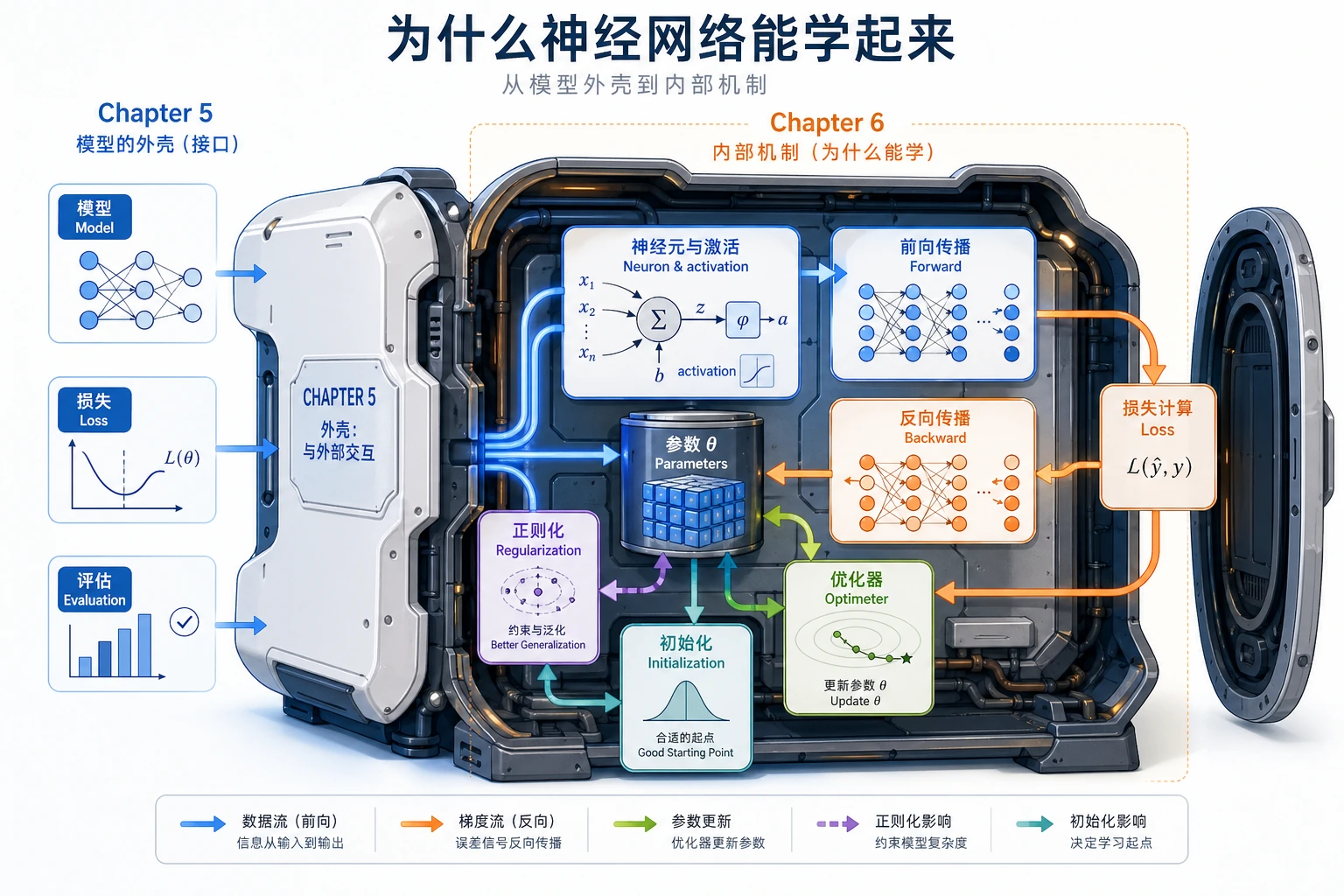
记住这个闭环:
输入 -> 加权求和 -> 激活 -> loss -> 梯度 -> 更新权重
| 词 | 第一层意思 |
|---|---|
| 神经元 | 加权求和加偏置 |
| 激活函数 | ReLU 等非线性变化 |
| 前向传播 | 计算预测 |
| 反向传播 | 计算谁该为误差负责 |
| 优化器 | 用梯度更新权重 |
跑一个神经元
创建 nn_first_loop.py,安装 torch 后运行。
import torch
x = torch.tensor([[1.0, -2.0, 3.0]])
weights = torch.tensor([[0.5], [-1.0], [0.25]])
bias = torch.tensor([0.1])
linear_output = x @ weights + bias
activated = torch.relu(linear_output)
print("linear_output:", round(linear_output.item(), 3))
print("relu_output:", round(activated.item(), 3))
预期输出:
linear_output: 3.35
relu_output: 3.35
如果线性输出是负数,ReLU 会把它变成 0。这个小门控让多层网络能表达非线性模式。
按这个顺序学
| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 6.1.2 从 ML 到 DL | sklearn 之后发生了什么变化 |
| 2 | 6.1.3 神经元与激活 | 加权求和、偏置、ReLU |
| 3 | 6.1.4 前向与反向传播 | 预测、loss、梯度 |
| 4 | 6.1.5 优化器 | SGD、Momentum、Adam 直觉 |
| 5 | 6.1.6 正则化 | 控制过拟合 |
| 6 | 6.1.7 权重初始化 | 稳定起点 |
| 7 | 6.1.8 可选历史背景 | backprop、CNN、RNN、Attention、Transformer 为什么出现 |
通过标准
能把一层解释成 input @ weights + bias,说清激活函数做什么,并把 loss、梯度、优化器连成一个训练闭环,就算通过。