6.1.8 可选背景:深度学习历史突破
本节定位
这页是简短地图,不是历史考试。看到每个模型名时,只要能回答一个问题:
它解决了上一代方法没解决好的什么问题?
先看时间线
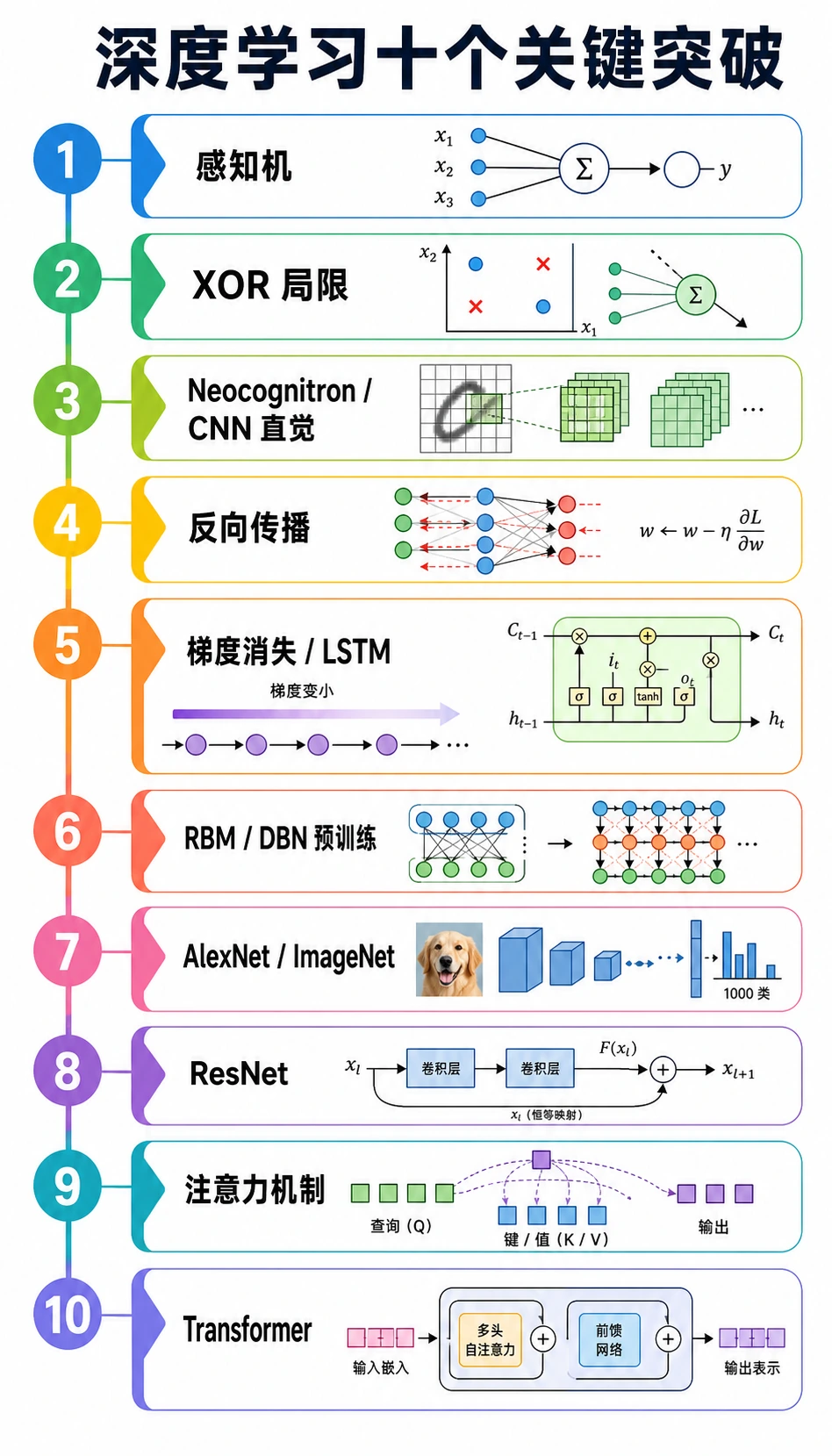
把时间线读成一条链:
简单神经元 -> 线性模型局限 -> 可训练的多层网络 -> 稳定训练深层网络 -> 可扩展视觉模型 -> 基于注意力的序列建模
只要记住这条链,第 6 章后面的架构就不会像一堆孤立名词。
三次大变化
| 变化 | 当时的希望 | 主要瓶颈 | 推动下一阶段的关键 |
|---|---|---|---|
| 早期神经网络 | 机器可以从数据中学习 | 单层模型太弱 | 隐藏层和反向传播 |
| 可训练的深层网络 | 多层模型可以学习表示 | 梯度消失、数据和算力不足 | LSTM、初始化、预训练思想 |
| 现代深度学习 | 数据、GPU、架构一起扩展 | 很深的模型和长依赖很难训 | AlexNet、ResNet、Attention、Transformer |
这也是为什么第 6 章先讲基础,再讲架构:
| 看到这个历史问题 | 回看本课程位置 |
|---|---|
| 单个神经元太弱 | 6.1.3 神经元与激活函数 |
| 多层网络需要梯度 | 6.1.4 前向与反向传播 |
| 训练容易不稳定 | 6.1.5 优化器、6.1.6 正则化、6.1.7 初始化 |
| 图像需要局部特征 | 第 6 章后面的 CNN 部分 |
| 序列需要记忆或注意力 | RNN、LSTM、Attention、Transformer 部分 |
十个要记住的突破
| 时间 | 突破 | 解决的问题 | 对课程的意义 |
|---|---|---|---|
| 1943-1958 | 人工神经元与感知器 | 让机器从样本学习参数成为可能 | 神经元就是加权求和再判断 |
| 1969 | XOR 局限 | 说明单层线性模型不够 | 隐藏层和非线性激活很重要 |
| 1980 | 新认知机 | 提前引入局部视觉特征和层级结构 | CNN 先看局部模式 |
| 1986 | 反向传播 | 让多层网络可以训练 | loss.backward() 是这个思想的现代形式 |
| 1989 | 通用逼近 | 说明非线性网络能表示复杂函数 | 表达能力需要深度和激活 |
| 1994-1997 | 梯度消失与 LSTM | 让长序列记忆更可行 | 门控帮助信息跨时间保留 |
| 2006 | RBM / DBN 预训练 | 重新激活深层表示学习路线 | 预训练成为重要思想 |
| 2012 | AlexNet / ImageNet | 证明数据 + GPU + CNN 能打穿视觉任务 | 大规模训练改变计算机视觉 |
| 2015 | ResNet | 让很深的 CNN 更容易训练 | 残差路径帮助梯度流动 |
| 2017 | Attention / Transformer | 让长距离序列建模可并行、可扩展 | 现代大语言模型的底座 |
每个名字该触发什么直觉
用这张小表快速记:
| 名字 | 先想到 |
|---|---|
| 感知器 | 可学习的线性打分 |
| XOR | 线性边界有局限 |
| 反向传播 | 沿计算图分配错误 |
| LSTM / GRU | 用门控记住长序列 |
| AlexNet | GPU 规模 CNN 突破 |
| ResNet | 深层网络的跳连路径 |
| Attention | 每个 token 可以看相关 token |
| Transformer | 大规模堆叠注意力模块 |
学习时怎么用这页
不用背每个年份。学完第 6 章每个架构小节后,做三件事:
- 用一句话写出旧瓶颈。
- 用一句话写出新机制。
- 运行本章实验,并指出哪一行代码体现了这个机制。
例子:
旧瓶颈:深层 CNN 很难优化。
新机制:ResNet 加了捷径路径。
代码线索:output = block(x) + x
这样历史就不会停留在名词上,而会和实现连起来。
快速检查
能回答下面问题,就可以继续:
- 为什么 XOR 暴露了单层模型的局限?
- 为什么反向传播对多层网络重要?
- 为什么 LSTM 出现在 Transformer 之前?
- 为什么 ResNet 能帮助很深的 CNN?
- 为什么 Attention 会成为现代大语言模型的桥?
如果你的回答是从“因为上一代模型不能……”开始,说明你正在用正确方式读历史。