6.1.5 优化器
本节概览
梯度算出来以后,优化器决定参数怎么移动。优化器名字很重要,但学习率往往更重要。
你会做出什么
这一节会运行一个很小的 PyTorch 优化实验:
- 在同一个简单 loss 上比较 SGD、Momentum 和 Adam;
- 直接看到过冲;
- 测试学习率敏感性;
- 学会安全的优化器选择顺序。
环境准备
python -m pip install -U torch
运行完整实验
新建 optimizer_lab.py:
import torch
def run_optimizer(name, optimizer_factory, steps=25):
torch.manual_seed(42)
w = torch.nn.Parameter(torch.tensor([5.0]))
optimizer = optimizer_factory([w])
for step in range(1, steps + 1):
loss = (w - 2).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step in [1, 5, 10, 25]:
print(f"{name:<8} step={step:<2} w={w.item():.3f} loss={loss.item():.4f}")
print("optimizer_comparison")
run_optimizer("sgd", lambda params: torch.optim.SGD(params, lr=0.1))
run_optimizer("momentum", lambda params: torch.optim.SGD(params, lr=0.1, momentum=0.9))
run_optimizer("adam", lambda params: torch.optim.Adam(params, lr=0.1))
print("learning_rate_check")
for lr in [0.01, 0.1, 1.1]:
torch.manual_seed(42)
w = torch.nn.Parameter(torch.tensor([5.0]))
optimizer = torch.optim.SGD([w], lr=lr)
for _ in range(10):
loss = (w - 2).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
final_loss = (w - 2).pow(2).item()
print(f"lr={lr:<4} final_w={w.item():.3f} final_loss={final_loss:.4f}")
运行:
python optimizer_lab.py
预期输出:
optimizer_comparison
sgd step=1 w=4.400 loss=9.0000
sgd step=5 w=2.983 loss=1.5099
sgd step=10 w=2.322 loss=0.1621
sgd step=25 w=2.011 loss=0.0002
momentum step=1 w=4.400 loss=9.0000
momentum step=5 w=0.259 loss=0.8571
momentum step=10 w=2.013 loss=0.6767
momentum step=25 w=2.475 loss=0.0200
adam step=1 w=4.900 loss=9.0000
adam step=5 w=4.502 loss=6.7648
adam step=10 w=4.014 loss=4.4535
adam step=25 w=2.739 loss=0.6569
learning_rate_check
lr=0.01 final_w=4.451 final_loss=6.0085
lr=0.1 final_w=2.322 final_loss=0.1038
lr=1.1 final_w=20.575 final_loss=345.0386
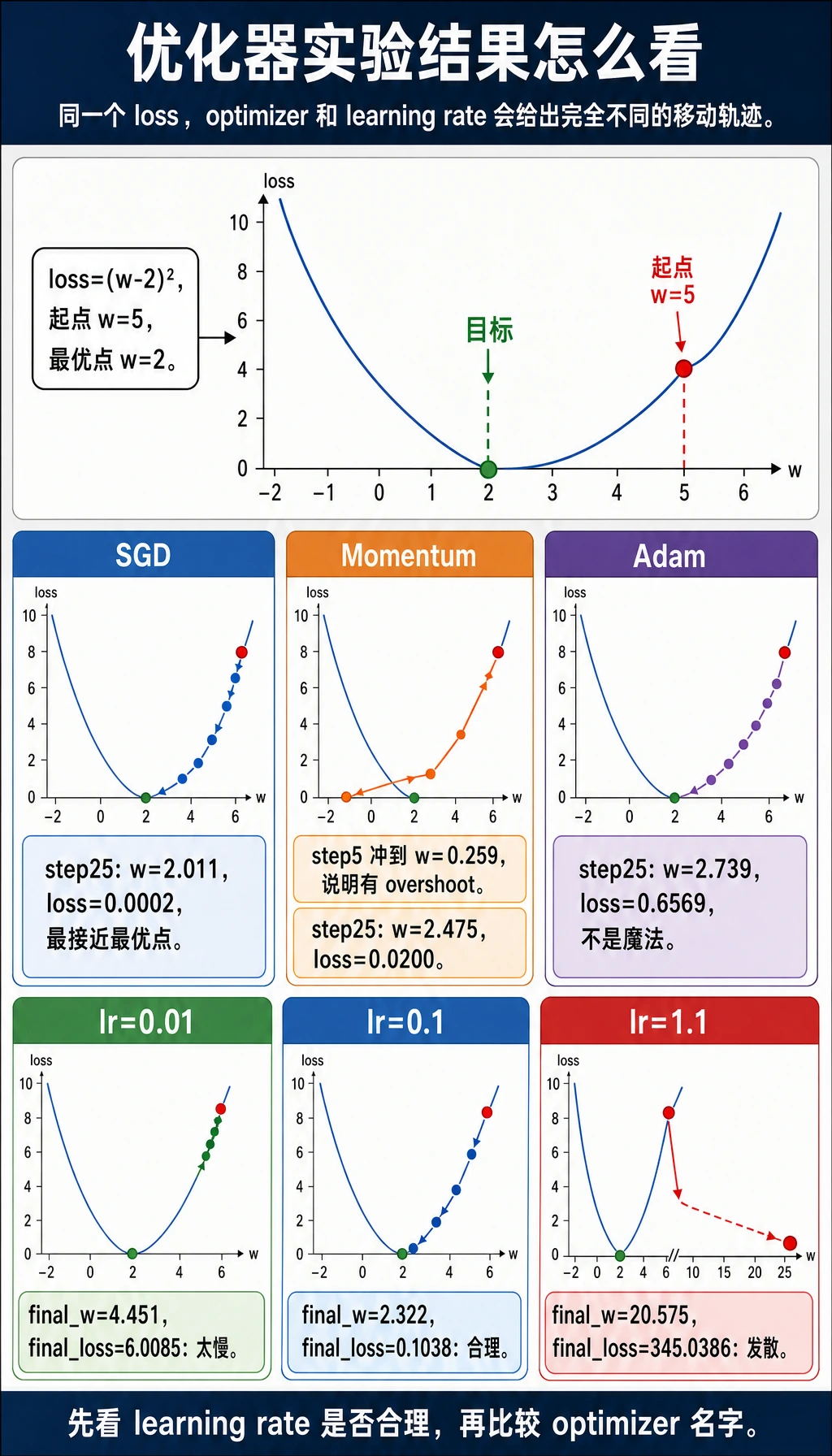
读懂实验
这里的 loss 是:
loss = (w - 2)^2
最佳值是 w=2。所有优化器都从 w=5 出发。
在这个简单例子里,学习率合适的 SGD 表现非常好:
sgd step=25 w=2.011 loss=0.0002
Momentum 移动更快,但可能过冲:
momentum step=5 w=0.259
Adam 是深度学习里很常见的默认选择,但不是魔法。在这个小问题上,lr=0.1 的 Adam 反而比调好的 SGD 慢。重点不是“Adam 不好”,而是:
一定要看训练行为。优化器选择和学习率是一起工作的。
学习率是第一个旋钮
学习率实验故意很直接:
lr=0.01 final_w=4.451 final_loss=6.0085
lr=0.1 final_w=2.322 final_loss=0.1038
lr=1.1 final_w=20.575 final_loss=345.0386
太小:训练很慢。
合适:逐渐接近最优点。
太大:训练发散。
优化器直觉
| 优化器 | 直觉 | 适合先用在 |
|---|---|---|
| SGD | 直接沿负梯度方向移动 | 简单基线、受控实验 |
| SGD + Momentum | 保留之前步骤的速度 | 噪声方向上更平滑 |
| Adam | 根据梯度历史自适应步长 | 很多神经网络的强默认选择 |
真实神经网络里,Adam 或 AdamW 经常是实用起点。最终训练仍然要看任务验证指标。
实用选择顺序
- 神经网络基线先用 Adam 或 AdamW。
- 先调学习率,再争论优化器名字。
- 观察训练 loss 和验证 loss 曲线。
- 如果验证不稳定,降低 LR 或加入 schedule。
- 如果训练慢但稳定,尝试 LR schedule 或更换优化器。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| loss 爆炸 | 学习率太高 | 降低 LR |
| loss 下降很慢 | LR 太低或输入尺度差 | 谨慎提高 LR,归一化输入 |
| training loss 降低但 validation 变差 | 过拟合 | 正则化、加数据、早停 |
| loss 来回震荡 | momentum/LR 太激进 | 降低 LR 或 momentum |
| Adam 能跑但最终效果弱 | 优化器掩盖了其他问题 | 检查数据、结构、正则化 |
练习
- 把 SGD 学习率改成
0.05、0.2、0.8。 - 把 momentum 从
0.9改成0.5。过冲是否减少? - 用
AdamW替换Adam。 - 每一步打印
w.grad,把梯度和更新联系起来。 - 为每个优化器画出
w随 step 的变化。
过关检查
你能解释下面几点,就完成本节:
- 梯度说明哪个方向会改变 loss;
- 优化器决定参数走多远;
- 学习率会让训练变慢、收敛或发散;
- momentum 可以加速,但也可能过冲;
- Adam 有用,但不能替代观察训练曲线。