6.2.1 PyTorch 路线图:Tensor、Autograd、Module、DataLoader、Loop
PyTorch 把深度学习闭环变成可运行代码。先学执行顺序,再补细节会轻松很多。
先看工作流
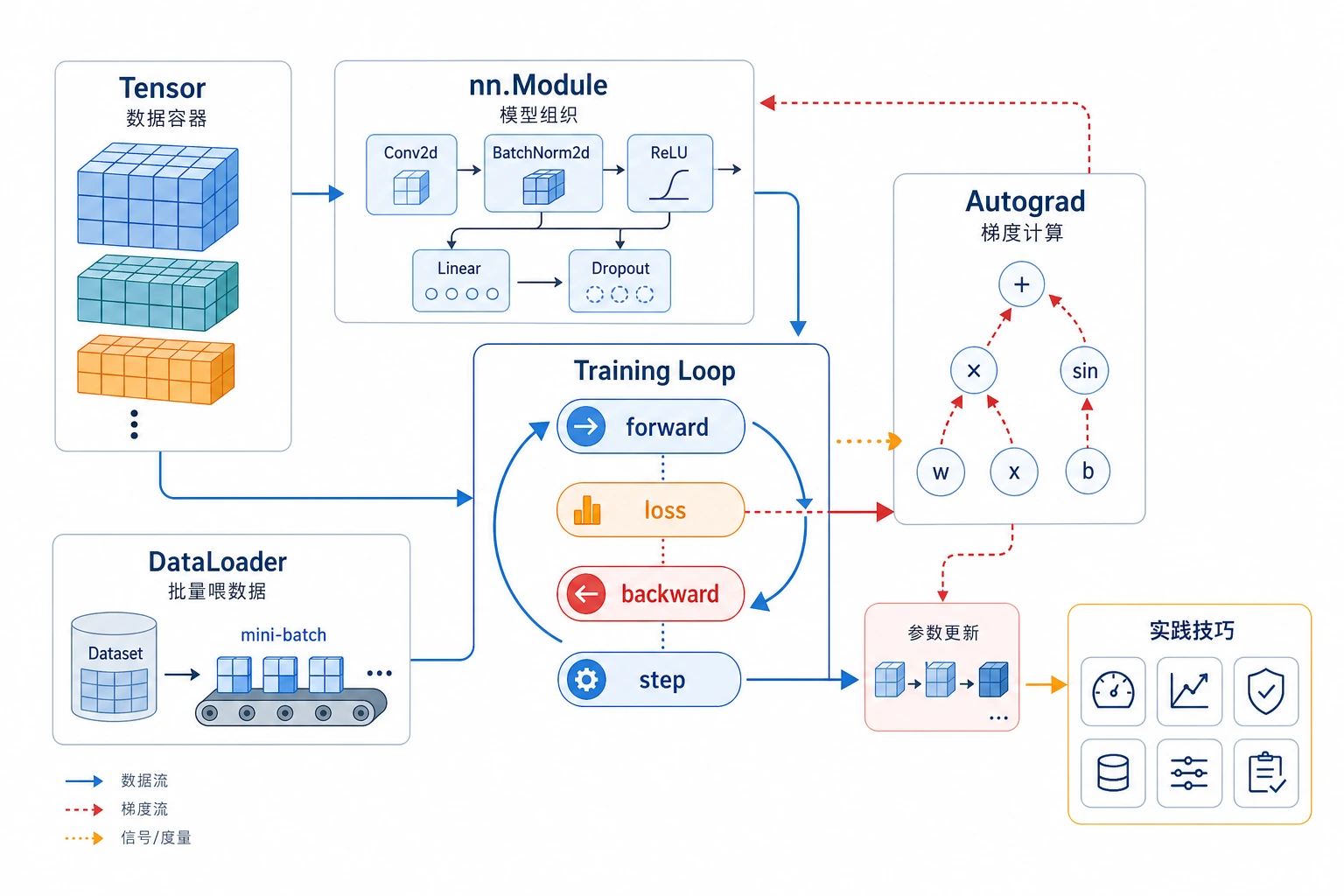
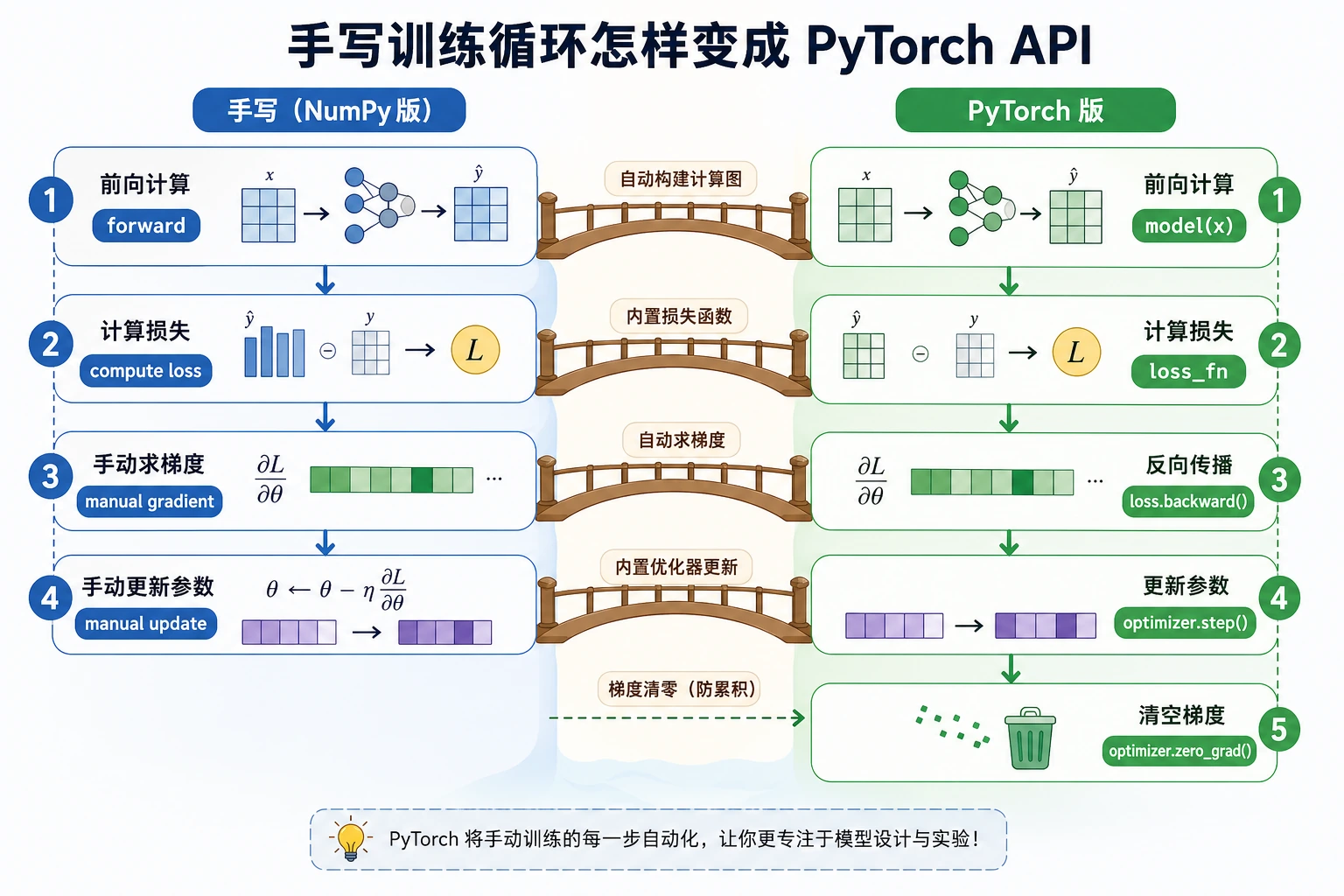
tensor -> model -> loss -> backward -> optimizer.step -> repeat
跑一次 Autograd
创建 pytorch_first_loop.py,安装 torch 后运行。
import torch
w = torch.tensor([0.0], requires_grad=True)
learning_rate = 0.2
for step in range(1, 5):
loss = (w - 3).pow(2)
loss.backward()
with torch.no_grad():
w -= learning_rate * w.grad
w.grad.zero_()
print(step, "w=", round(w.item(), 3), "loss=", round(loss.item(), 3))
预期输出:
1 w= 1.2 loss= 9.0
2 w= 1.92 loss= 3.24
3 w= 2.352 loss= 1.166
4 w= 2.611 loss= 0.42
这里能看到 PyTorch 的关键习惯:计算 loss,调用 backward(),在不跟踪梯度的区域更新参数,然后清空旧梯度。
按这个顺序学
| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 6.2.2 从 sklearn 到 PyTorch | 为什么训练循环变得显式 |
| 2 | 6.2.3 PyTorch 基础 | tensor、dtype、shape、device |
| 3 | 6.2.4 Autograd | requires_grad、backward、grad |
| 4 | 6.2.5 nn Module | 模型类、参数 |
| 5 | 6.2.6 数据加载 | Dataset、DataLoader、batch |
| 6 | 6.2.7 训练循环 | train/eval 循环、loss 记录 |
| 7 | 6.2.8 实用技巧 | shape、device、seed、调试 |
| 8 | 6.2.9 PyTorch 工作坊 | 运行并可视化小模型 |
通过标准
能读懂一个 PyTorch 循环,并定位数据 batch、模型输出、loss、backward() 和 optimizer 更新这五件事,就算通过。