6.2.7 训练循环
本节定位
这是 PyTorch 工作流真正合起来的一页:batch、前向、loss、清梯度、反向、更新、验证、保留最佳模型、预测。
学习目标
- 写出完整 PyTorch 训练循环。
- 正确使用
model.train()、model.eval()、torch.no_grad()和 device 转移。 - 按样本数计算训练/验证平均 loss。
- 在内存中保留最佳验证 checkpoint。
- 训练后运行预测。
先看循环结构
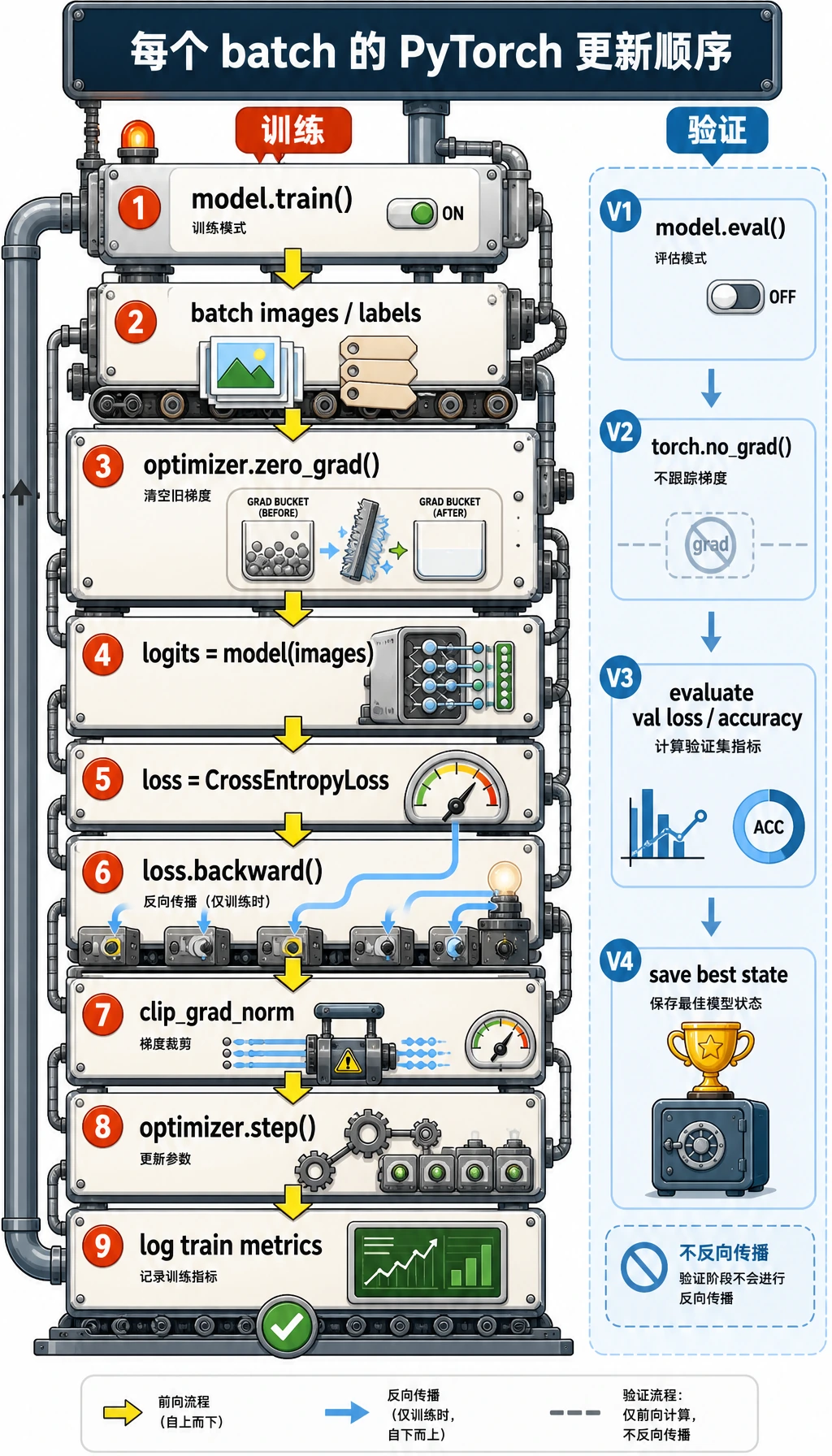
训练节奏是:
batch -> forward -> loss -> zero_grad -> backward -> optimizer.step -> repeat
验证节奏不同:
eval mode -> no_grad -> forward -> loss/metrics -> no update
为什么训练循环重要?
sklearn.fit() 会隐藏大部分训练过程。PyTorch 把它暴露出来,是因为深度学习项目常常需要自定义模型、自定义 loss、自定义 batch 逻辑、GPU 控制、日志和 checkpoint。
同一条主线会出现在:
- 图像分类;
- 文本分类;
- 目标检测;
- 微调;
- RAG reranker 训练;
- 多模态模型。
架构会变,但这条循环长期稳定。
完整可运行训练脚本
这个脚本会在合成数据上训练一个小型回归模型:
y ~= 3*x1 + 2*x2 + 5
它包含 device、训练/验证切分、平均 loss、最佳 checkpoint 和最终预测。
import copy
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset, random_split
torch.manual_seed(42)
# 1. 构造一个可直接运行的小型合成数据集
X = torch.randn(240, 2)
noise = torch.randn(240, 1) * 0.3
y = 3 * X[:, [0]] + 2 * X[:, [1]] + 5 + noise
dataset = TensorDataset(X, y)
train_dataset, val_dataset = random_split(
dataset,
[192, 48],
generator=torch.Generator().manual_seed(42),
)
train_loader = DataLoader(
train_dataset,
batch_size=32,
shuffle=True,
generator=torch.Generator().manual_seed(7),
)
val_loader = DataLoader(val_dataset, batch_size=48, shuffle=False)
# 2. 选择 device
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
class Regressor(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1),
)
def forward(self, x):
return self.net(x)
model = Regressor().to(device)
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
def run_epoch(loader, train):
if train:
model.train()
else:
model.eval()
total_loss = 0.0
context = torch.enable_grad() if train else torch.no_grad()
with context:
for batch_x, batch_y in loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
if train:
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * len(batch_x)
return total_loss / len(loader.dataset)
best_val = float("inf")
best_state = None
print("training_loop_lab")
for epoch in range(1, 81):
train_loss = run_epoch(train_loader, train=True)
val_loss = run_epoch(val_loader, train=False)
if val_loss < best_val:
best_val = val_loss
best_state = copy.deepcopy(model.state_dict())
if epoch == 1 or epoch % 20 == 0:
print(
f"epoch={epoch:3d} "
f"train_loss={train_loss:.4f} "
f"val_loss={val_loss:.4f}"
)
model.load_state_dict(best_state)
model.eval()
test_x = torch.tensor([[1.0, 2.0], [-1.0, 0.5], [0.0, 0.0]], device=device)
with torch.no_grad():
preds = model(test_x).cpu()
print("best_val:", round(best_val, 4))
print("predictions:")
for row, pred in zip(test_x.cpu(), preds):
print(f"x={row.tolist()} -> pred={pred.item():.2f}")
预期输出:
training_loop_lab
epoch= 1 train_loss=34.8472 val_loss=25.3358
epoch= 20 train_loss=0.1022 val_loss=0.0856
epoch= 40 train_loss=0.0950 val_loss=0.0776
epoch= 60 train_loss=0.0972 val_loss=0.0760
epoch= 80 train_loss=0.0936 val_loss=0.0776
best_val: 0.0734
predictions:
x=[1.0, 2.0] -> pred=12.05
x=[-1.0, 0.5] -> pred=3.00
x=[0.0, 0.0] -> pred=4.98

无噪声真实值是 12、3、5,所以预测已经很接近。
逐步拆解
| 步骤 | 代码 | 为什么需要 |
|---|---|---|
| device | model.to(device), batch_x.to(device) | 模型和数据必须在同一设备 |
| 模式 | model.train() / model.eval() | Dropout 和 BatchNorm 会按模式变化 |
| 前向 | pred = model(batch_x) | 当前参数做预测 |
| loss | loss_fn(pred, batch_y) | 计算错误 |
| 清空 | optimizer.zero_grad() | 清掉旧的累积梯度 |
| 反向 | loss.backward() | 计算梯度 |
| 更新 | optimizer.step() | 修改参数 |
| 验证 | torch.no_grad() | 评估时不记录梯度 |
| checkpoint | copy.deepcopy(model.state_dict()) | 保留最佳权重,而不是指向还在变化的引用 |
copy.deepcopy 这个细节很重要。如果直接写 best_state = model.state_dict(),你可能保留的是仍会继续变化的 tensor 引用。
为什么按样本数平均 loss?
每个 batch 内部的 loss.item() 已经是 batch 平均值。如果最后一个 batch 更小,直接平均 batch loss 会有一点偏差。
所以脚本使用:
total_loss += loss.item() * len(batch_x)
average_loss = total_loss / len(loader.dataset)
这样得到的是整个数据集的按样本平均 loss。
常见变体
| 任务 | 输出 | 常见 loss |
|---|---|---|
| 回归 | [batch, 1] | nn.MSELoss() 或 nn.L1Loss() |
| 多分类 | [batch, classes] logits | nn.CrossEntropyLoss() |
| 二分类 | [batch, 1] logits | nn.BCEWithLogitsLoss() |
分类任务除了 loss,还常看:
- accuracy;
- 类别不均衡时看 precision/recall/F1;
- 类别容易混淆时看 confusion matrix。
排错清单
训练表现奇怪时,按顺序查:
- 一个 batch 的 shape:
batch_x能接上第一层吗? - 标签 shape 和 dtype:
batch_y能接上 loss 函数吗? - Device:模型和数据在同一设备吗?
- Loss:是有限数,还是
nan/inf? - 梯度:关键参数有没有非
None的梯度? - 更新:
optimizer.step()后参数真的变了吗? - 验证:是否用了
model.eval()和torch.no_grad()?
有用的小探针:
print(batch_x.shape, batch_y.shape)
print(batch_x.device, next(model.parameters()).device)
print("loss:", loss.item())
for name, param in model.named_parameters():
if param.grad is not None:
print(name, param.grad.norm().item())
break
可保存模板
for epoch in range(num_epochs):
model.train()
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
val_loss = loss_fn(pred, batch_y)
练习
- 把 optimizer 从
Adam改成SGD(lr=0.05)。收敛有什么变化? - 把隐藏层大小从
16改成4和32,比较训练和验证 loss。 - 把噪声从
0.3改成1.0。最佳验证 loss 会发生什么? - 增加一个
best_epoch变量,打印哪个 epoch 产生了最佳验证 loss。 - 把任务改成二分类:用
y > 5生成标签,再使用BCEWithLogitsLoss。
小结
- 训练循环是闭环:预测、衡量错误、计算梯度、更新、验证。
- 训练和验证必须使用不同模式。
zero_grad -> backward -> step是核心更新顺序。- batch 大小不完全一致时,按样本数平均 loss。
- 用复制后的
state_dict保留最佳 checkpoint,再在预测前恢复它。