6.2.9 PyTorch + Matplotlib 实操工作坊
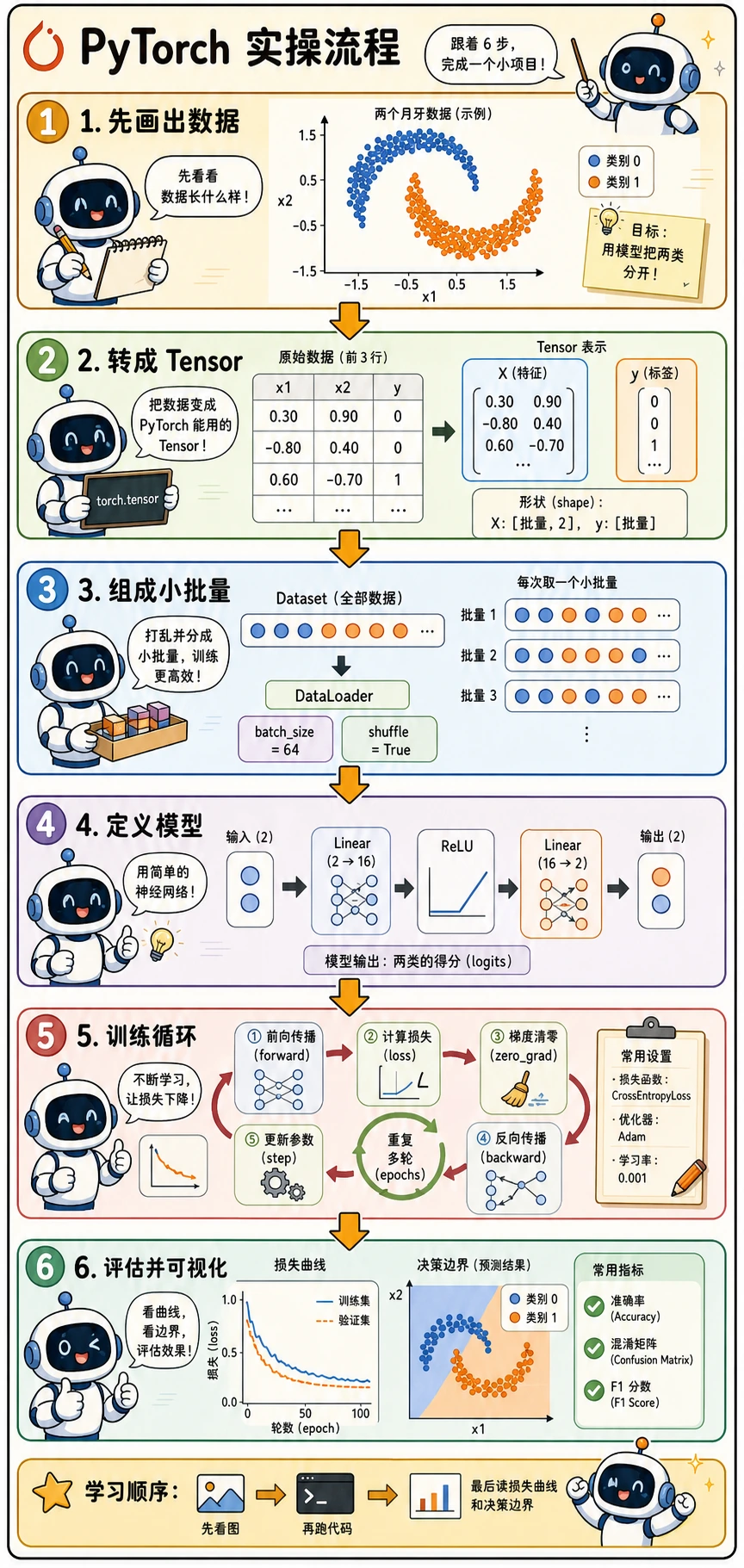
把本节当作第一个完整 PyTorch 小项目。推荐节奏是: 先看图 → 再跑代码 → 最后读损失曲线和决策边界。
如果这是你第一次做第 6 章实验,请在项目根目录安装 AI 依赖:
python -m pip install -r requirements-course-ai.txt
如果只想运行本节工作坊,最少额外需要 torch;matplotlib 和 scikit-learn 已经包含在课程核心依赖里。
你将完成什么
你会训练一个小型神经网络,用来区分两组“月牙形”的点。这个任务很小,运行很快,但包含完整 PyTorch 工作流:
- 用 Matplotlib 可视化数据
- 把 NumPy 数组转成 PyTorch Tensor
- 构建
TensorDataset和DataLoader - 定义一个
nn.Module - 使用
CrossEntropyLoss和Adam训练 - 评估准确率
- 绘制损失曲线和决策边界
关键词解释
| 术语 | 新人友好解释 | 为什么这里重要 |
|---|---|---|
| Matplotlib | Python 基础绘图库 | 用来查看数据、损失曲线和决策边界 |
| Tensor | PyTorch 的多维数组 | 模型只能训练 Tensor 格式的数据 |
Dataset | 定义一个样本长什么样 | 保证数据和标签正确配对 |
DataLoader | 把样本组成小批量 | 让训练循环一批一批读取数据 |
| MLP | 多层感知机,小型全连接神经网络 | 很适合第一个 2D 或表格任务 |
| logits | 转成概率之前的原始模型分数 | CrossEntropyLoss 需要 logits,而不是 softmax 概率 |
| epoch | 完整看完训练集一遍 | 用来记录训练进行了多少轮 |
| 决策边界 | 模型从一个类别切换到另一个类别的位置 | 可以直观看出分类行为 |
先创建并画出数据
写模型前先看数据。这能避免一个常见新手错误:还不知道模型要学什么形状,就直接开始训练。
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
X_np, y_np = make_moons(n_samples=600, noise=0.18, random_state=42)
plt.figure(figsize=(6, 5))
plt.scatter(X_np[:, 0], X_np[:, 1], c=y_np, cmap="coolwarm", s=18, alpha=0.8)
plt.xlabel("x1")
plt.ylabel("x2")
plt.title("Two Moons Dataset")
plt.grid(True, alpha=0.3)
plt.show()
你应该注意:
- 两类点不能用一条直线分开
- 所以带非线性的神经网络会有用
- 这张图也是后面判断决策边界是否合理的参照
转成 Tensor
PyTorch 模型需要 Tensor。对于 CrossEntropyLoss 使用的分类标签,y 应该是整数类别编号,并且类型是 torch.long。
import torch
torch.manual_seed(42)
X = torch.tensor(X_np, dtype=torch.float32)
y = torch.tensor(y_np, dtype=torch.long)
print("X shape:", X.shape, "dtype:", X.dtype)
print("y shape:", y.shape, "dtype:", y.dtype)
预期输出:
X shape: torch.Size([600, 2]) dtype: torch.float32
y shape: torch.Size([600]) dtype: torch.int64
形状含义:
X:[batch, features],每个样本有 2 个特征y:[batch],每个值是类别标签:0或1
构建 Dataset 和 DataLoader
TensorDataset 会让 X 和 y 保持配对。DataLoader 负责打乱数据并组成小批量。
from torch.utils.data import DataLoader, TensorDataset, random_split
dataset = TensorDataset(X, y)
train_dataset, val_dataset = random_split(
dataset,
[480, 120],
generator=torch.Generator().manual_seed(42)
)
train_loader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True,
generator=torch.Generator().manual_seed(7)
)
val_loader = DataLoader(val_dataset, batch_size=128, shuffle=False)
batch_x, batch_y = next(iter(train_loader))
print("batch_x shape:", batch_x.shape)
print("batch_y shape:", batch_y.shape)
为什么这一步重要:
batch_size=64表示模型每看 64 个样本更新一次shuffle=True避免模型每轮都按固定顺序看数据- 验证集不需要打乱,因为它只用于评估
定义一个小型神经网络
这个模型把一个二维点映射为两个 logits,每个类别一个分数。
from torch import nn
class MoonClassifier(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(32, 2),
)
def forward(self, x):
return self.net(x)
model = MoonClassifier()
print(model)
重要细节:
- 最后一层输出
2个值,因为这是二分类任务 - 不要在这里加
Softmax,因为nn.CrossEntropyLoss()需要原始 logits
训练和验证
训练循环遵循前面学过的节奏:
forward → loss → zero_grad → backward → step
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(1, 101):
model.train()
train_loss_sum = 0.0
for batch_x, batch_y in train_loader:
logits = model(batch_x)
loss = loss_fn(logits, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_sum += loss.item() * len(batch_x)
train_loss = train_loss_sum / len(train_dataset)
train_losses.append(train_loss)
model.eval()
val_loss_sum = 0.0
correct = 0
with torch.no_grad():
for batch_x, batch_y in val_loader:
logits = model(batch_x)
loss = loss_fn(logits, batch_y)
val_loss_sum += loss.item() * len(batch_x)
pred = logits.argmax(dim=1)
correct += (pred == batch_y).sum().item()
val_loss = val_loss_sum / len(val_dataset)
val_acc = correct / len(val_dataset)
val_losses.append(val_loss)
val_accuracies.append(val_acc)
if epoch == 1 or epoch % 20 == 0:
print(
f"epoch={epoch:3d}, "
f"train_loss={train_loss:.4f}, "
f"val_loss={val_loss:.4f}, "
f"val_acc={val_acc:.1%}"
)
预期输出:
epoch= 1, train_loss=0.5568, val_loss=0.3786, val_acc=84.2%
epoch= 20, train_loss=0.0755, val_loss=0.1064, val_acc=98.3%
epoch= 40, train_loss=0.0719, val_loss=0.1260, val_acc=98.3%
epoch= 60, train_loss=0.0657, val_loss=0.1290, val_acc=98.3%
epoch= 80, train_loss=0.0655, val_loss=0.1415, val_acc=98.3%
epoch=100, train_loss=0.0687, val_loss=0.1370, val_acc=98.3%
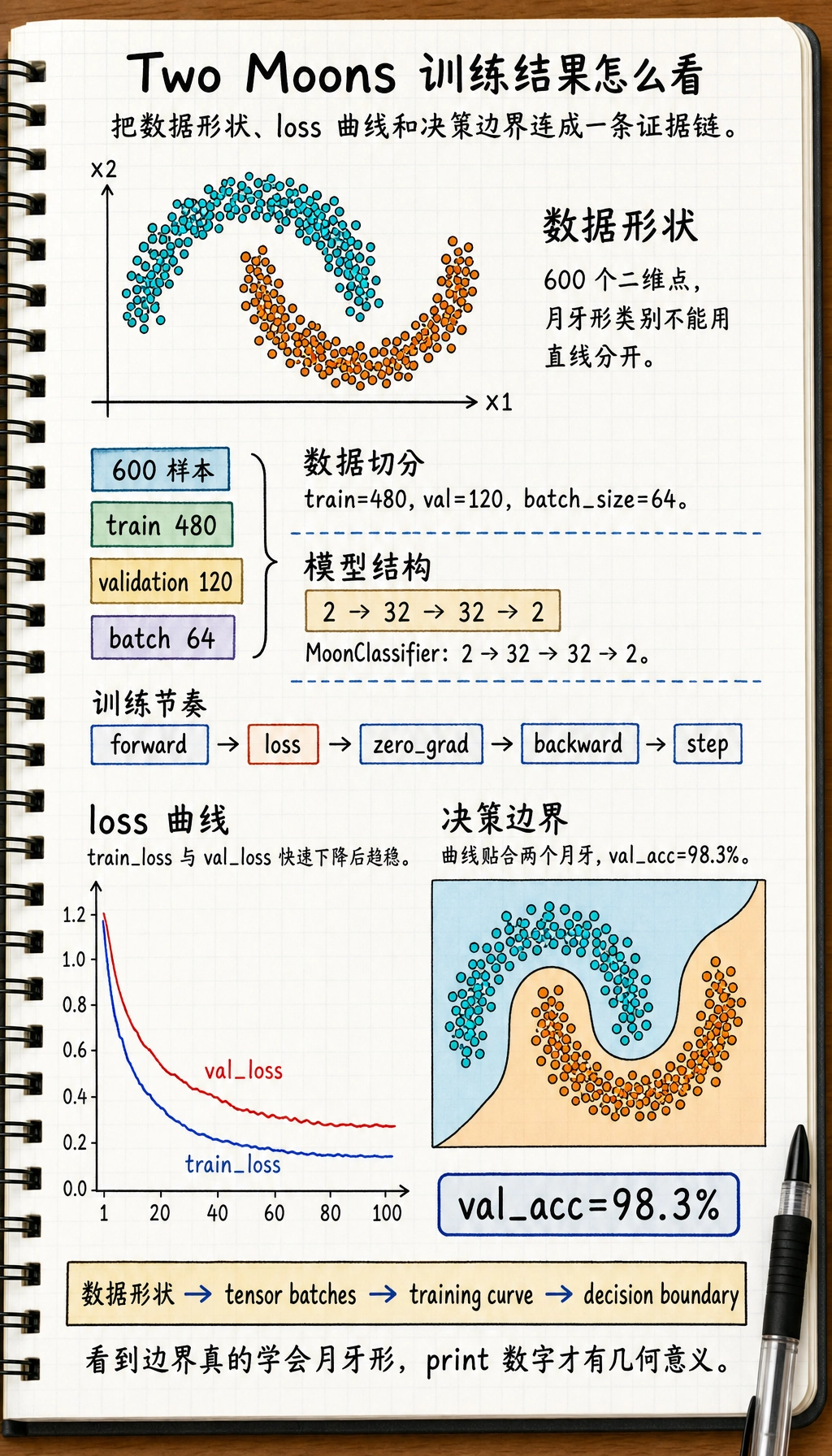
如果你的数字有轻微差异也没关系。关键是验证准确率要明显高于随机猜测。
绘制损失曲线
损失曲线能告诉你训练是否在朝正确方向走。
plt.figure(figsize=(7, 4))
plt.plot(train_losses, label="train loss")
plt.plot(val_losses, label="validation loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
如何阅读:
- 如果两条 loss 都下降,说明训练通常在学习
- 如果训练 loss 下降但验证 loss 上升,要警惕过拟合
- 如果两者都不下降,检查学习率、标签、模型输出形状和损失函数
绘制决策边界
决策边界能把模型学到的几何规律画出来。
import numpy as np
x_min, x_max = X_np[:, 0].min() - 0.5, X_np[:, 0].max() + 0.5
y_min, y_max = X_np[:, 1].min() - 0.5, X_np[:, 1].max() + 0.5
xx, yy = np.meshgrid(
np.linspace(x_min, x_max, 250),
np.linspace(y_min, y_max, 250)
)
grid = np.c_[xx.ravel(), yy.ravel()]
grid_tensor = torch.tensor(grid, dtype=torch.float32)
model.eval()
with torch.no_grad():
logits = model(grid_tensor)
grid_pred = logits.argmax(dim=1).numpy().reshape(xx.shape)
plt.figure(figsize=(7, 5))
plt.contourf(xx, yy, grid_pred, alpha=0.25, cmap="coolwarm")
plt.scatter(X_np[:, 0], X_np[:, 1], c=y_np, cmap="coolwarm", s=16, edgecolors="k", linewidths=0.2)
plt.xlabel("x1")
plt.ylabel("x2")
plt.title(f"Decision Boundary (validation accuracy {val_accuracies[-1]:.1%})")
plt.grid(True, alpha=0.2)
plt.show()
这张图通常是 PyTorch 开始变得具体的时刻:模型不再只是打印数字,你能看到它如何划分空间。
常见错误与修复
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
expected scalar type Long | 标签不是 torch.long | 使用 y = torch.tensor(y_np, dtype=torch.long) |
| Loss 不下降 | 学习率太大或太小 | 尝试 lr=0.001 或 lr=0.01 |
| 损失函数 shape 报错 | 输出或标签形状不对 | CrossEntropyLoss 中 logits 应为 [batch, classes],标签应为 [batch] |
| 验证时显存或内存占用过高 | 验证阶段仍在记录梯度 | 使用 model.eval() 和 with torch.no_grad() |
练习任务
- 把隐藏层大小从
32改成16和64,比较决策边界。 - 把
noise=0.18改成noise=0.3,观察任务如何变难。 - 把优化器从
Adam改成SGD,比较损失曲线。 - 增加第三个隐藏层,观察验证 loss 是改善还是过拟合。
通过标准
完成本节后,你应该能用自己的话解释完整 PyTorch 工作流:
数据图像 → Tensor → DataLoader → model → loss → optimizer → training loop → validation → visualization。
如果你还能读懂损失曲线和决策边界,就已经不只是复制 PyTorch 代码,而是在理解训练过程到底做了什么。