6.2.5 nn.Module
本节定位
nn.Module 是 PyTorch 把层、参数、前向逻辑、训练/评估模式打包成一个模型对象的方式。本节会把 autograd 里手写的参数升级成可复用的模型类。
学习目标
- 使用
nn.Linear并读懂它的参数 shape。 - 用
nn.Sequential搭建简单模型。 - 用
__init__()和forward()写自定义nn.Module。 - 检查
named_parameters()和state_dict()。 - 理解
model.train()和model.eval()真正切换的是什么。
先看模型容器
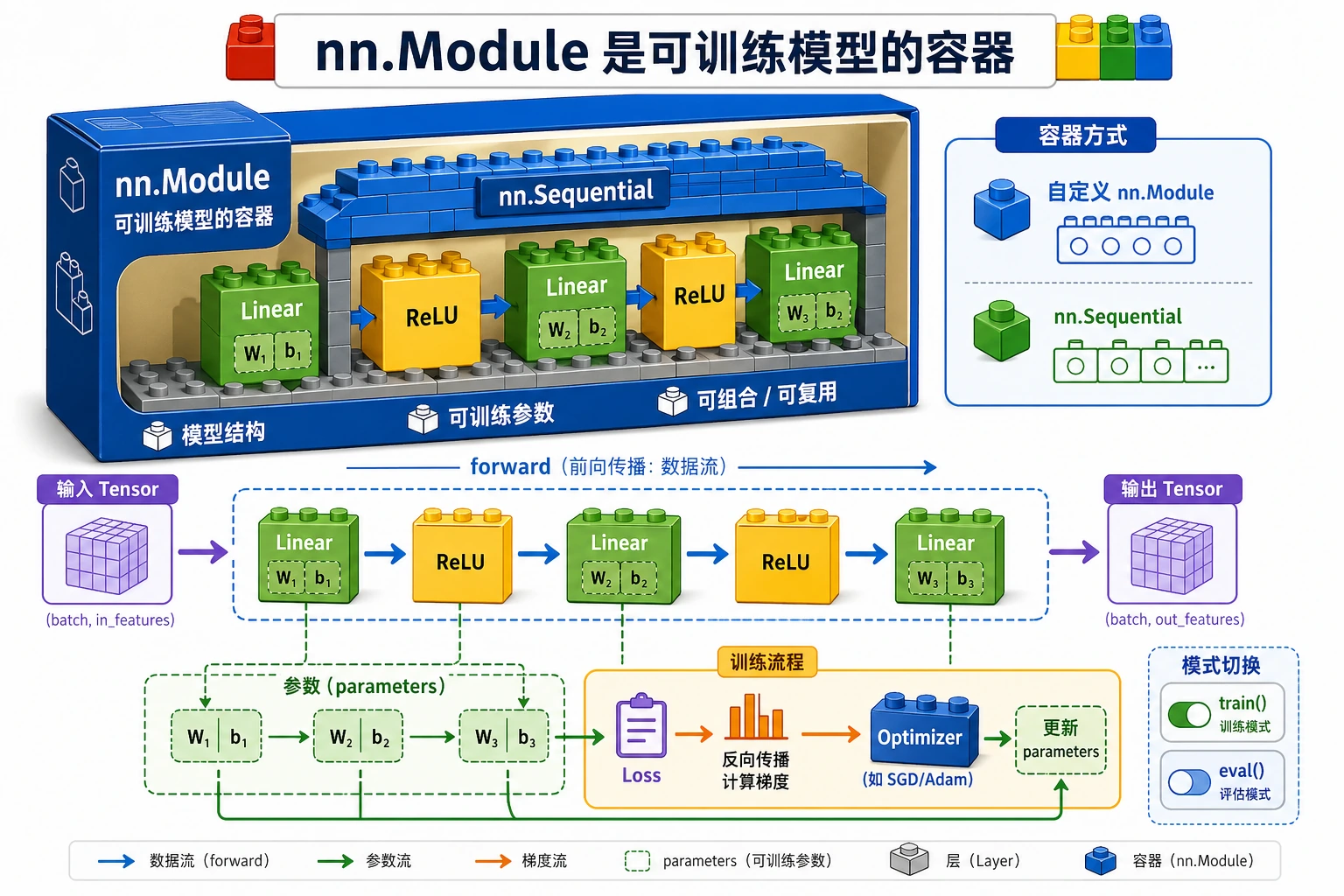
可以把 nn.Module 理解成模型容器:
层 + 参数 + 前向逻辑 + 模式状态 -> 一个模型对象
之后 optimizer 只需要拿到 model.parameters(),不用知道你写了多少层。
从手写权重到 nn.Linear
前面几节你见过这个运算:
logits = X @ W + b
nn.Linear(in_features, out_features) 会把同样的想法包装成一个可训练层。
import torch
from torch import nn
layer = nn.Linear(3, 2)
with torch.no_grad():
layer.weight.copy_(
torch.tensor(
[
[0.1, 0.2, 0.3],
[-0.1, 0.4, 0.2],
]
)
)
layer.bias.copy_(torch.tensor([0.01, -0.02]))
x = torch.tensor([[1.0, 2.0, 3.0]])
y = layer(x)
print("linear_lab")
print("input shape:", tuple(x.shape))
print("weight shape:", tuple(layer.weight.shape))
print("bias shape:", tuple(layer.bias.shape))
print("output:", torch.round(y * 100) / 100)
预期输出:
linear_lab
input shape: (1, 3)
weight shape: (2, 3)
bias shape: (2,)
output: tensor([[1.4100, 1.2800]], grad_fn=<DivBackward0>)
重要 shape 规则:
- 输入:
[batch, in_features] - 权重:
[out_features, in_features] - 输出:
[batch, out_features]
输出里的 grad_fn 表示它连在 autograd 计算图上。
用 nn.Sequential 快速搭网络
当数据只是按顺序经过一串层时,可以用 nn.Sequential。
import torch
from torch import nn
torch.manual_seed(11)
model = nn.Sequential(
nn.Linear(3, 4),
nn.ReLU(),
nn.Linear(4, 2),
)
batch = torch.randn(5, 3)
logits = model(batch)
print("logits shape:", tuple(logits.shape))
预期输出:
logits shape: (5, 2)
读模型结构:
[batch, 3] -> Linear(3, 4) -> ReLU -> Linear(4, 2) -> [batch, 2]
这已经是一个小型多层感知机。
写自定义 nn.Module
真实项目通常会写自定义模块,因为它能容纳具名子模块、分支逻辑、可复用辅助方法和更清楚的调试入口。
import torch
from torch import nn
class TinyClassifier(nn.Module):
def __init__(self, in_features=3, hidden=4, classes=2):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_features, hidden),
nn.ReLU(),
nn.Linear(hidden, classes),
)
def forward(self, x):
return self.net(x)
torch.manual_seed(11)
model = TinyClassifier()
batch = torch.randn(5, 3)
logits = model(batch)
print("module_lab")
print("logits shape:", tuple(logits.shape))
for name, param in model.named_parameters():
print(name, tuple(param.shape))
print("state keys:", list(model.state_dict().keys()))
预期输出:
module_lab
logits shape: (5, 2)
net.0.weight (4, 3)
net.0.bias (4,)
net.2.weight (2, 4)
net.2.bias (2,)
state keys: ['net.0.weight', 'net.0.bias', 'net.2.weight', 'net.2.bias']
职责分工:
| 方法或 API | 职责 |
|---|---|
__init__() | 创建层和子模块 |
forward() | 描述输入如何变成输出 |
parameters() | 把可学习参数交给 optimizer |
named_parameters() | 暴露参数名和 shape,方便调试 |
state_dict() | 暴露可保存和加载的张量 |
不要把训练逻辑写进 forward()。Loss、backward()、optimizer.step() 属于训练循环,不属于模型定义。
train() 和 eval() 是模式开关
model.train() 不会自动跑训练循环,model.eval() 也不会自动跑验证。它们切换的是 Dropout、BatchNorm 等层的行为。
运行这个例子:
import torch
from torch import nn
class DropoutProbe(nn.Module):
def __init__(self):
super().__init__()
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
return self.dropout(x)
probe = DropoutProbe()
sample = torch.ones(6)
torch.manual_seed(3)
probe.train()
train_a = probe(sample)
train_b = probe(sample)
probe.eval()
eval_a = probe(sample)
eval_b = probe(sample)
print("mode_lab")
print("train outputs equal:", torch.equal(train_a, train_b))
print("eval outputs equal:", torch.equal(eval_a, eval_b))
print("eval output:", eval_a)
预期输出:
mode_lab
train outputs equal: False
eval outputs equal: True
eval output: tensor([1., 1., 1., 1., 1., 1.])
实用习惯:
model.train() # 训练 batch 前
model.eval() # 验证或预测前
验证时和 torch.no_grad() 搭配:
model.eval()
with torch.no_grad():
logits = model(batch)
小项目:训练分数预测器
这个例子使用两个特征和一个回归目标:
- 每周学习小时;
- 每周完成的练习题数量;
- 预测分数。
目标值除以 100,这样这个小数据集训练会更稳定。
import torch
from torch import nn
class ScorePredictor(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1),
)
def forward(self, x):
return self.net(x)
torch.manual_seed(42)
X = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
]
)
y = torch.tensor(
[
[55.0],
[60.0],
[68.0],
[78.0],
[85.0],
[92.0],
]
) / 100.0
model = ScorePredictor()
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
print("training_lab")
for epoch in range(401):
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"epoch={epoch:3d} loss={loss.item():.4f}")
model.eval()
with torch.no_grad():
test = torch.tensor([[6.5, 7.0]])
pred_score = model(test).item() * 100
print("predicted score:", round(pred_score, 2))
预期输出:
training_lab
epoch= 0 loss=0.4672
epoch=100 loss=0.0003
epoch=200 loss=0.0001
epoch=300 loss=0.0001
epoch=400 loss=0.0001
predicted score: 89.31
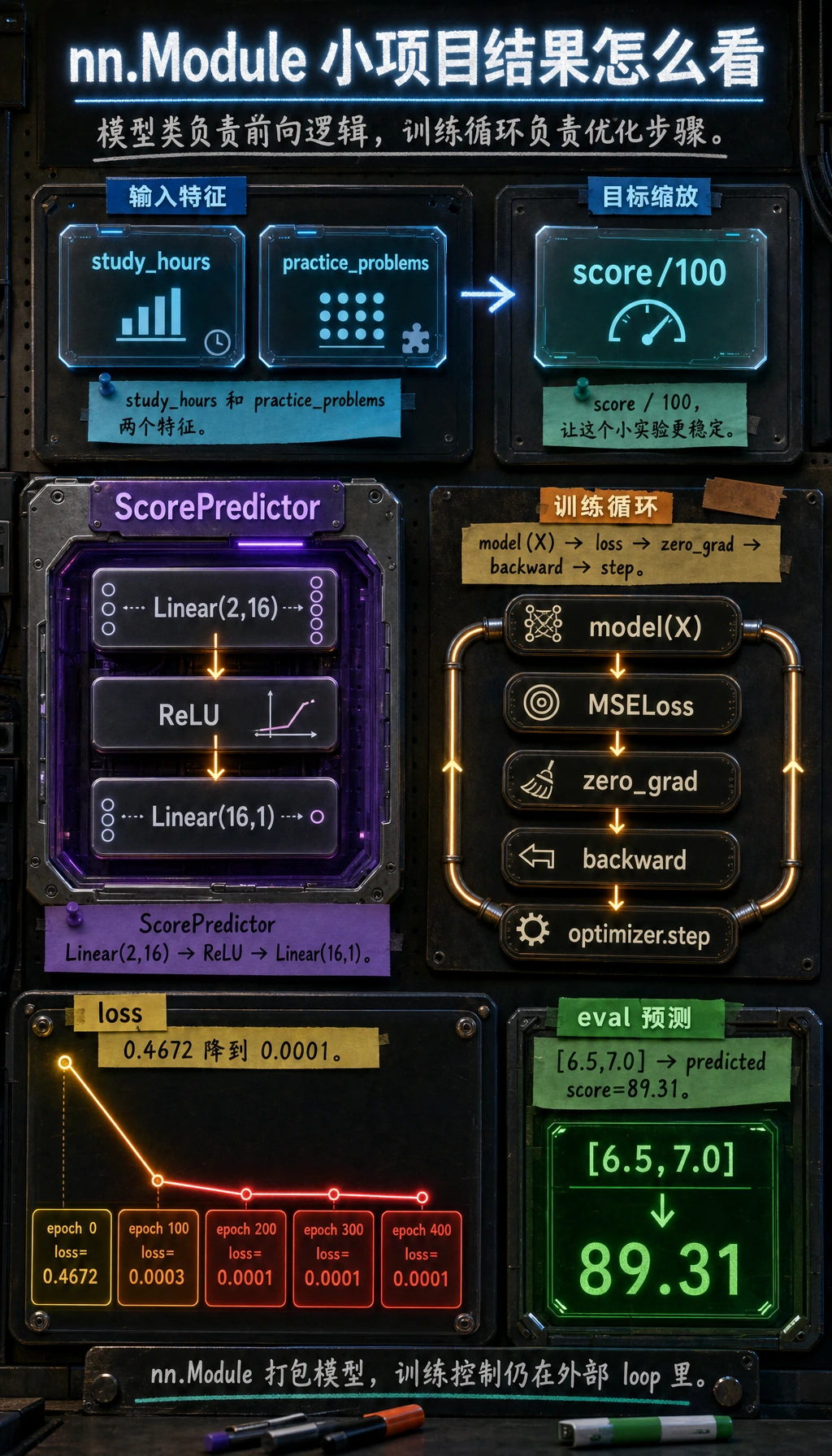
现在它已经是完整的微型 PyTorch 模型:
data -> model -> loss -> zero_grad -> backward -> optimizer.step -> eval prediction
什么时候用 Sequential,什么时候用自定义 Module?
| 场景 | 推荐选择 |
|---|---|
| 简单直线堆叠 | nn.Sequential |
| 多输入或多输出 | 自定义 nn.Module |
| 跳连或分支结构 | 自定义 nn.Module |
| 可复用组件 | 自定义 nn.Module |
| 需要更清楚的参数名 | 自定义 nn.Module |
真实深度学习项目里,自定义模块更常见,因为架构很快就会超过“直线堆叠”。
常见错误
| 错误 | 为什么有问题 | 修复 |
|---|---|---|
在 forward() 里临时创建层 | 每次调用都会创建新参数,可能无法被正确优化 | 在 __init__() 里定义层 |
把 loss 和 optimizer 逻辑写进 forward() | 混淆模型定义和训练控制 | 让 forward() 只负责输入到输出 |
忘记 super().__init__() | 子模块可能无法正确注册 | 在 __init__() 开头调用 |
| 不检查参数名 | 很难排查冻结层或缺失层 | 打印 named_parameters() |
验证前忘记 eval() | Dropout/BatchNorm 还像训练时一样工作 | 验证前调用 model.eval() |
练习
- 把
ScorePredictor的隐藏层大小从16改成4和32。loss 有什么变化? - 删除
ReLU()。这个小回归任务还能不能学?为什么更深的非线性任务可能需要它? - 打印
model.state_dict()的 key 和 shape。checkpoint 会保存哪些张量? - 在 ReLU 后加入
nn.Dropout(p=0.2),比较train()和eval()模式下的预测。
小结
nn.Module把层、参数、前向逻辑和模式状态统一管理。forward()应该描述数据流,不应该写训练循环。model.parameters()把模型和 optimizer 连接起来。state_dict()是标准 checkpoint 接口。train()和eval()切换层行为,它们本身不运行训练或验证循环。