6.2.5 nn.Module
nn.Module は、PyTorch が層、パラメータ、順伝播ロジック、学習/評価モードを 1 つのモデルオブジェクトにまとめる方法です。この節では、autograd で手書きしたパラメータを、再利用できるモデルクラスへ発展させます。
学習目標
nn.Linearを使い、そのパラメータ shape を読める。nn.Sequentialで単純なモデルを作れる。__init__()とforward()を持つカスタムnn.Moduleを書ける。named_parameters()とstate_dict()を確認できる。model.train()とmodel.eval()が実際に何を切り替えるのか理解する。
まずモデルコンテナを見る
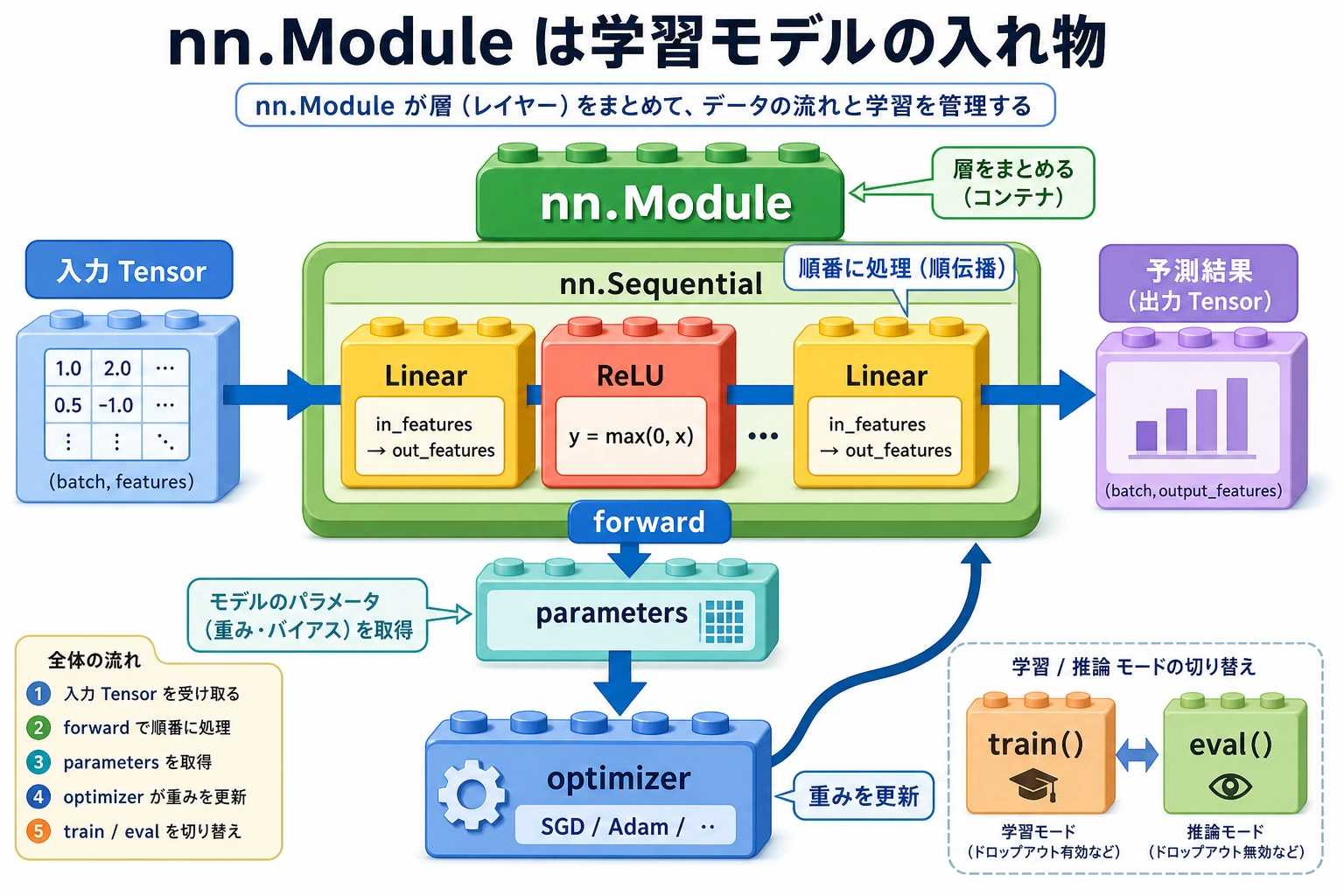
nn.Module はモデルコンテナだと考えます。
層 + パラメータ + 順伝播ロジック + モード状態 -> 1 つのモデルオブジェクト
すると optimizer は model.parameters() を受け取るだけでよく、モデルに何層あるかを知る必要はありません。
手書きの重みから nn.Linear へ
前の節では、次の演算を見ました。
logits = X @ W + b
nn.Linear(in_features, out_features) は、同じ考え方を学習可能な層としてまとめたものです。
import torch
from torch import nn
layer = nn.Linear(3, 2)
with torch.no_grad():
layer.weight.copy_(
torch.tensor(
[
[0.1, 0.2, 0.3],
[-0.1, 0.4, 0.2],
]
)
)
layer.bias.copy_(torch.tensor([0.01, -0.02]))
x = torch.tensor([[1.0, 2.0, 3.0]])
y = layer(x)
print("linear_lab")
print("input shape:", tuple(x.shape))
print("weight shape:", tuple(layer.weight.shape))
print("bias shape:", tuple(layer.bias.shape))
print("output:", torch.round(y * 100) / 100)
期待される出力:
linear_lab
input shape: (1, 3)
weight shape: (2, 3)
bias shape: (2,)
output: tensor([[1.4100, 1.2800]], grad_fn=<DivBackward0>)
重要な shape ルール:
- 入力:
[batch, in_features] - 重み:
[out_features, in_features] - 出力:
[batch, out_features]
出力にある grad_fn は、その値が autograd の計算グラフにつながっていることを意味します。
nn.Sequential で単純なネットワークを作る
データが層を一直線に通るだけなら、nn.Sequential を使えます。
import torch
from torch import nn
torch.manual_seed(11)
model = nn.Sequential(
nn.Linear(3, 4),
nn.ReLU(),
nn.Linear(4, 2),
)
batch = torch.randn(5, 3)
logits = model(batch)
print("logits shape:", tuple(logits.shape))
期待される出力:
logits shape: (5, 2)
モデルは次のように読めます。
[batch, 3] -> Linear(3, 4) -> ReLU -> Linear(4, 2) -> [batch, 2]
これはすでに小さな多層パーセプトロンです。
カスタム nn.Module を書く
実プロジェクトではカスタムモジュールが普通です。名前付きのサブモジュール、分岐、再利用できる補助メソッド、分かりやすいデバッグ入口を持てるからです。
import torch
from torch import nn
class TinyClassifier(nn.Module):
def __init__(self, in_features=3, hidden=4, classes=2):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_features, hidden),
nn.ReLU(),
nn.Linear(hidden, classes),
)
def forward(self, x):
return self.net(x)
torch.manual_seed(11)
model = TinyClassifier()
batch = torch.randn(5, 3)
logits = model(batch)
print("module_lab")
print("logits shape:", tuple(logits.shape))
for name, param in model.named_parameters():
print(name, tuple(param.shape))
print("state keys:", list(model.state_dict().keys()))
期待される出力:
module_lab
logits shape: (5, 2)
net.0.weight (4, 3)
net.0.bias (4,)
net.2.weight (2, 4)
net.2.bias (2,)
state keys: ['net.0.weight', 'net.0.bias', 'net.2.weight', 'net.2.bias']
役割分担:
| メソッド / API | 役割 |
|---|---|
__init__() | 層とサブモジュールを作る |
forward() | 入力がどのように出力になるかを書く |
parameters() | 学習可能パラメータを optimizer に渡す |
named_parameters() | パラメータ名と shape を見せ、デバッグしやすくする |
state_dict() | 保存・読み込みできるテンソルを見せる |
学習ロジックを forward() に入れないでください。Loss、backward()、optimizer.step() は training loop の仕事であり、モデル定義の仕事ではありません。
train() と eval() はモード切り替え
model.train() は学習ループを実行しません。model.eval() も検証を実行しません。これらは Dropout や BatchNorm などの層の動作を切り替えます。
次の例を実行します。
import torch
from torch import nn
class DropoutProbe(nn.Module):
def __init__(self):
super().__init__()
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
return self.dropout(x)
probe = DropoutProbe()
sample = torch.ones(6)
torch.manual_seed(3)
probe.train()
train_a = probe(sample)
train_b = probe(sample)
probe.eval()
eval_a = probe(sample)
eval_b = probe(sample)
print("mode_lab")
print("train outputs equal:", torch.equal(train_a, train_b))
print("eval outputs equal:", torch.equal(eval_a, eval_b))
print("eval output:", eval_a)
期待される出力:
mode_lab
train outputs equal: False
eval outputs equal: True
eval output: tensor([1., 1., 1., 1., 1., 1.])
実用的な習慣:
model.train() # 学習 batch の前
model.eval() # 検証または予測の前
検証では torch.no_grad() と組み合わせます。
model.eval()
with torch.no_grad():
logits = model(batch)
ミニプロジェクト: スコア予測器を学習する
この例では 2 つの特徴量と 1 つの回帰ターゲットを使います。
- 1 週間の学習時間
- 1 週間に解いた練習問題数
- 予測スコア
この小さなデータセットで学習を安定させるため、ターゲットは 100 で割っています。
import torch
from torch import nn
class ScorePredictor(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1),
)
def forward(self, x):
return self.net(x)
torch.manual_seed(42)
X = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
]
)
y = torch.tensor(
[
[55.0],
[60.0],
[68.0],
[78.0],
[85.0],
[92.0],
]
) / 100.0
model = ScorePredictor()
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
print("training_lab")
for epoch in range(401):
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"epoch={epoch:3d} loss={loss.item():.4f}")
model.eval()
with torch.no_grad():
test = torch.tensor([[6.5, 7.0]])
pred_score = model(test).item() * 100
print("predicted score:", round(pred_score, 2))
期待される出力:
training_lab
epoch= 0 loss=0.4672
epoch=100 loss=0.0003
epoch=200 loss=0.0001
epoch=300 loss=0.0001
epoch=400 loss=0.0001
predicted score: 89.31
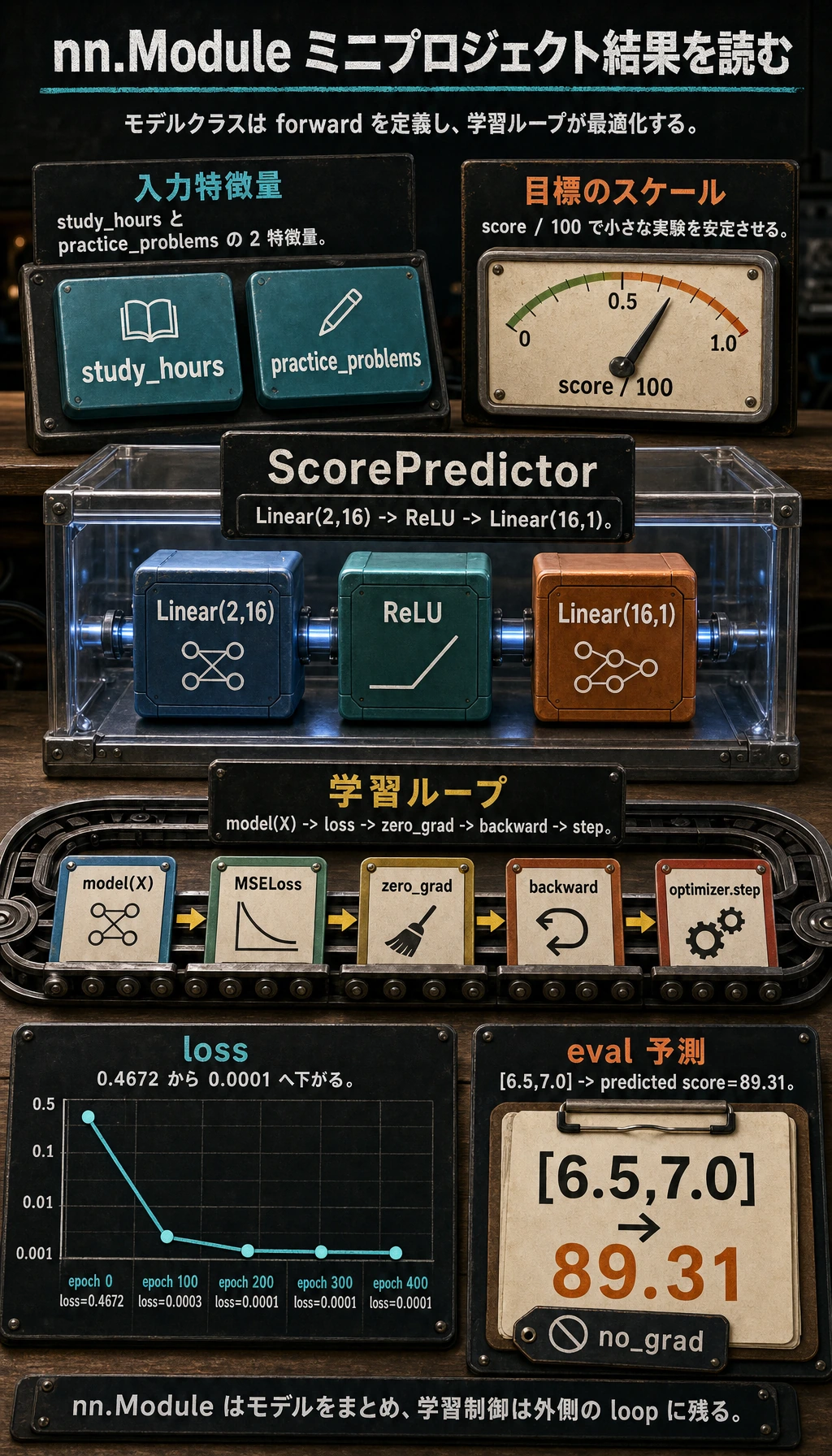
これで、完全なミニ PyTorch モデルになりました。
data -> model -> loss -> zero_grad -> backward -> optimizer.step -> eval prediction
Sequential とカスタム Module の使い分け
| 状況 | よい選択 |
|---|---|
| 単純な一直線の積み重ね | nn.Sequential |
| 複数入力または複数出力 | カスタム nn.Module |
| スキップ接続や分岐 | カスタム nn.Module |
| 再利用可能な部品 | カスタム nn.Module |
| より分かりやすいパラメータ名が必要 | カスタム nn.Module |
実際の深層学習プロジェクトでは、構造がすぐに一直線を超えるため、カスタムモジュールがより一般的です。
よくあるミス
| ミス | なぜ困るか | 直し方 |
|---|---|---|
forward() 内で層を作る | 呼び出しごとに新しいパラメータが作られ、正しく最適化されないことがある | 層は __init__() に定義する |
loss や optimizer の処理を forward() に入れる | モデル定義と学習制御が混ざる | forward() は入力から出力までに限定する |
super().__init__() を忘れる | サブモジュールが正しく登録されない可能性がある | __init__() の最初で呼ぶ |
| パラメータ名を確認しない | 凍結層や欠落層の調査が難しい | named_parameters() を表示する |
検証前に eval() を忘れる | Dropout/BatchNorm が学習時の動作を続ける | 検証前に model.eval() を呼ぶ |
練習
ScorePredictorの隠れ層サイズを16から4と32に変えてください。loss はどう変わりますか?ReLU()を削除してください。この小さな回帰タスクはまだ学習できますか?より深い非線形タスクではなぜ必要になるのでしょうか?model.state_dict()の key と shape を表示してください。checkpoint にはどのテンソルが保存されますか?- ReLU の後に
nn.Dropout(p=0.2)を追加し、train()とeval()モードで予測を比べてください。
まとめ
nn.Moduleは層、パラメータ、順伝播ロジック、モード状態をまとめて管理します。forward()はデータの流れを書く場所であり、学習ループを書く場所ではありません。model.parameters()がモデルと optimizer をつなぎます。state_dict()は標準的な checkpoint インターフェースです。train()とeval()は層の動作を切り替えます。それ自体が学習や検証を実行するわけではありません。