6.2.6 データ読み込み
この節の位置づけ
モデルは準備できましたが、巨大なデータの塊を一度に渡すべきではありません。Dataset は 1 つのサンプルを定義し、DataLoader はサンプルをシャッフルされた小さな batch にして学習ループへ渡します。
学習目標
- 小さなカスタム
Datasetを書ける。 DataLoaderで batch を作れる。- 学習前に batch shape を読める。
- train / validation を再現可能に分割できる。
- loader を小さな学習ループにつなげられる。
まず batch の流れを見る
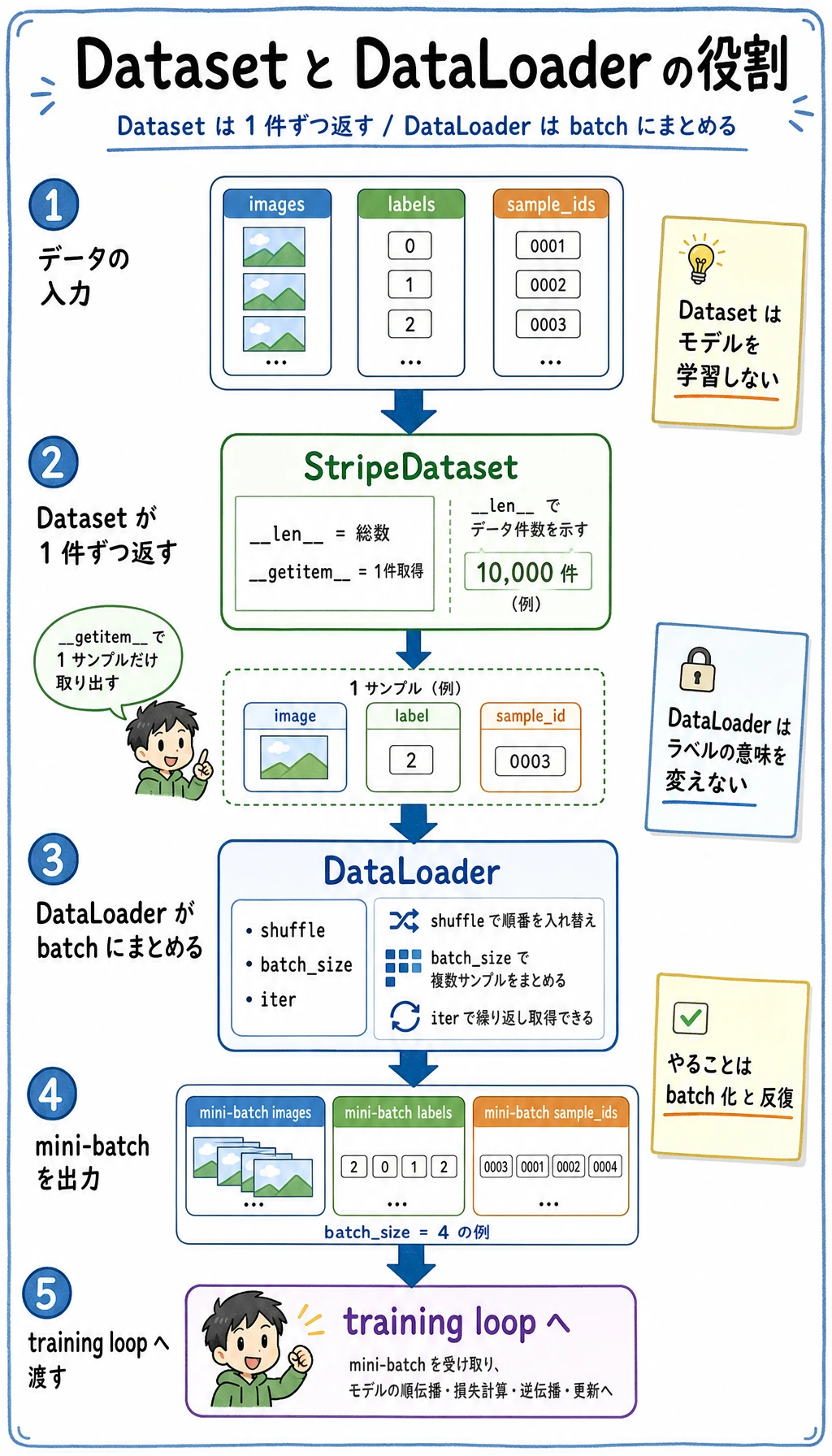
次の順番で読みます。
生サンプル -> Dataset が 1 サンプルを返す -> DataLoader が batch を作る -> 学習ループが batch を消費する
この分離は便利です。
| オブジェクト | 仕事 |
|---|---|
Dataset | 長さと、1 サンプルの取り出し方を定義する |
DataLoader | batch 化、shuffle、反復、必要なら並列読み込みを行う |
| 学習ループ | batch_x、batch_y を読み、モデルを更新する |
なぜ batch が必要なのか
batch は、モデルが 1 回のパラメータ更新で見る小さなサンプルのまとまりです。
通常は次のようには書きません。
pred = model(all_data_once)
代わりに次のように書きます。
for batch_x, batch_y in train_loader:
pred = model(batch_x)
理由:
- メモリを管理しやすい。
- パラメータ更新を何度も行える。
- shuffle により、よりバランスのよいサンプル列になる。
- 同じループで小さな CSV から大きな画像フォルダまで扱える。
実験 1: 最小限使える Dataset を書く
import torch
from torch.utils.data import Dataset
class StudentDataset(Dataset):
def __init__(self):
self.features = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
[8.0, 9.0],
[9.0, 10.0],
]
)
self.labels = torch.tensor(
[[55.0], [60.0], [68.0], [78.0], [85.0], [92.0], [96.0], [99.0]]
) / 100.0
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
dataset = StudentDataset()
x0, y0 = dataset[0]
print("dataset_lab")
print("dataset size:", len(dataset))
print("sample 0 shapes:", tuple(x0.shape), tuple(y0.shape))
print("sample 0:", x0, y0)
期待される出力:
dataset_lab
dataset size: 8
sample 0 shapes: (2,) (1,)
sample 0: tensor([2., 1.]) tensor([0.5500])
カスタム dataset の最小契約は次の 2 つです。
__len__(): サンプル数を返す。__getitem__(idx): 1 サンプルを返す。
loader を作る前に確認します。
len(dataset)
dataset[0]
x と y の shape、dtype
実験 2: サンプルを batch にする
import torch
from torch.utils.data import Dataset, DataLoader
class StudentDataset(Dataset):
def __init__(self):
self.features = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
[8.0, 9.0],
[9.0, 10.0],
]
)
self.labels = torch.tensor(
[[55.0], [60.0], [68.0], [78.0], [85.0], [92.0], [96.0], [99.0]]
) / 100.0
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
dataset = StudentDataset()
loader = DataLoader(dataset, batch_size=3, shuffle=False)
print("loader_lab")
for batch_idx, (batch_x, batch_y) in enumerate(loader):
print(
f"batch={batch_idx} "
f"x_shape={tuple(batch_x.shape)} "
f"y_shape={tuple(batch_y.shape)}"
)
期待される出力:
loader_lab
batch=0 x_shape=(3, 2) y_shape=(3, 1)
batch=1 x_shape=(3, 2) y_shape=(3, 1)
batch=2 x_shape=(2, 2) y_shape=(2, 1)
最後の batch が 2 サンプルだけなのは、8 が 3 で割り切れないためです。これは正常です。
shape の意味:
batch_x:[batch, features]batch_y:[batch, target_dim]
実験 3: train / validation 分割
seed 付き generator を使うと、分割を再現できます。
import torch
from torch.utils.data import DataLoader, random_split
dataset = StudentDataset()
train_dataset, val_dataset = random_split(
dataset,
[6, 2],
generator=torch.Generator().manual_seed(42),
)
train_loader = DataLoader(
train_dataset,
batch_size=3,
shuffle=True,
generator=torch.Generator().manual_seed(7),
)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False)
train_x, train_y = next(iter(train_loader))
val_x, val_y = next(iter(val_loader))
print("split_lab")
print("train size:", len(train_dataset), "val size:", len(val_dataset))
print("first train batch:", tuple(train_x.shape), tuple(train_y.shape))
print("first val batch:", tuple(val_x.shape), tuple(val_y.shape))
期待される出力:
split_lab
train size: 6 val size: 2
first train batch: (3, 2) (3, 1)
first val batch: (2, 2) (2, 1)
学習データでは通常 shuffle=True を使います。検証やテストの loader は、評価にランダム順が不要なので、通常 shuffle=False にします。
実験 4: 学習で Loader を使う
これはまだ非常に小さなデータセットなので、validation loss は上下しやすいです。ここでの目的は本番品質の評価ではなく、loader が学習ループへどう入るかを見ることです。
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset, random_split
class StudentDataset(Dataset):
def __init__(self):
self.features = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
[8.0, 9.0],
[9.0, 10.0],
]
)
self.labels = torch.tensor(
[[55.0], [60.0], [68.0], [78.0], [85.0], [92.0], [96.0], [99.0]]
) / 100.0
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
class ScorePredictor(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1),
)
def forward(self, x):
return self.net(x)
dataset = StudentDataset()
train_dataset, val_dataset = random_split(
dataset,
[6, 2],
generator=torch.Generator().manual_seed(42),
)
train_loader = DataLoader(
train_dataset,
batch_size=3,
shuffle=True,
generator=torch.Generator().manual_seed(7),
)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False)
torch.manual_seed(42)
model = ScorePredictor()
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
print("training_with_loader")
for epoch in range(1, 4):
model.train()
total_train_loss = 0.0
for batch_x, batch_y in train_loader:
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item() * len(batch_x)
avg_train_loss = total_train_loss / len(train_loader.dataset)
model.eval()
total_val_loss = 0.0
with torch.no_grad():
for batch_x, batch_y in val_loader:
total_val_loss += loss_fn(model(batch_x), batch_y).item() * len(batch_x)
avg_val_loss = total_val_loss / len(val_loader.dataset)
print(
f"epoch={epoch} "
f"train_loss={avg_train_loss:.4f} "
f"val_loss={avg_val_loss:.4f}"
)
期待される出力:
training_with_loader
epoch=1 train_loss=0.4641 val_loss=0.6458
epoch=2 train_loss=0.3653 val_loss=0.0059
epoch=3 train_loss=0.1147 val_loss=0.3121

これで全体の形が見えます。
Dataset -> DataLoader -> batch loop -> model -> loss -> backward -> step -> validation loop
batch_size の選び方
| batch size | 強み | トレードオフ |
|---|---|---|
| 小さい | 更新が頻繁で、メモリ使用量が少ない | loss が揺れやすい |
| 大きい | 推定がなめらかで、ハードウェアを使いやすい | メモリを多く使い、更新回数が減ることがある |
学習用の例では、8、16、32 がよくある出発点です。実プロジェクトでは、最適値はメモリ、スループット、学習安定性によって決まります。
よくあるミス
| ミス | なぜ困るか | 直し方 |
|---|---|---|
Dataset は必ず全データをメモリへ読むと思い込む | 大きなプロジェクトでは __getitem__ で必要なファイルだけ読むことが多い | __getitem__ は 1 サンプルを返すことに集中する |
| 学習前に 1 batch を表示しない | shape バグがモデル内で初めて見つかる | next(iter(loader)) を確認する |
training set で shuffle=False | 順序付きデータが更新を偏らせることがある | training loader は shuffle=True にする |
安定して検証サンプルを確認したいのに shuffle=True | 実行ごとにサンプル順が変わる | validation/test は決定的にする |
| target scaling を忘れる | 小さな demo の回帰 loss が大きくなりすぎることがある | 必要なら target をスケールし、理由を書く |
クイックデバッグチェックリスト
loader を作ったら、まずこれを実行します。
batch_x, batch_y = next(iter(train_loader))
print(batch_x.shape, batch_x.dtype)
print(batch_y.shape, batch_y.dtype)
確認すること:
Datasetの 1 サンプルは正しいか?DataLoaderの 1 batch は正しいか?batch_xはモデルの最初の層につながるか?batch_yは loss 関数につながるか?
練習
StudentDatasetを 12 サンプルに増やし、9 個を training、3 個を validation に分けてください。batch_sizeを1、2、4に変えてください。各 epoch の batch 数はいくつになりますか?shuffle=Trueにして、2 epoch 連続で最初の training batch を表示し、順序が変わるか確認してください。- 各サンプルに 3 つ目の特徴量を追加してください。モデルのどの層を変える必要がありますか?
まとめ
Datasetは 1 サンプルの形を定義します。DataLoaderはサンプルを batch に変えます。- 学習前に、必ず 1 サンプルと 1 batch を確認します。
- training loader は通常 shuffle し、validation/test loader は通常 shuffle しません。
- 次の training-loop 節では、この loader を model、loss、optimizer、evaluation につなげます。