6.2.6 数据加载
本节定位
模型已经准备好了,但它不应该一次吃下一整堆数据。Dataset 定义一个样本长什么样,DataLoader 把样本变成可打乱的小 batch,送进训练循环。
学习目标
- 写一个小型自定义
Dataset。 - 用
DataLoader创建 batch。 - 训练前读懂 batch shape。
- 可复现地切分训练集和验证集。
- 把 loader 接到一个小训练循环里。
先看 batch 流程
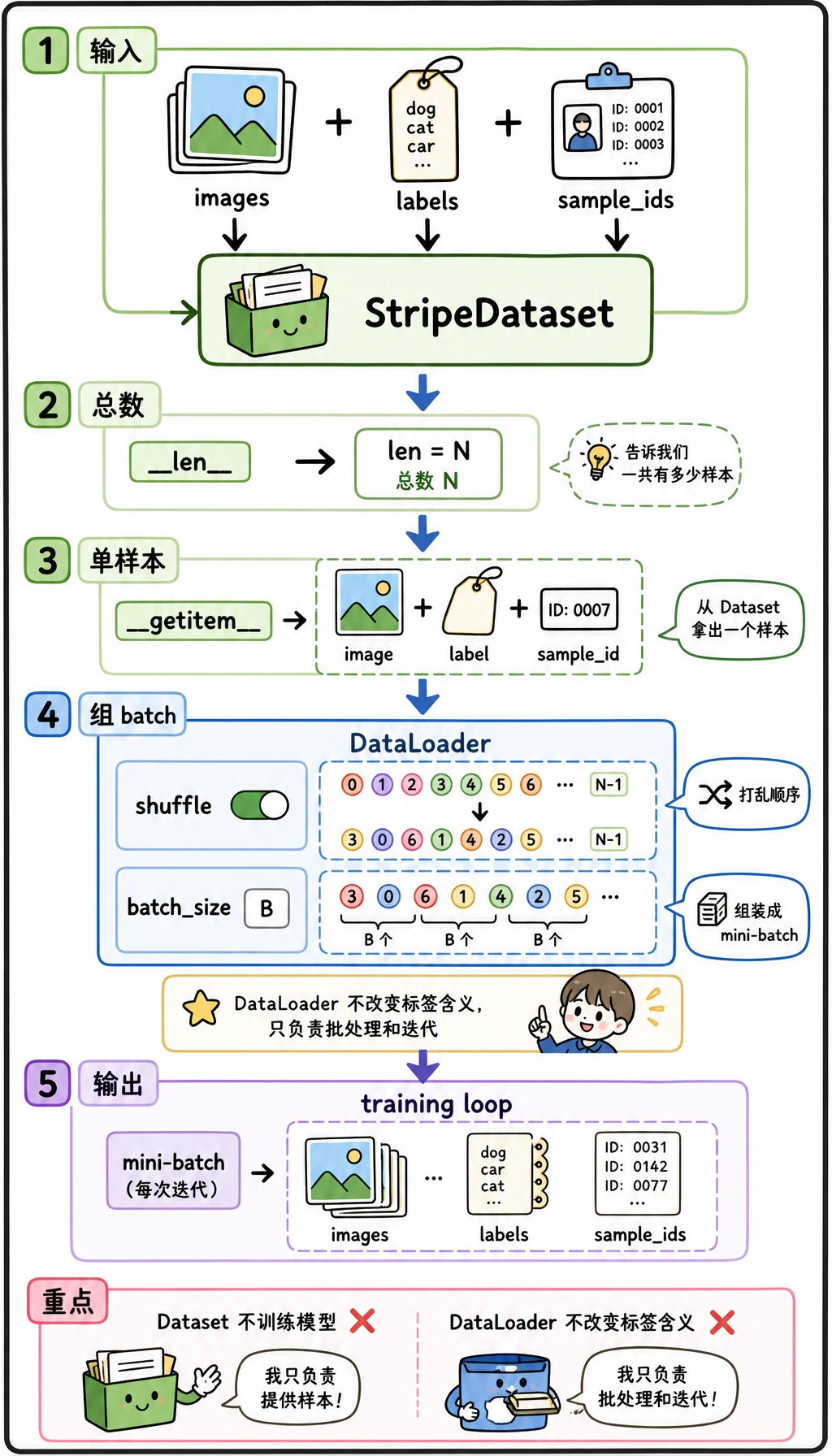
按这个顺序读:
原始样本 -> Dataset 返回一个样本 -> DataLoader 组成 batch -> 训练循环消费 batch
这层拆分很有用:
| 对象 | 工作 |
|---|---|
Dataset | 定义长度,以及如何取一个样本 |
DataLoader | 组成 batch、打乱、迭代,也可以并行加载 |
| 训练循环 | 读取 batch_x、batch_y 并更新模型 |
为什么需要 batch?
batch 是模型一次参数更新时看到的一小组样本。
我们通常避免这样写:
pred = model(all_data_once)
而是这样写:
for batch_x, batch_y in train_loader:
pred = model(batch_x)
原因:
- 内存更可控;
- 参数可以反复更新;
- shuffle 后样本流更均衡;
- 同一套循环既能处理小 CSV,也能处理大图片文件夹。
实验 1:写最小可用 Dataset
import torch
from torch.utils.data import Dataset
class StudentDataset(Dataset):
def __init__(self):
self.features = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
[8.0, 9.0],
[9.0, 10.0],
]
)
self.labels = torch.tensor(
[[55.0], [60.0], [68.0], [78.0], [85.0], [92.0], [96.0], [99.0]]
) / 100.0
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
dataset = StudentDataset()
x0, y0 = dataset[0]
print("dataset_lab")
print("dataset size:", len(dataset))
print("sample 0 shapes:", tuple(x0.shape), tuple(y0.shape))
print("sample 0:", x0, y0)
预期输出:
dataset_lab
dataset size: 8
sample 0 shapes: (2,) (1,)
sample 0: tensor([2., 1.]) tensor([0.5500])
自定义 dataset 的最小约定是:
__len__():一共有多少样本;__getitem__(idx):一个样本长什么样。
创建 loader 前先检查:
len(dataset)
dataset[0]
x 和 y 的 shape、dtype
实验 2:把样本变成 batch
import torch
from torch.utils.data import Dataset, DataLoader
class StudentDataset(Dataset):
def __init__(self):
self.features = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
[8.0, 9.0],
[9.0, 10.0],
]
)
self.labels = torch.tensor(
[[55.0], [60.0], [68.0], [78.0], [85.0], [92.0], [96.0], [99.0]]
) / 100.0
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
dataset = StudentDataset()
loader = DataLoader(dataset, batch_size=3, shuffle=False)
print("loader_lab")
for batch_idx, (batch_x, batch_y) in enumerate(loader):
print(
f"batch={batch_idx} "
f"x_shape={tuple(batch_x.shape)} "
f"y_shape={tuple(batch_y.shape)}"
)
预期输出:
loader_lab
batch=0 x_shape=(3, 2) y_shape=(3, 1)
batch=1 x_shape=(3, 2) y_shape=(3, 1)
batch=2 x_shape=(2, 2) y_shape=(2, 1)
最后一个 batch 只有 2 个样本,因为 8 不能被 3 整除,这是正常的。
shape 含义:
batch_x:[batch, features]batch_y:[batch, target_dim]
实验 3:训练/验证切分
使用带 seed 的 generator,让切分结果可复现。
import torch
from torch.utils.data import DataLoader, random_split
dataset = StudentDataset()
train_dataset, val_dataset = random_split(
dataset,
[6, 2],
generator=torch.Generator().manual_seed(42),
)
train_loader = DataLoader(
train_dataset,
batch_size=3,
shuffle=True,
generator=torch.Generator().manual_seed(7),
)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False)
train_x, train_y = next(iter(train_loader))
val_x, val_y = next(iter(val_loader))
print("split_lab")
print("train size:", len(train_dataset), "val size:", len(val_dataset))
print("first train batch:", tuple(train_x.shape), tuple(train_y.shape))
print("first val batch:", tuple(val_x.shape), tuple(val_y.shape))
预期输出:
split_lab
train size: 6 val size: 2
first train batch: (3, 2) (3, 1)
first val batch: (2, 2) (2, 1)
训练数据通常用 shuffle=True。验证和测试 loader 通常用 shuffle=False,因为评估不需要随机顺序。
实验 4:在训练里使用 Loader
这仍然是一个很小的数据集,所以验证 loss 可能会抖动。这里的目标不是生产级评估,而是看清 loader 如何接入训练循环。
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset, random_split
class StudentDataset(Dataset):
def __init__(self):
self.features = torch.tensor(
[
[2.0, 1.0],
[3.0, 2.0],
[4.0, 3.0],
[5.0, 5.0],
[6.0, 6.0],
[7.0, 8.0],
[8.0, 9.0],
[9.0, 10.0],
]
)
self.labels = torch.tensor(
[[55.0], [60.0], [68.0], [78.0], [85.0], [92.0], [96.0], [99.0]]
) / 100.0
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
class ScorePredictor(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1),
)
def forward(self, x):
return self.net(x)
dataset = StudentDataset()
train_dataset, val_dataset = random_split(
dataset,
[6, 2],
generator=torch.Generator().manual_seed(42),
)
train_loader = DataLoader(
train_dataset,
batch_size=3,
shuffle=True,
generator=torch.Generator().manual_seed(7),
)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False)
torch.manual_seed(42)
model = ScorePredictor()
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
print("training_with_loader")
for epoch in range(1, 4):
model.train()
total_train_loss = 0.0
for batch_x, batch_y in train_loader:
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item() * len(batch_x)
avg_train_loss = total_train_loss / len(train_loader.dataset)
model.eval()
total_val_loss = 0.0
with torch.no_grad():
for batch_x, batch_y in val_loader:
total_val_loss += loss_fn(model(batch_x), batch_y).item() * len(batch_x)
avg_val_loss = total_val_loss / len(val_loader.dataset)
print(
f"epoch={epoch} "
f"train_loss={avg_train_loss:.4f} "
f"val_loss={avg_val_loss:.4f}"
)
预期输出:
training_with_loader
epoch=1 train_loss=0.4641 val_loss=0.6458
epoch=2 train_loss=0.3653 val_loss=0.0059
epoch=3 train_loss=0.1147 val_loss=0.3121

完整模式现在可见:
Dataset -> DataLoader -> batch loop -> model -> loss -> backward -> step -> validation loop
选择 batch_size
| batch size | 优点 | 取舍 |
|---|---|---|
| 小 | 更新更频繁、内存更省 | loss 更抖 |
| 大 | 估计更平滑、硬件利用更好 | 更占内存,更新次数可能更少 |
学习示例里,8、16、32 都是常见起点。真实项目里,最佳值取决于内存、吞吐和训练稳定性。
常见错误
| 错误 | 为什么有问题 | 修复 |
|---|---|---|
以为 Dataset 必须把所有数据读进内存 | 大项目通常在 __getitem__ 里按需读文件 | 让 __getitem__ 专注返回一个样本 |
| 训练前不打印一个 batch | shape bug 会拖到模型里才暴露 | 检查 next(iter(loader)) |
训练集 shuffle=False | 有序数据可能让更新偏向某些样本 | 训练 loader 使用 shuffle=True |
需要稳定查看验证样本时还用 shuffle=True | 每次样本顺序都变 | 验证/测试保持确定性 |
| 忘记缩放目标值 | 小 demo 的回归 loss 可能很大 | 必要时缩放目标并说明原因 |
快速排错清单
构建 loader 后先跑:
batch_x, batch_y = next(iter(train_loader))
print(batch_x.shape, batch_x.dtype)
print(batch_y.shape, batch_y.dtype)
问自己:
Dataset的一个样本对吗?DataLoader的一个 batch 对吗?batch_x能不能接上模型第一层?batch_y能不能接上 loss 函数?
练习
- 把
StudentDataset扩展到 12 个样本,再切成 9 个训练样本和 3 个验证样本。 - 把
batch_size改成1、2、4。每个 epoch 有多少个 batch? - 设置
shuffle=True,连续两个 epoch 打印第一个训练 batch,看顺序是否变化。 - 给每个样本加第三个特征。模型哪一层必须修改?
小结
Dataset定义一个样本长什么样。DataLoader定义样本如何变成 batch。- 训练前总是先检查一个样本和一个 batch。
- 训练 loader 通常 shuffle;验证/测试 loader 通常不 shuffle。
- 下一节训练循环,就是把这个 loader 接到 model、loss、optimizer 和 evaluation 上。