8 LLM アプリ開発と RAG
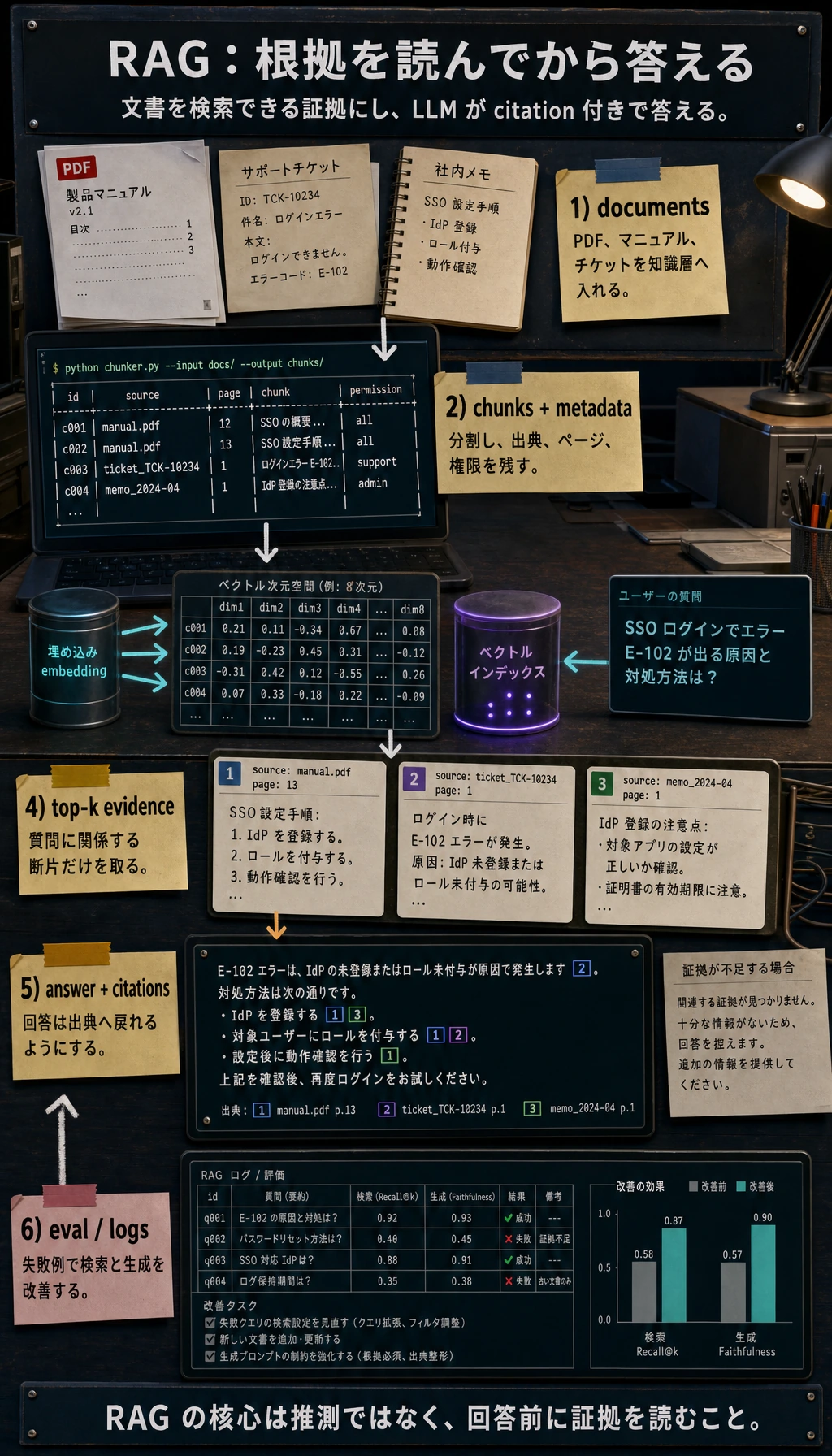
第 7 章では LLM がどう文章を生成するかを学びました。第 8 章では、それを実用アプリにします。文書を接続し、証拠を検索し、引用付きで答え、失敗を記録し、評価セットで改善する流れです。
RAG は「答える前に読む」と考えると分かりやすいです。答えが講義ノート、社内文書、製品マニュアル、私有ナレッジベースに基づくべきなら、モデルの記憶だけで推測させてはいけません。
まず RAG アプリのループを見る

このループを章全体の地図として使います。
| 層 | 役割 | 表示・保存するもの |
|---|---|---|
| 知識層 | 文書解析、テキスト清掃、チャンク分割、metadata 保持 | chunks.jsonl、出典、章、ページ、版 |
| 検索層 | 質問に最も関係するチャンクを探す | query、top-k チャンク、スコア、source ID |
| 生成層 | LLM に検索文脈だけで答えさせる | 最終 Prompt、回答、引用、答えられない理由 |
| アプリ層 | CLI、API、チャット UI、社内ツールに包む | request、response、エラー処理、ユーザー反応 |
| 運用層 | 品質、コスト、遅延、失敗を継続比較する | 評価セット、ログ、token コスト、遅延、失敗例 |
学習順序とタスク表
フルワークショップは基礎のあとに行います。まず検索チェーンを見えるようにし、それから簡単な部品を強い部品へ置き換えます。
| 手順 | 読む内容 | 手を動かすこと | 残す証拠 |
|---|---|---|---|
| 8.1 | RAG 基礎、文書処理、検索、評価 | 小さな「文書から回答」ループを作る | chunks、top-k 出力、引用付き回答 |
| 8.2 | 配置と統一 API | クラウド API、ローカルモデル、統一呼び出し層を理解する | 呼び出しメモまたは設定比較 |
| 8.3 | LLM アプリ開発 | RAG ループに API、ツール、対話、文書解析を足す | request/response 例とエラー経路 |
| 8.4 | 工程実践 | async、ログ、監視、API 設計、Docker メモを足す | ログ、設定、配置チェックリスト |
| 8.5 | ステージプロジェクト | 8.5.6 実践:第 8 章 RAG アプリ完全ワークショップ を動かす | ワークショップ出力、追加文書1つ、追加評価ケース1つ |
最初に動かすループ:フレームワークなしの Tiny RAG
LangChain、LlamaIndex、ベクトルデータベースの前に、最小チェーンを動かします。目的は強い検索器を作ることではなく、すべての手順を見ることです。
ch08_tiny_rag.py を作成し、Python 3.10 以降で実行してください。
import re
docs = [
{
"id": "ragops",
"source": "study-guide.md#ragops",
"text": "A RAG app needs an evaluation set with fixed questions, expected sources, ideal answers, and failure labels.",
},
{
"id": "chunking",
"source": "rag-basics.md#chunking",
"text": "A RAG app splits documents into chunks and keeps source metadata so answers can cite evidence.",
},
{
"id": "agentops",
"source": "agent-guide.md#trace",
"text": "Agent systems record tool calls, observations, permissions, and recovery steps.",
},
]
question = "Why does a RAG app need an evaluation set?"
STOPWORDS = {"a", "an", "the", "why", "does", "with", "and", "so", "can", "be"}
def tokenize(text: str) -> set[str]:
return set(re.findall(r"[\w\u4e00-\u9fff\u3040-\u30ff]+", text.lower())) - STOPWORDS
query_tokens = tokenize(question)
ranked = sorted(
(
(len(query_tokens & tokenize(doc["text"])), doc)
for doc in docs
),
key=lambda item: item[0],
reverse=True,
)
print("question:", question)
print("top chunks:")
for score, doc in ranked[:2]:
print(f"- {doc['id']} score={score} source={doc['source']}")
best = ranked[0][1]
answer = (
"Use a fixed evaluation set so every RAG change can be compared "
f"against the same questions and expected sources. [{best['source']}]"
)
print("answer:", answer)
期待される出力:
question: Why does a RAG app need an evaluation set?
top chunks:
- ragops score=4 source=study-guide.md#ragops
- chunking score=2 source=rag-basics.md#chunking
answer: Use a fixed evaluation set so every RAG change can be compared against the same questions and expected sources. [study-guide.md#ragops]
操作メモ: 文書を1つ追加し、新しい質問を1つ投げ、最終回答を見る前に top-k チャンクを表示してください。証拠が間違っていれば、回答は信用できません。
悪い RAG 回答をデバッグする

回答が悪いときは、モデルを変える前に失敗している層を見つけます。
| 症状 | まず表示するもの | 修正候補 |
|---|---|---|
| 回答に出典がない | 最終 Prompt と検索チャンク | chunk に source ID を残し、引用を必須にする |
| 原文に答えがあるのに検索できない | 原文検索とチャンク本文 | chunk サイズ調整、キーワード追加、ハイブリッド検索 |
| たくさん検索されたが最良チャンクが上にない | top-k スコアと人手の関連ラベル | reranking またはルールフィルタ |
| 古い情報で答える | 文書版とインデックス作成時刻 | インデックス再構築と回帰テスト |
| 改善したか分からない | 同じ質問での before/after 回答 | 固定評価セットを作る |
よくある失敗
- 「ベクトルデータベースにつないだ」だけで RAG 完了と思う。品質は文書、チャンク、順位、Prompt、引用、評価にも左右されます。
- チェーンを理解する前にフレームワークへ進む。query、chunks、prompt、answer、source を表示できてからの方が学びやすいです。
- 検索が空でもモデルに無理に答えさせる。使える RAG アプリは「提供資料では分からない」と言えます。
- metadata を忘れる。出典、ページ、章、版がないと、引用も調査も弱くなります。
- 感覚で最適化する。chunk、検索、reranking、Prompt を変えるたび、同じ評価質問で比べます。
クリア確認
第 9 章へ進む前に、次をできるようにしてください。
- RAG が私有・新しい・引用可能な知識問題を解く理由を説明できる。
- Tiny RAG スクリプトを動かし、回答前に top-k チャンクを確認できる。
- 出典 metadata 付き chunk を作り、回答でその出典を引用できる。
- 文書、チャンク、検索、生成、引用、配置の失敗を分けられる。
- 第 8 章フルワークショップを動かし、文書1つと評価ケース1つを追加し、README に結果を残せる。
印刷用チェックリストは 8.0 学習チェックリスト を使ってください。プロジェクトから始めたい場合は 8.5.6 実践:第 8 章 RAG アプリ完全ワークショップ へ進みます。