8.5.6 実践:第 8 章 RAG アプリ完全ワークショップ
このワークショップでは、第 8 章の主線を 1 つの動く小さなプロジェクトにまとめます。最初から LangChain、ベクトルデータベース、クラウド API には入りません。まずは純粋な Python で透明な RAG ループを作り、初心者でも各ステップで何が起きているかを見えるようにします。
目的は、この 1 ページで最強のシステムを作ることではありません。動かせる、調べられる、わざと壊して直せる、そして後から実際の embedding、ベクトルデータベース、モデル API、デプロイコードへ少しずつ置き換えられる小さな土台を作ることです。
何を作るのか
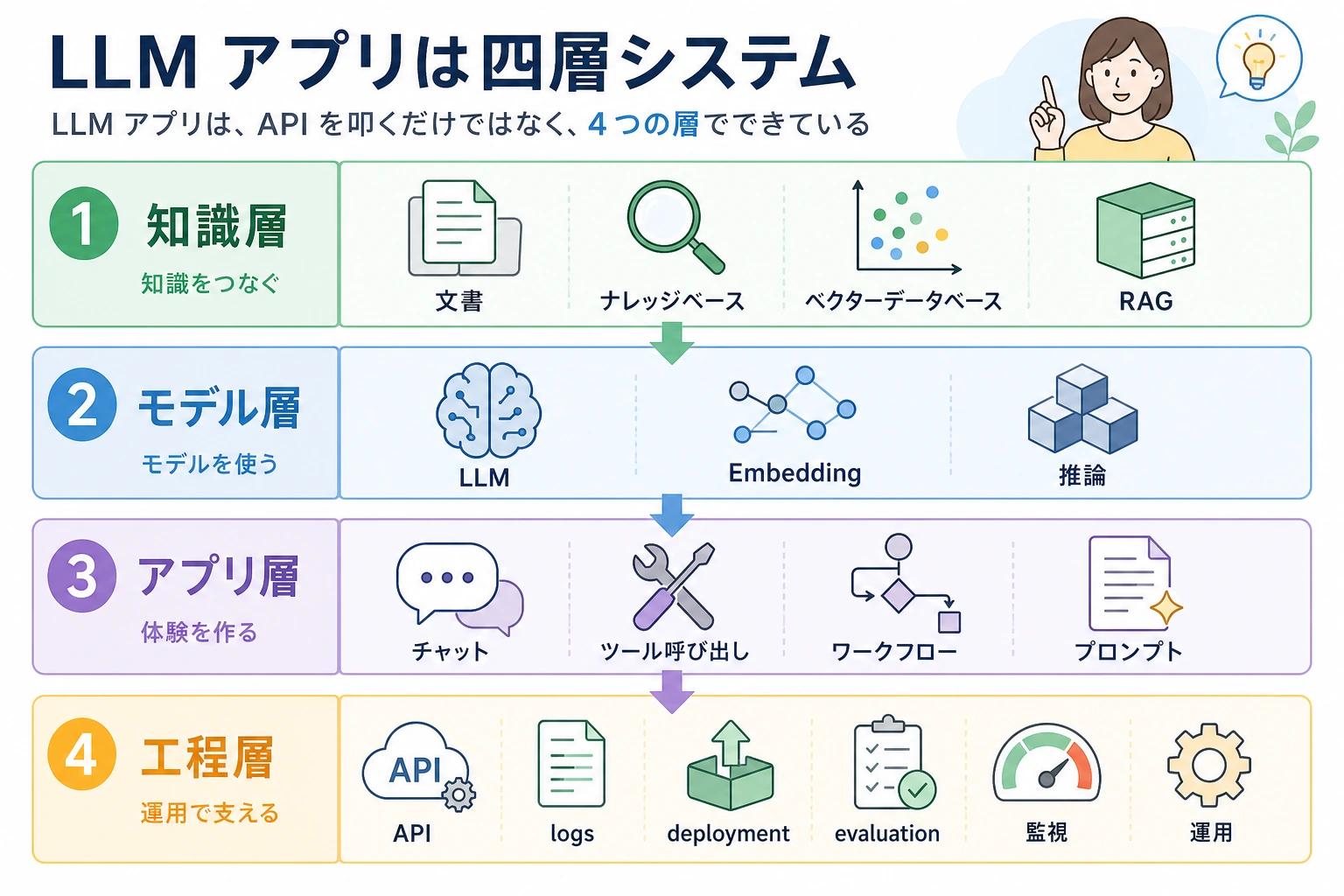
小さなナレッジベースアシスタントを作り、次の能力を入れます。
| 能力 | 実装すること | なぜ重要か |
|---|---|---|
| 文書取り込み | 4 つの小さな文書を構造化レコードで保存する | RAG は管理できる資料から始まる |
| 分割 | 各文書を検索しやすい chunk に分ける | 検索対象は普通、文書全体ではなく断片 |
| メタデータ | source、roles、title、chunk_id を保持する | 引用、権限、評価にはメタデータが必要 |
| 検索 | キーワードの重なりで chunk に点数を付ける | 初心者でもなぜ選ばれたか確認できる |
| 権限フィルタ | public ユーザーから employee-only の断片を隠す | 企業 RAG では内部知識を漏らせない |
| 回答生成 | 検索された証拠だけで答える | 出典のない内容を作らないため |
| 回答不能処理 | 証拠がないときは明確な状態を返す | 良い RAG は「分からない」と言える |
| 評価 | 3 つの固定テスト質問を実行する | 最適化前に再現できるチェックが必要 |
この順番で進めてください。図を見る、コードを写す、実行する、出力を比べる、説明を読む。いきなりフレームワークのコードへ飛ばないでください。フレームワークは、ループを理解した後に効いてきます。
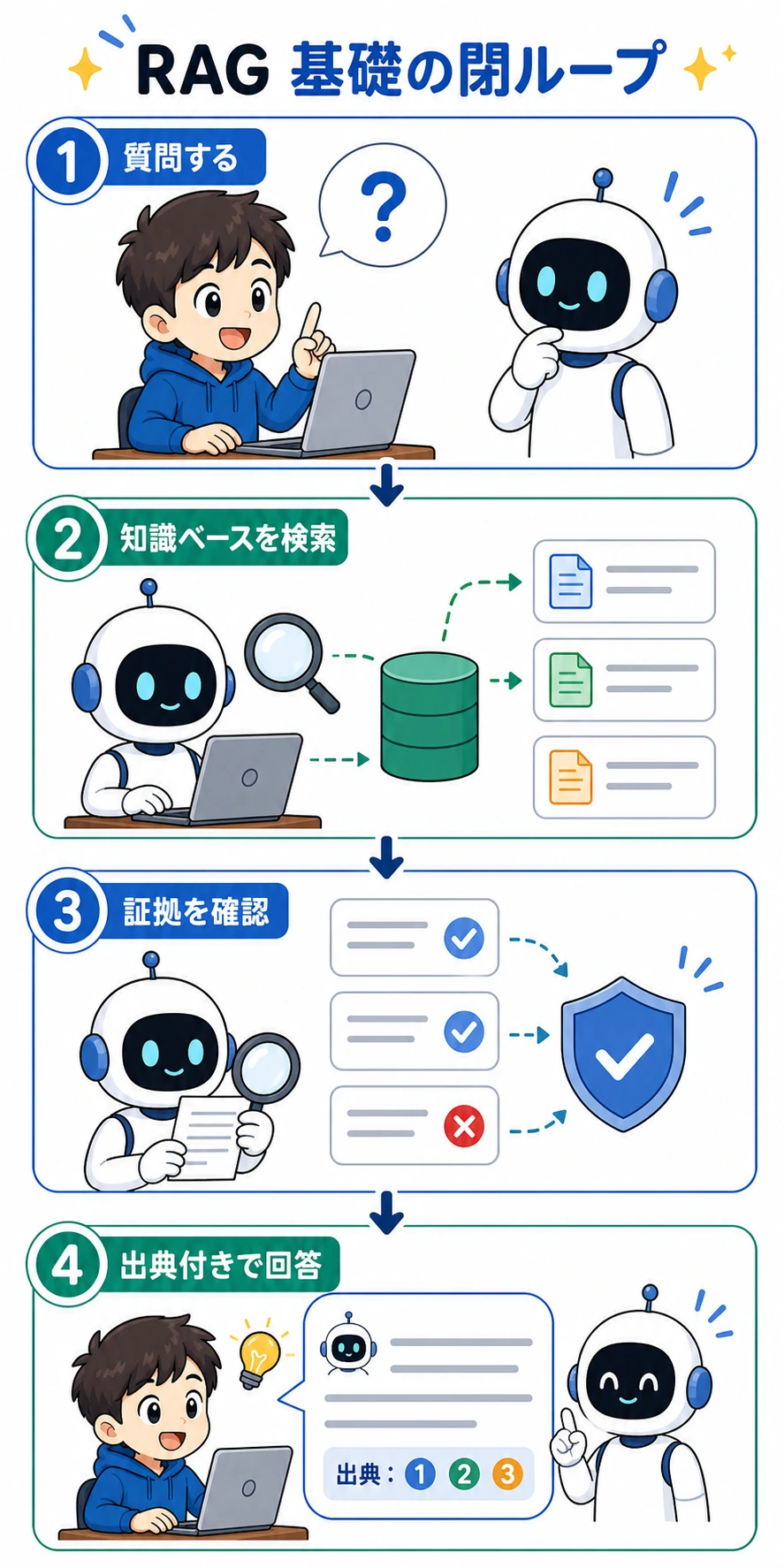
Step 0:コードを書く前に RAG ループを理解する

RAG は Retrieval-Augmented Generation の略で、日本語では「検索拡張生成」と呼ばれます。かみ砕くと次の流れです。
- ユーザーが質問する。
- システムが関連する文書 chunk を検索する。
- システムがその chunk をモデルに渡す。
- モデルが chunk に基づいて答える。
- 最終回答に引用を付け、人が出典を確認できるようにする。
初心者にとって一番大事なのは、最終回答が間違っていても、最初にモデルを疑わないことです。まず検索された chunk を出力しましょう。検索が間違っていれば、生成だけで安定して取り戻すのは難しいです。
Step 1:小さなプロジェクトフォルダを作る
ターミナルで実行します。
mkdir ch08_rag_workshop
cd ch08_rag_workshop
touch rag_app_workshop.py
必要なのは Python 3.10 以降だけです。最初のスクリプトは Python 標準ライブラリだけで動きます。
Step 2:完全なオフライン RAG スクリプトをコピーする
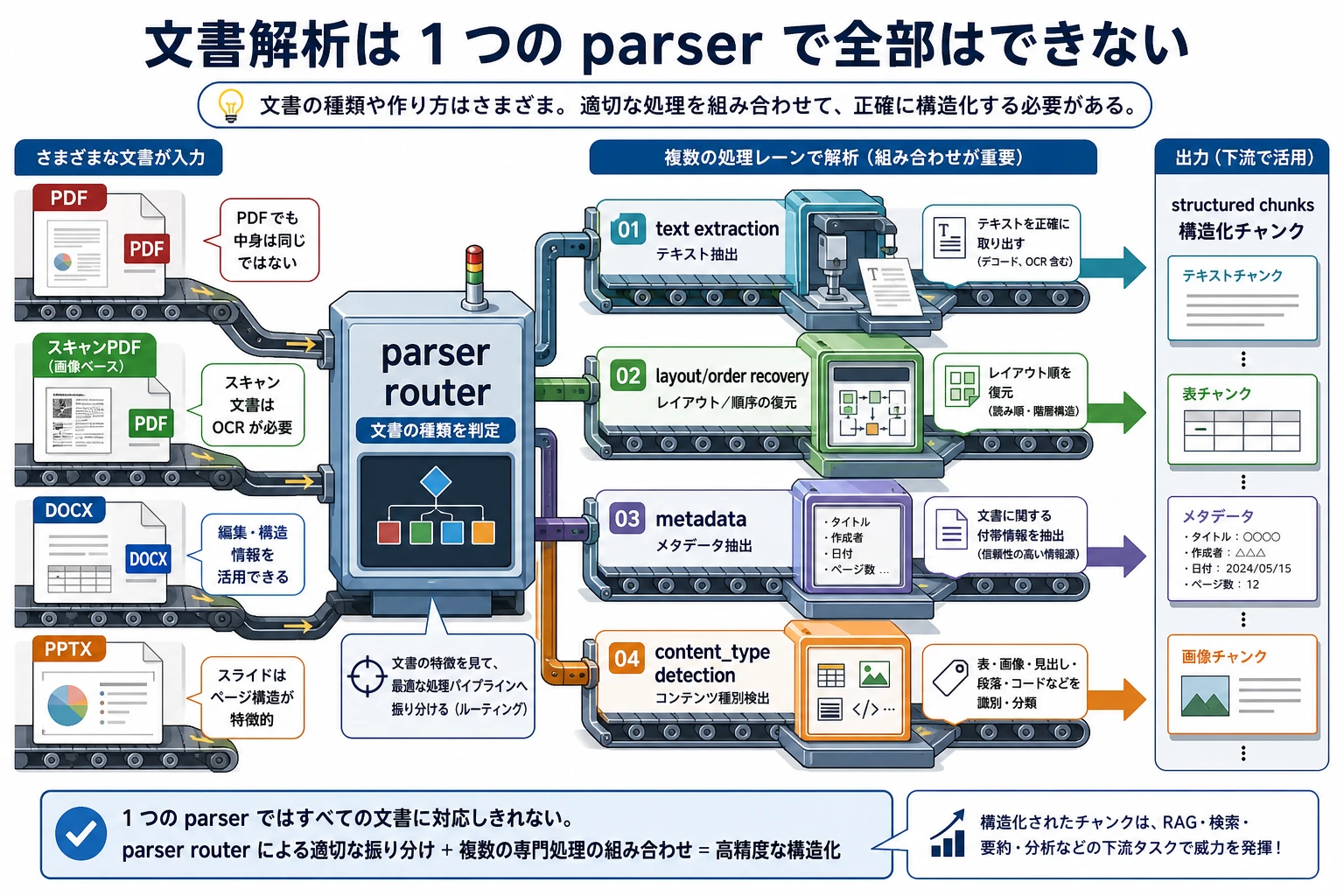
実際のプロジェクトでは、文書は Markdown、PDF、Word、PPT、HTML、データベースなどから来ます。この入門ワークショップでは、流れを見やすくするために 4 つのインメモリ文書を使います。各文書には最初からメタデータがあります。後の引用、ログ、権限チェック、評価がすべてそれに依存するからです。
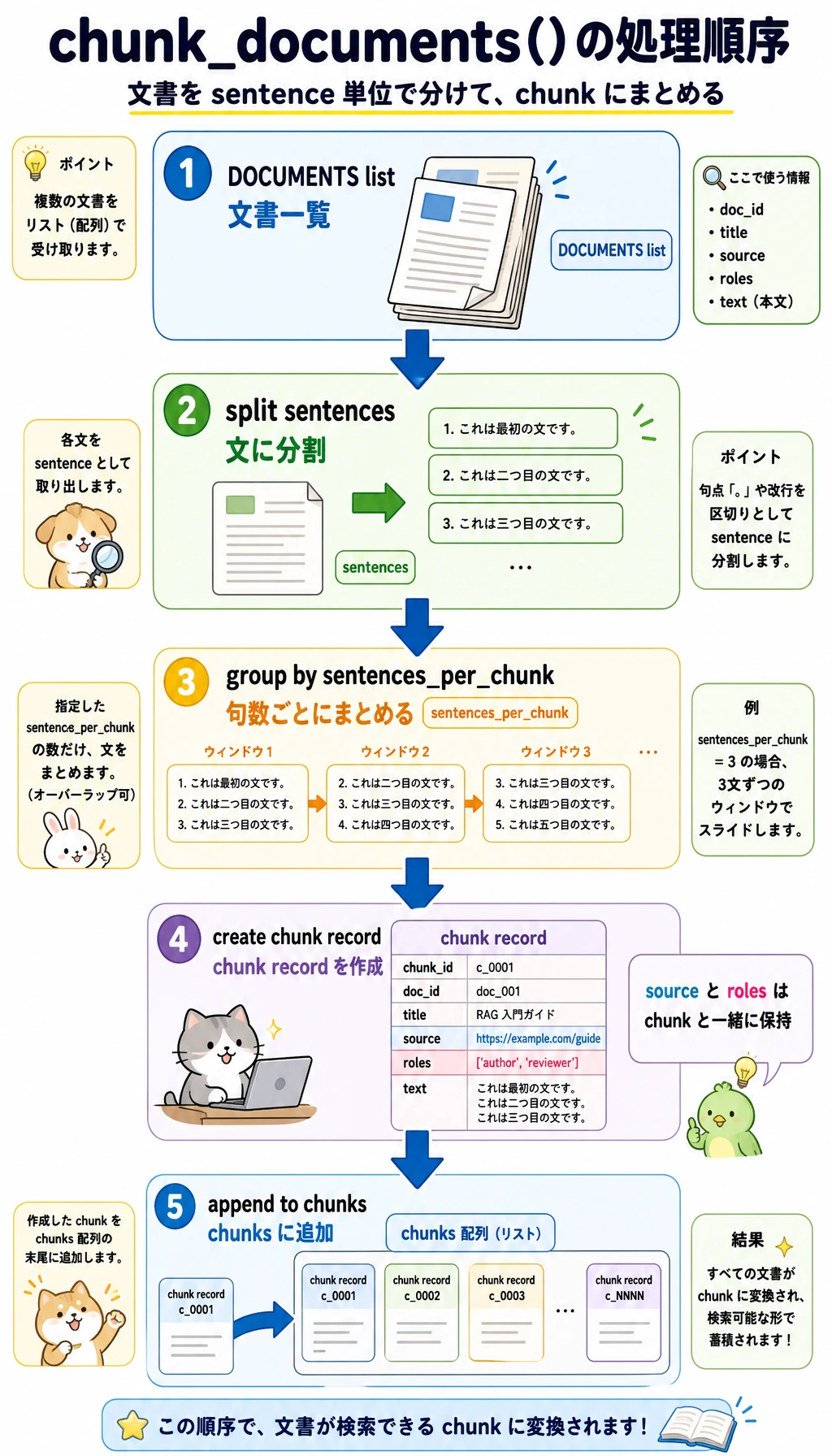
完全なスクリプトを写す前に、次の図で chunk_documents() だけを追いかけてください。後でコードを見るときは、DOCUMENTS から sentences、そして各 chunk レコードへ視線を移します。大事なのは、source と roles を各 chunk と一緒に持ち運ぶことです。検索と権限チェックが安全になります。
次のコードを rag_app_workshop.py にコピーしてください。
import re
from collections import Counter
DOCUMENTS = [
{
"doc_id": "refund-policy",
"title": "Course refund policy",
"source": "handbook.md#refund",
"roles": ["public"],
"text": (
"Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course. "
"Approved refunds are returned to the original payment method within 5 business days."
),
},
{
"doc_id": "api-key-setup",
"title": "API key setup guide",
"source": "setup.md#keys",
"roles": ["public"],
"text": (
"Store the API key in an environment variable named OPENAI_API_KEY before running the application. "
"Never paste production keys into Markdown files, browser screenshots, or public issue trackers."
),
},
{
"doc_id": "office-hours",
"title": "Course support hours",
"source": "support.md#hours",
"roles": ["public"],
"text": (
"Live office hours happen every Wednesday at 19:00 Taipei time. "
"Learners should bring the question, the command they ran, and the exact error output."
),
},
{
"doc_id": "private-roadmap",
"title": "Private product roadmap",
"source": "internal.md#roadmap",
"roles": ["employee"],
"text": (
"The beta roadmap targets a private release in Q4 after security review is complete. "
"Only employees may view roadmap dates before the public announcement."
),
},
]
STOPWORDS = {
"a", "an", "and", "are", "as", "at", "be", "before", "by", "do", "does",
"for", "from", "has", "have", "how", "in", "is", "it", "of", "on", "or",
"should", "the", "they", "to", "what", "when", "where", "which", "with",
}
def normalize(text):
tokens = []
for token in re.findall(r"[a-z0-9]+", text.lower()):
if len(token) > 3 and token.endswith("s"):
token = token[:-1]
if token not in STOPWORDS:
tokens.append(token)
return tokens
def chunk_documents(documents, sentences_per_chunk=2):
chunks = []
for doc in documents:
sentences = [s.strip() for s in re.split(r"(?<=[.!?])\s+", doc["text"]) if s.strip()]
for start in range(0, len(sentences), sentences_per_chunk):
chunk_text = " ".join(sentences[start : start + sentences_per_chunk])
chunks.append(
{
"chunk_id": f"{doc['doc_id']}#{start // sentences_per_chunk + 1}",
"doc_id": doc["doc_id"],
"title": doc["title"],
"source": doc["source"],
"roles": doc["roles"],
"text": chunk_text,
}
)
return chunks
def keyword_score(query, chunk):
query_terms = set(normalize(query))
chunk_terms = Counter(normalize(chunk["title"] + " " + chunk["text"]))
return sum(chunk_terms[term] for term in query_terms)
def retrieve(query, chunks, role="public", top_k=2):
allowed_hits = []
blocked_hits = []
for chunk in chunks:
score = keyword_score(query, chunk)
if score == 0:
continue
hit = {**chunk, "score": score}
if "public" in chunk["roles"] or role in chunk["roles"]:
allowed_hits.append(hit)
else:
blocked_hits.append(hit)
allowed_hits.sort(key=lambda hit: (-hit["score"], hit["chunk_id"]))
blocked_hits.sort(key=lambda hit: (-hit["score"], hit["chunk_id"]))
return {"hits": allowed_hits[:top_k], "blocked": blocked_hits[:top_k]}
def build_answer(query, retrieval):
hits = retrieval["hits"]
if not hits:
status = "blocked_by_permission" if retrieval["blocked"] else "no_evidence"
return {
"status": status,
"answer": "I do not have enough permitted evidence to answer this question.",
"citations": [],
}
top = hits[0]
first_sentence = re.split(r"(?<=[.!?])\s+", top["text"])[0]
return {
"status": "answered",
"answer": f"Based on {top['source']}: {first_sentence}",
"citations": [top["source"]],
}
def rag_answer(query, chunks, role="public"):
retrieval = retrieve(query, chunks, role=role, top_k=2)
answer = build_answer(query, retrieval)
return {"query": query, "role": role, "retrieval": retrieval, **answer}
EVAL_CASES = [
{
"name": "refund_window",
"question": "How many days do learners have for refunds?",
"role": "public",
"expected_status": "answered",
"expected_source": "handbook.md#refund",
},
{
"name": "api_key_setup",
"question": "Where should I store the API key?",
"role": "public",
"expected_status": "answered",
"expected_source": "setup.md#keys",
},
{
"name": "private_block",
"question": "What is the private beta roadmap for Q4?",
"role": "public",
"expected_status": "blocked_by_permission",
"expected_source": None,
},
]
def evaluate(chunks):
rows = []
passed = 0
for case in EVAL_CASES:
result = rag_answer(case["question"], chunks, role=case["role"])
status_ok = result["status"] == case["expected_status"]
citation_ok = case["expected_source"] is None or case["expected_source"] in result["citations"]
ok = status_ok and citation_ok
passed += int(ok)
rows.append({"name": case["name"], "ok": ok, "status": result["status"], "citations": result["citations"]})
return passed, rows
def main():
chunks = chunk_documents(DOCUMENTS)
print("STEP 1: parse and chunk documents")
print(f"chunks: {len(chunks)}")
print(f"first_chunk: {chunks[0]['chunk_id']} -> {chunks[0]['title']}")
print()
print("STEP 2: answer with citations")
result = rag_answer("How many days do learners have for refunds?", chunks)
print(f"question: {result['query']}")
print(f"status: {result['status']}")
print(f"answer: {result['answer']}")
print(f"citations: {', '.join(result['citations'])}")
print()
print("STEP 3: permission and no-evidence checks")
private_result = rag_answer("What is the private beta roadmap for Q4?", chunks, role="public")
unknown_result = rag_answer("What is the cafeteria menu today?", chunks, role="public")
print(f"private_question_as_public: {private_result['status']}")
print(f"unknown_question: {unknown_result['status']}")
print()
print("STEP 4: mini evaluation")
passed, rows = evaluate(chunks)
for row in rows:
mark = "PASS" if row["ok"] else "FAIL"
citations = ", ".join(row["citations"]) if row["citations"] else "none"
print(f"{row['name']}: {mark} ({row['status']}, {citations})")
print(f"passed: {passed}/{len(rows)}")
if __name__ == "__main__":
main()
Step 3:実行して出力を比べる
実行します。
python3 rag_app_workshop.py
期待される出力:
STEP 1: parse and chunk documents
chunks: 4
first_chunk: refund-policy#1 -> Course refund policy
STEP 2: answer with citations
question: How many days do learners have for refunds?
status: answered
answer: Based on handbook.md#refund: Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course.
citations: handbook.md#refund
STEP 3: permission and no-evidence checks
private_question_as_public: blocked_by_permission
unknown_question: no_evidence
STEP 4: mini evaluation
refund_window: PASS (answered, handbook.md#refund)
api_key_setup: PASS (answered, setup.md#keys)
private_block: PASS (blocked_by_permission, none)
passed: 3/3
出力が一致すれば、第 8 章の最小ループはもう動いています。資料が入り、chunk が作られ、検索され、権限フィルタが動き、引用付き回答が生成され、評価で振る舞いが確認されています。
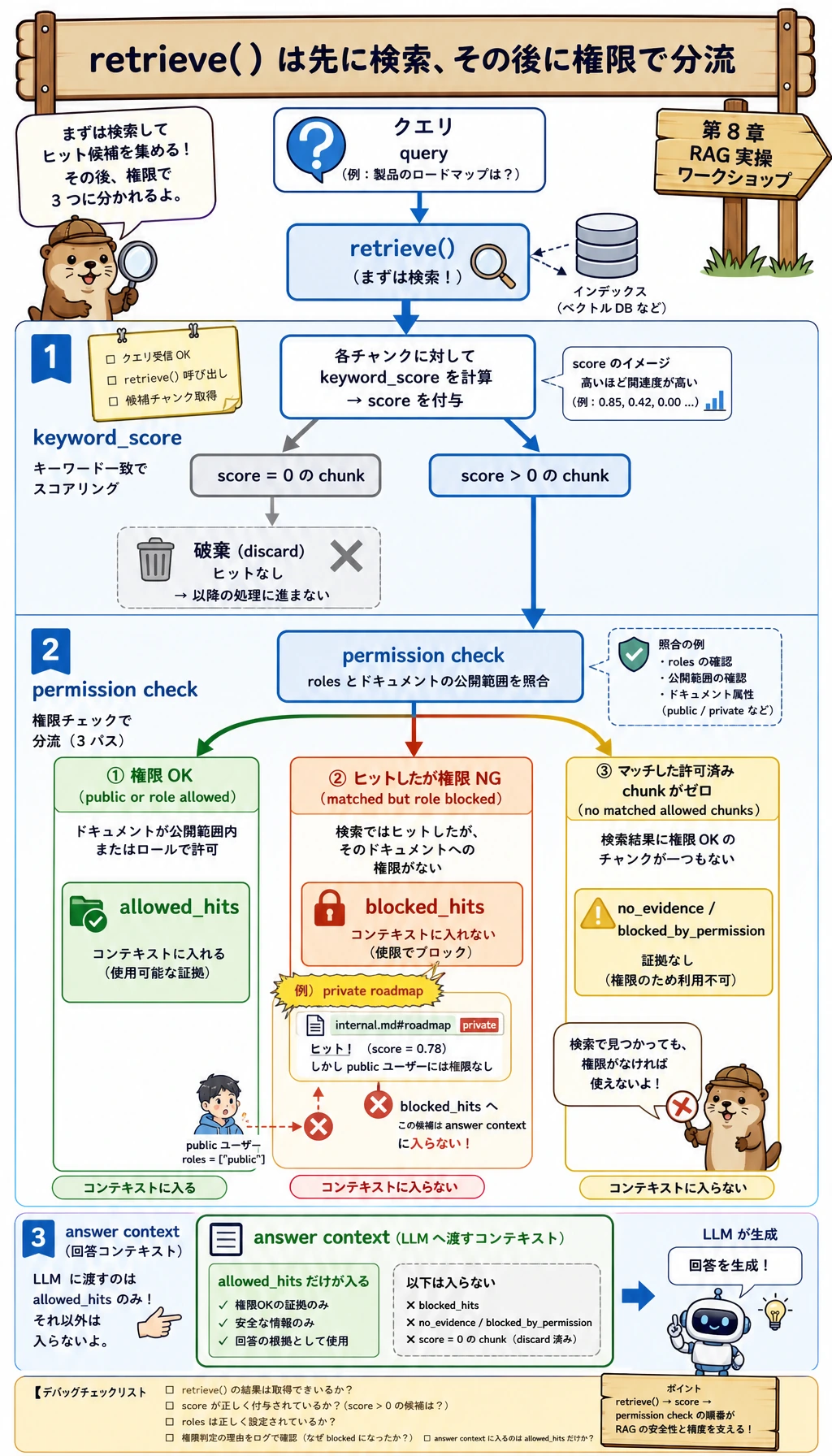
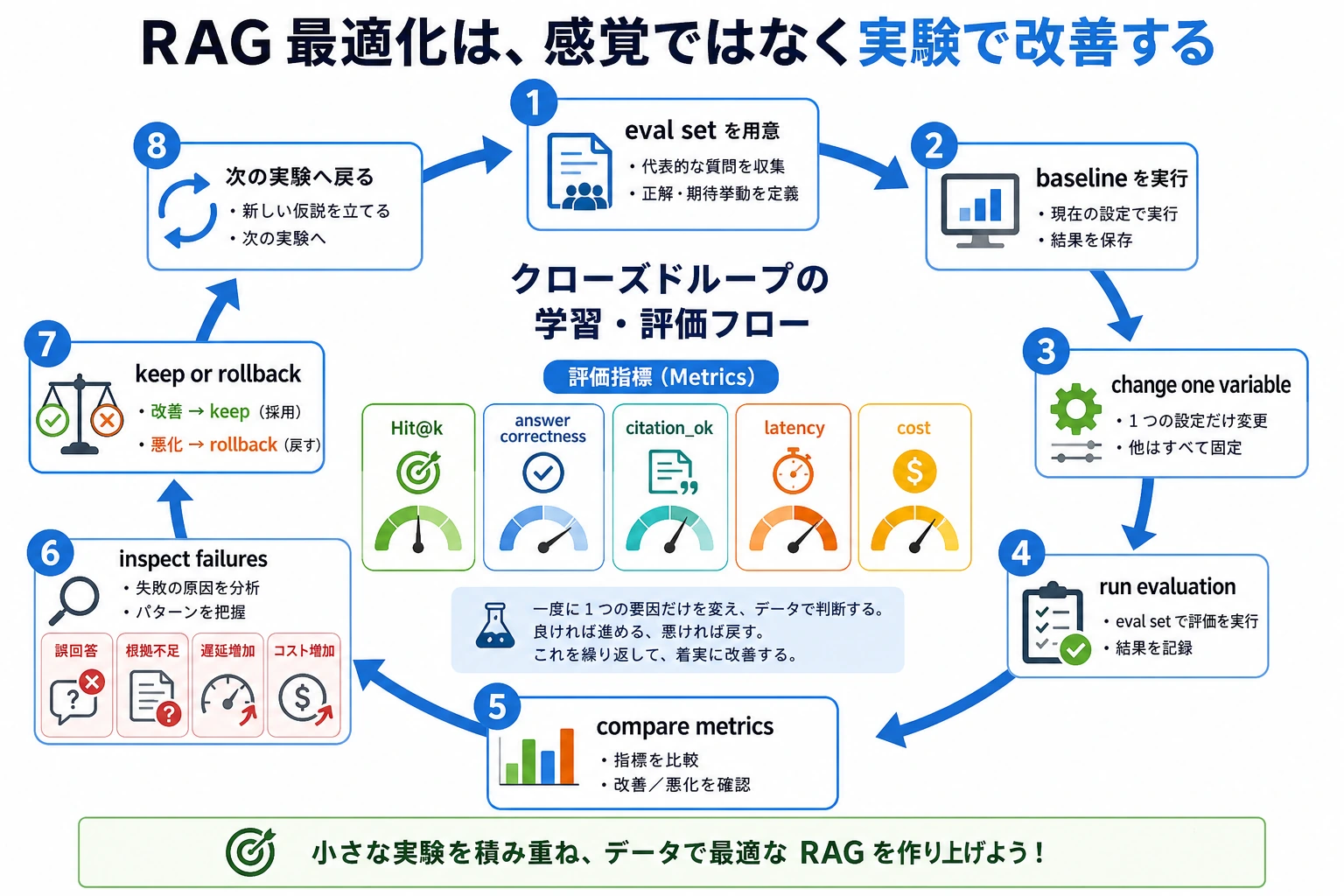
評価部分はこの図で読みます。evaluate() は感覚で回答品質を判定しません。EVAL_CASES を 1 件ずつ実行し、status と citations を確認して、PASS/FAIL を数えます。private_block は citation がなくても PASS です。期待される動きが blocked_by_permission だからです。

Step 4:パイプラインとしてコードを読む
スクリプトはこの順番で読んでください。
| コード箇所 | 確認すること | 初心者向けの意味 |
|---|---|---|
DOCUMENTS | doc_id、source、roles、text | 小さなナレッジベース |
chunk_documents() | 文書が chunk レコードになる流れ | chunk は後で検索される単位 |
normalize() | テキストが比較しやすい token になる流れ | 検索には共通の照合形式が必要 |
keyword_score() | chunk に点数が付く仕組み | 点が高いほど質問語が多く一致した |
retrieve() | 許可されたヒットとブロックされたヒット | 検索品質と権限安全は分けて見る |
build_answer() | 回答不能と引用をどう扱うか | システムは出典のない回答を出してはいけない |
EVAL_CASES | 固定質問と期待される振る舞い | 評価は「良さそう」を再現可能なチェックに変える |
今の検索はわざと単純にしています。embedding の代わりではなく、点数の理由を見えるようにする教材です。後で keyword_score() を embedding やハイブリッド検索に置き換えても、周辺の RAG 構造はほぼ同じままにできます。
Step 5:権限と引用の振る舞いを見る
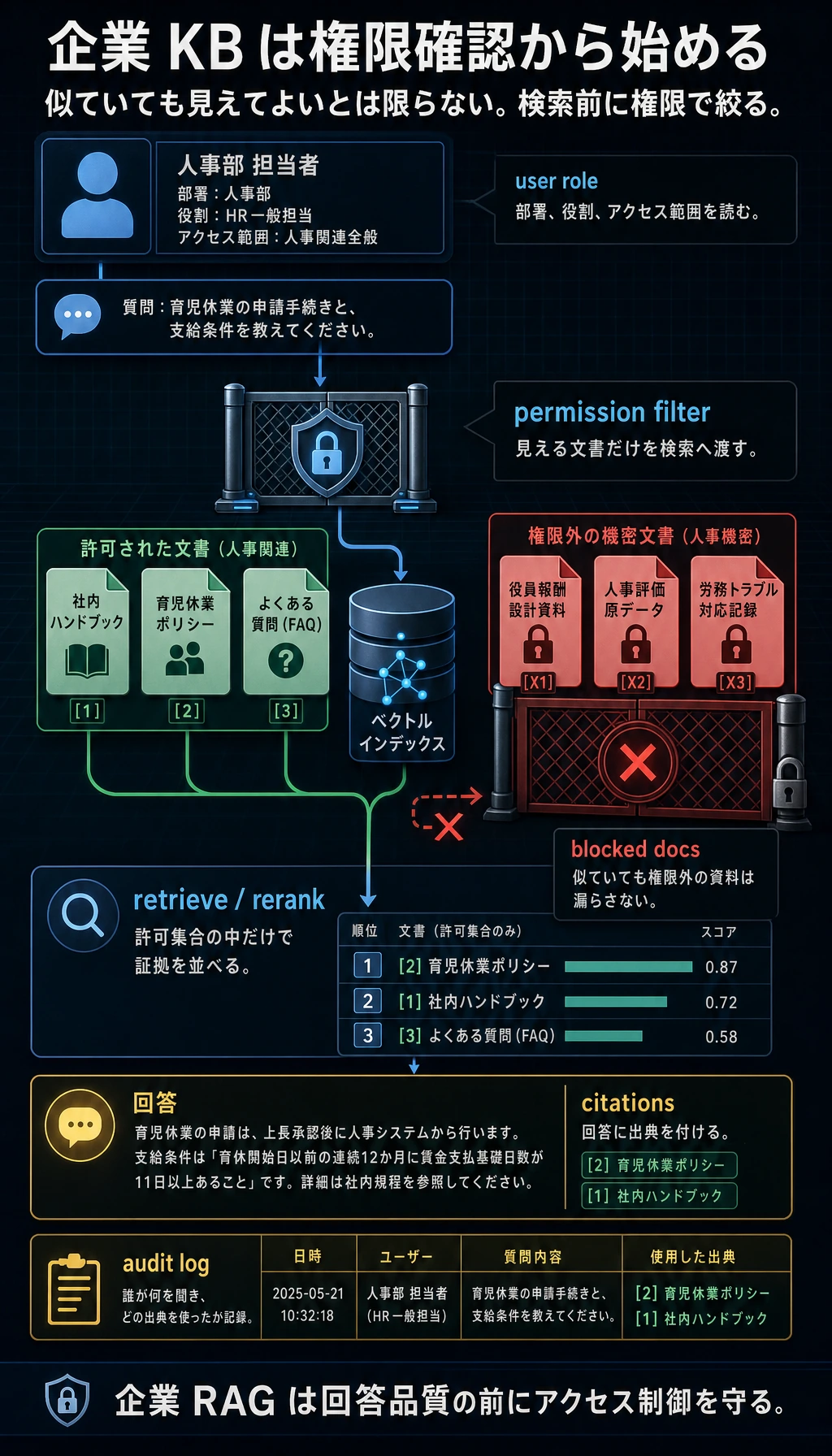
ここで retrieve() 内部の分岐に注目します。キーワードに一致した chunk が、そのまま証拠になるわけではありません。まずロールチェックを通る必要があります。一致していても、このユーザーが見られない private chunk は blocked_hits に入り、answer context には入りません。
この文書を見てください。
{
"doc_id": "private-roadmap",
"source": "internal.md#roadmap",
"roles": ["employee"],
"text": "The beta roadmap targets a private release in Q4 ..."
}
public ユーザーがこう聞きます。
What is the private beta roadmap for Q4?
キーワード検索自体は内部文書の chunk を見つけられます。しかし retrieve() はそれを allowed_hits ではなく blocked_hits に入れます。そのため出力は次のようになります。
private_question_as_public: blocked_by_permission
実プロジェクトではこの区別が重要です。no_evidence は使える証拠が見つからなかったという意味です。blocked_by_permission は証拠が存在するかもしれないが、このユーザーには見せられないという意味です。この 2 つはログでも分けて扱いましょう。
Step 6:フレームワークを足す前に trace 思考を作る
実際の LLM アプリでは、trace は 1 回のリクエストで何が起きたかの記録です。まだログファイルを保存しなくても、次の流れは説明できるようにします。
| Trace 段階 | このスクリプトでの場所 | 後で記録したいもの |
|---|---|---|
| Input | query、role | ユーザー ID、セッション ID、リクエスト ID |
| Parse | chunk_documents() | 文書バージョン、パーサー名 |
| Retrieve | retrieve() | top-k chunk、スコア、クエリ書き換え |
| Permission | allowed_hits、blocked_hits | ロール、ポリシー、ブロックされた source 数 |
| Answer | build_answer() | 状態、引用、モデル名 |
| Evaluate | evaluate() | 合格/失敗、失敗理由 |
だから第 8 章は、Prompt だけではなくアプリケーションエンジニアリングなのです。信頼できるシステムには、途中状態が見える必要があります。
Step 7:embedding、ベクトルデータベース、API への拡張ルート

オフラインスクリプトが動いたら、一度に 1 つだけ置き換えます。
| 今の単純な部分 | 後の本番向け部品 | 残すべき習慣 |
|---|---|---|
インメモリの DOCUMENTS | Markdown/PDF/Word パーサーと保存先 | source メタデータを残す |
| 文単位の分割 | 見出しベースまたは token ベースの分割 | chunk ID を安定させる |
keyword_score() | embedding、ハイブリッド検索、リランキング | top-k とスコアを出す |
roles リスト | 実際の認証と認可 | 回答前に必ずフィルタする |
| 抽出的な回答 | grounded prompt 付きモデル呼び出し | 引用を必須にする |
EVAL_CASES | より大きな評価セットと回帰チェック | 変更後も同じ質問で比べる |
すべてを同時に置き換えないでください。解析、embedding、ベクトル DB、prompt、モデルを一度に変えると、改善や悪化の原因が分からなくなります。
Step 8:任意の OpenAI Responses API 拡張
オフラインスクリプトは初心者にとって必須の道です。それが動いた後で、build_answer() を実際のモデル呼び出しに置き換えられます。現在の OpenAI ドキュメントでは Responses API の利用が案内されており、モデル一覧では複雑な推論やコーディング系タスクの出発点として gpt-5.5 が示されています。後で安価なモデルや授業指定モデルへ切り替えられるよう、モデル名は設定可能にしておきます。
依存関係を入れます。
python3 -m venv .venv
source .venv/bin/activate
pip install "openai>=2" "pydantic>=2"
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_MODEL="gpt-5.5"
ask_with_openai.py を作ります。
import json
import os
from openai import OpenAI
client = OpenAI()
query = "How many days do learners have for refunds?"
context = [
{
"source": "handbook.md#refund",
"text": "Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course.",
}
]
response = client.responses.create(
model=os.getenv("OPENAI_MODEL", "gpt-5.5"),
input=[
{
"role": "system",
"content": (
"Answer only from the provided context. "
"If the context is insufficient, return status no_evidence. "
"Always include citations from the source fields."
),
},
{
"role": "user",
"content": json.dumps({"question": query, "context": context}, ensure_ascii=False),
},
],
text={
"format": {
"type": "json_schema",
"name": "rag_answer",
"strict": True,
"schema": {
"type": "object",
"additionalProperties": False,
"properties": {
"status": {"type": "string", "enum": ["answered", "no_evidence"]},
"answer": {"type": "string"},
"citations": {"type": "array", "items": {"type": "string"}},
},
"required": ["status", "answer", "citations"],
},
}
},
)
print(response.output_text)
実行します。
python3 ask_with_openai.py
期待される形:
{"status":"answered","answer":"Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course.","citations":["handbook.md#refund"]}
モデルが引用なしの文章を返した場合、それはチェック失敗として扱います。本番では出力を検証し、より厳しい指示で再試行するか、制御されたエラーを返します。出典のない回答をそのままユーザーに出してはいけません。
Step 9:Function Calling と構造化出力の考え方
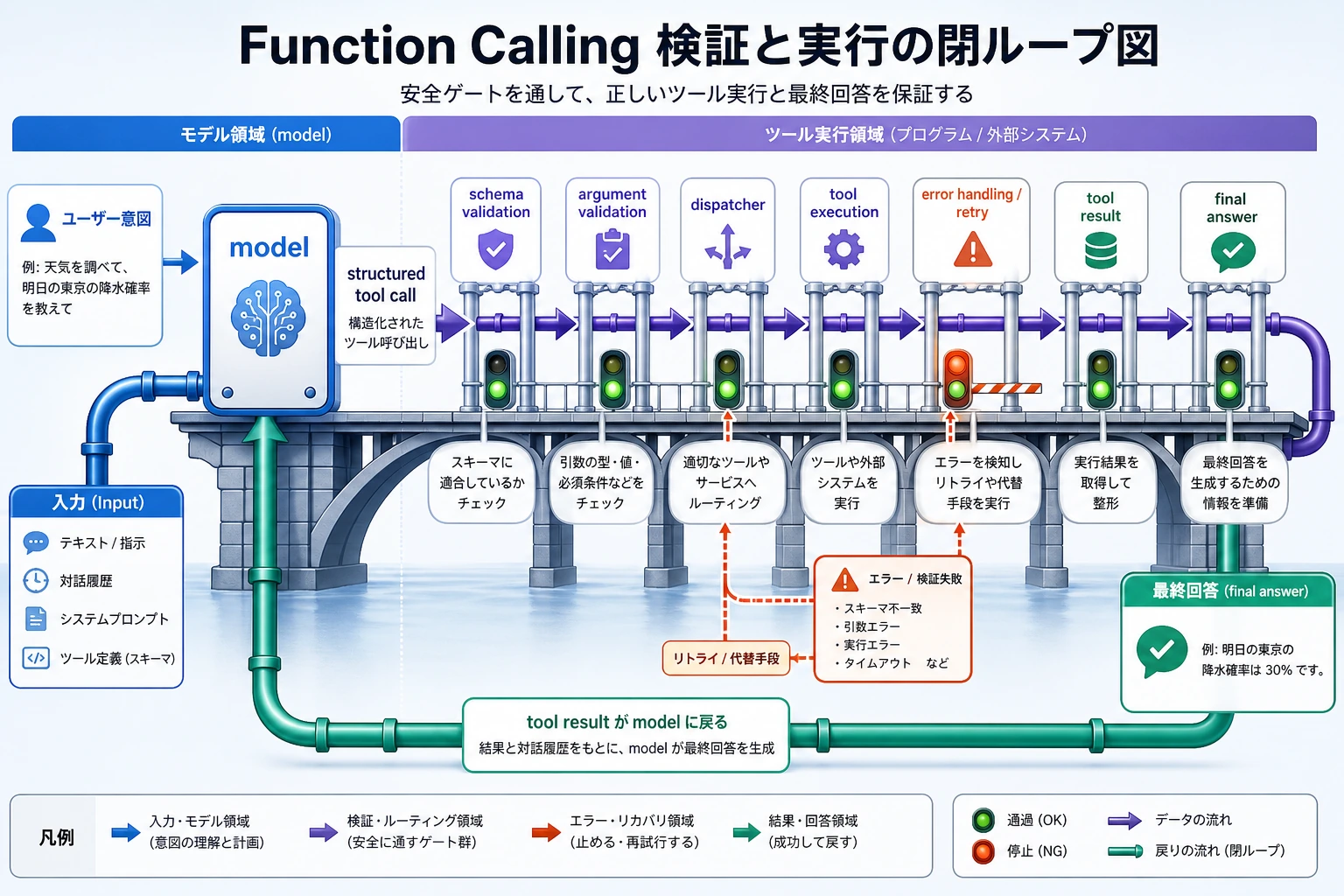
このワークショップでは、retrieve() は普通の Python 関数です。モデル駆動のアプリでは、モデルが search_knowledge_base、get_user_profile、create_ticket のようなツールを呼ぶ判断をすることがあります。
安全なパターンは次の通りです。
| 段階 | 起きること | 安全ポイント |
|---|---|---|
| Schema | ツール入力フィールドを定義する | 足りないフィールドや未知のフィールドを拒否する |
| Validation | ロール、source、許可された操作を確認する | モデルの引数をそのまま信じない |
| Dispatch | 実際の関数を実行する | 副作用を制御する |
| Observation | 結果をモデルに返す | 先に private データをフィルタする |
| Final answer | 引用付き回答または回答不能状態を返す | 表示前に検証する |
オフラインスクリプトも同じ習慣を練習しています。検索、権限、回答、評価は分けて扱います。
Step 10:よくあるエラーのチェックリスト

| 症状 | よくある原因 | まず見るもの | 修正方針 |
|---|---|---|---|
chunks: 0 | 文書が正しく解析されていない | DOCUMENTS と文分割結果を出力する | 入力テキストまたはパーサーを直す |
| 元文書に答えがあるのに検索されない | 質問語と chunk の語が合わない | normalize(query) と chunk token を出す | 同義語、embedding、クエリ書き換えを追加する |
| 回答に引用がない | source メタデータが失われた | chunk レコードを確認する | すべての chunk に source を残す |
| public 回答に内部資料が出る | 権限フィルタが生成後にある | retrieve() の順序を見る | prompt/model 呼び出し前にフィルタする |
| 未知の質問に自信満々で答える | 回答不能処理がない | What is the cafeteria menu today? を試す | hits が空なら no_evidence を返す |
| 変更後に評価が悪くなる | 一度に多くの層を変えた | git diff と評価出力を比べる | 1 回に 1 層だけ変える |
Step 11:練習タスク
順番に取り組みます。
| レベル | タスク | 合格基準 |
|---|---|---|
| Easy | public 文書を 1 つ、評価ケースを 1 つ追加する | passed 数が増え、新しい引用が表示される |
| Standard | logs/retrieval_logs.jsonl を出力する | 各質問に query、role、status、score、citations が記録される |
| Standard | top_k 設定変数を追加する | top_k=1 と top_k=2 の結果を比較できる |
| Challenge | keyword_score() を embedding に置き換える | 同じ評価ケースでまだ動く |
| Challenge | 小さな FastAPI エンドポイントを追加する | /ask が status、answer、citations、trace ID を返す |
ワークショップの完了基準
次を説明・実行できれば、このワークショップは完了です。
python3 rag_app_workshop.pyを実行し、期待出力を得られる。chunk、metadata、top_k、citation、trace、evaluation setの意味を説明できる。- public ユーザーが
internal.md#roadmapにアクセスできない理由を示せる。 - 新しい文書と評価ケースを 1 つ追加しても、既存チェックを壊さない。
- embedding、ベクトルデータベース、実モデル API に進むとき、どの部分を最初に置き換えるべきか説明できる。
この小さなプロジェクトは、第 8 章の baseline として残しておきましょう。後で LangChain、ベクトルデータベース、デプロイ、監視、Agent が出てきたとき、このスクリプトに戻って比較します。フレームワークがどの責任を置き換えたのか、どの責任はまだアプリ側に残っているのかを確認するためです。