8.5.3 プロジェクト:RAG+微調整の統合システム
これまでに、あなたは次をそれぞれ学びました。
- RAG:モデルに先に資料を調べさせてから答えさせる
- 微調整:モデルをある種類のタスクやスタイルにより適応させる
この節で解決したいのは、次の問題です。
ある分野のシステムが外部知識も必要で、さらに特定の表現スタイルやタスク能力も必要なとき、どうすればよいのか?
このとき、RAG と微調整は「どちらか一方の代わり」ではなく、「組み合わせる関係」になることが多いです。
学習目標
- 「RAG だけ」や「微調整だけ」では足りないことがある理由を理解する
- 分野別Q&Aシステムを RAG 層と微調整層に分けて考えられるようになる
- 説明可能な RAG+微調整プロジェクト案を設計する
- 最小限の組み合わせ型プロジェクトの骨組みを動かす
初学者向けの用語ブリッジ
RAG と微調整を組み合わせる前に、学習関連の用語を分けて理解しておきましょう。
| 用語 | 初学者向けの意味 | 何を解決するものか |
|---|---|---|
fine-tuning | 基盤モデルに対して、タスク例で追加学習すること | 振る舞い、形式、分野らしい表現を安定させる |
SFT | Supervised Fine-Tuning。人が作成または整理した入力・出力例で学習する方法 | 良い回答の形をモデルに教える |
LoRA | Low-Rank Adaptation。小さな adapter 重みだけを学習する軽量な微調整方法 | 学習コストを下げながらモデルの振る舞いを調整する |
QLoRA | 量子化したモデル読み込みと LoRA を組み合わせる方法 | 小さめのハードウェアでも微調整を試しやすくする |
domain adaptation | 特定の分野や業務文脈にシステムを合わせること | 分野知識と、その分野らしい答え方の両方が必要になる |
eval set | 固定の評価質問と期待チェック項目のセット | 1つの良さそうな例だけで改善を判断しないため |
実務上のルールはこうです。頻繁に変わる文書を fine-tuning で覚えさせようとしない。変わる知識は RAG に任せ、安定した振る舞いや形式は fine-tuning や SFT 例で補います。
一、なぜ RAG と微調整を組み合わせるのか?
単独の RAG の強みと限界
RAG の強み:
- 知識を更新しやすい
- 出典を引用できる
- モデルを再学習しなくてよい
ただし、限界もあります。
- モデルがあなたの分野の表現を理解しているとは限らない
- 検索できても、業務の形式に合った答え方になるとは限らない
- 複雑なタスクでは、モデルの「答え方の癖」が安定しないことがある
単独の微調整の強みと限界
微調整の強み:
- モデルを特定のタスク形式によりよく合わせられる
- 出力スタイルが安定しやすい
- 指示への追従が業務に合いやすい
ただし、限界もあります。
- 新しい知識の更新にあまり柔軟ではない
- 微調整だけで細かい文書すべてを覚えさせるのは難しい
- コストが高くなりやすい
だからこそ、両者は補完関係になりやすい
まずは一言で覚えましょう。
RAG は知識を補い、微調整は振る舞いを補う。
これが組み合わせ型システムの核となる考え方です。
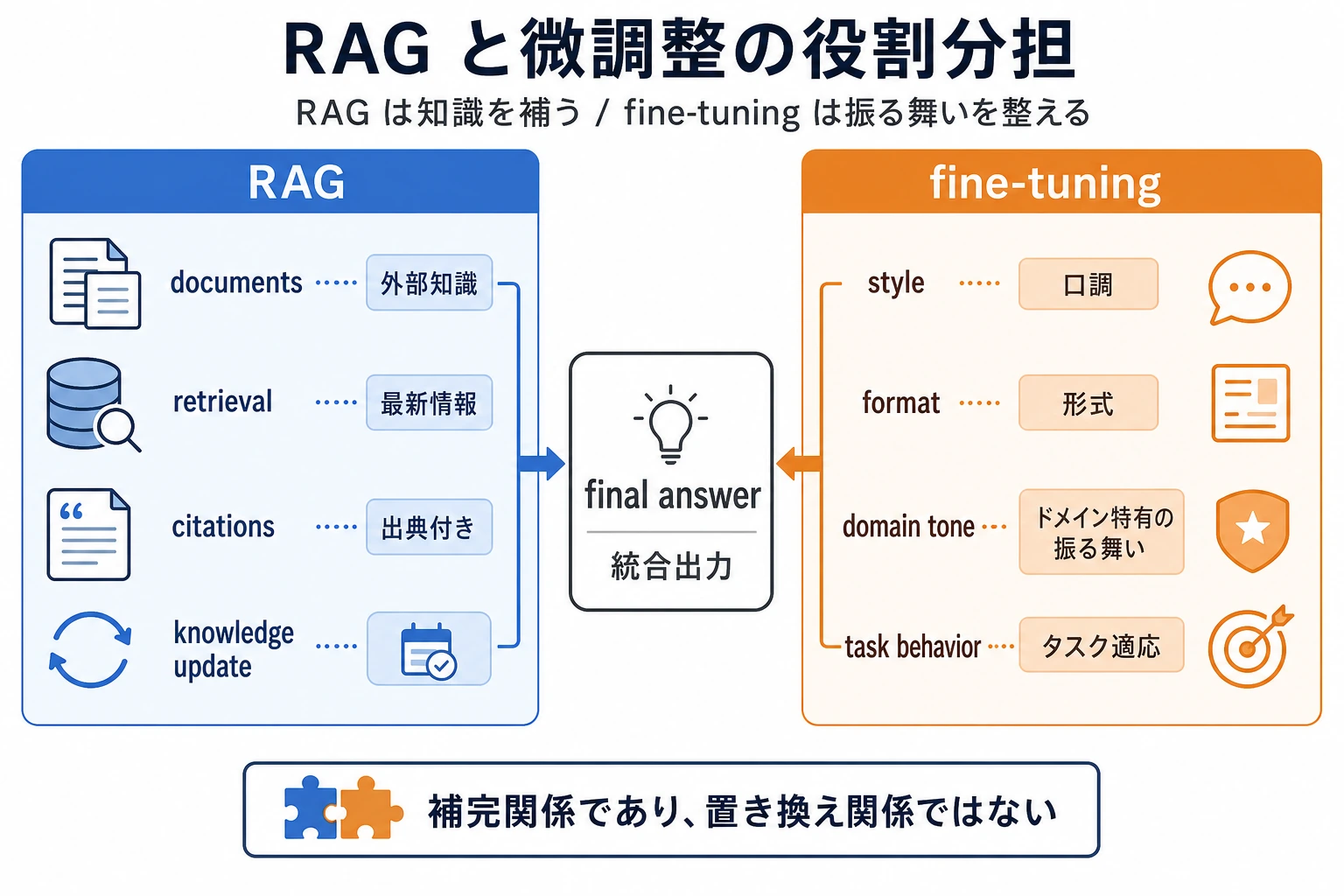
左側は RAG:知識更新、出典引用、外部文書。右側は fine-tuning:回答スタイル、形式の安定、業務ルール。役割を分けることで、システムは評価しやすく、保守もしやすくなります。
二、このプロジェクトでは何をするのか?
目標を、たとえば分野別Q&Aアシスタントに設定します。
- 社内ポリシー文書向け
- 回答時に出典を安定して引用する
- 出力形式を必ず統一する
- 一部の質問には固定の業務ルールで答える
つまり、このシステムは次の両方を満たす必要があります。
- 知識を見つけられる
- しかもその分野らしい答え方ができる
まずシステム構造を描く
この図で本当に大事なこと
重要なのは「部品が多いこと」ではなく、役割がはっきりしていることです。
- 検索器は資料を探す
- 微調整モデルは業務に合う形で答えをまとめる
これによって、システムはより説明しやすくなり、改善もしやすくなります。
最小限のナレッジベースと検索器
この例では、軽量な TF-IDF 検索器として scikit-learn を使います。ローカルで実行したい場合は、先にインストールしてください。
pip install scikit-learn
環境にすでに入っている場合は、この手順は不要です。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
kb = [
{"id": "doc1", "text": "返金ポリシー:購入後 7 日以内かつ学習進捗が 20% 未満なら返金可能です。"},
{"id": "doc2", "text": "修了証ポリシー:プロジェクトを完了しテストに合格すると修了証を取得できます。"},
{"id": "doc3", "text": "カスタマーサポート対応規範:回答時は、まずポリシーの根拠を示し、その後に結論を述べます。"}
]
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 4))
doc_vectors = vectorizer.fit_transform([item["text"] for item in kb])
def retrieve(query, top_k=2):
query_vec = vectorizer.transform([query])
scores = cosine_similarity(query_vec, doc_vectors)[0]
top_idx = scores.argsort()[::-1][:top_k]
return [kb[i] for i in top_idx]
print(retrieve("返金条件は何ですか"))
期待される出力:
[{'id': 'doc1', 'text': '返金ポリシー:購入後 7 日以内かつ学習進捗が 20% 未満なら返金可能です。'}, {'id': 'doc3', 'text': 'カスタマーサポート対応規範:回答時は、まずポリシーの根拠を示し、その後に結論を述べます。'}]
日本語の例では analyzer="char" と ngram_range=(2, 4) を使います。日本語は英語のように空白で単語が区切られないため、追加の分かち書きライブラリなしでも安定した教材用の結果にするためです。
この検索器自体は複雑ではありませんが、すでに組み合わせ型システムの前半部分になっています。
次に「微調整後の回答スタイル」をまねる
実際のプロジェクトでは、この部分はたとえば次のような方法で作られます。
- 指示微調整
- LoRA / QLoRA
- 教師ありデータセットでの学習
ここでは、コードをそのまま動かせるように、ルールで「すでに学習済みの業務出力スタイル」をまねます。
def domain_answer_style(question, retrieved_docs):
evidence = " ".join(doc["text"] for doc in retrieved_docs)
if "返金" in question:
return {
"answer": "現行の返金ポリシーによると、購入後 7 日以内かつ学習進捗が 20% 未満のユーザーは返金を申請できます。",
"reasoning_style": "先にポリシー、後で結論",
"evidence": evidence
}
if "修了証" in question:
return {
"answer": "修了証ポリシーによると、プロジェクトを完了しテストに合格すると修了証を取得できます。",
"reasoning_style": "先にポリシー、後で結論",
"evidence": evidence
}
return {
"answer": "現在のところ、十分に一致する業務ルールが見つかりませんでした。",
"reasoning_style": "慎重に回答を保留",
"evidence": evidence
}
なぜこのシミュレーションに意味があるのか?
これによって、次のことが分かりやすくなるからです。
- RAG が解決するのは「何を知っているか」
- 微調整が解決するのは「どう答えるか」
2つを本当に接続する
def rag_plus_finetune_system(question):
docs = retrieve(question, top_k=2)
result = domain_answer_style(question, docs)
return {
"question": question,
"retrieved_docs": docs,
**result
}
result = rag_plus_finetune_system("返金条件は何ですか?")
print(result["question"])
print(result["answer"])
print("evidence:", result["evidence"])
期待される出力:
返金条件は何ですか?
現行の返金ポリシーによると、購入後 7 日以内かつ学習進捗が 20% 未満のユーザーは返金を申請できます。
evidence: 返金ポリシー:購入後 7 日以内かつ学習進捗が 20% 未満なら返金可能です。 カスタマーサポート対応規範:回答時は、まずポリシーの根拠を示し、その後に結論を述べます。
このシステムは何を示しているのか?
これで示されるのは次のことです。
組み合わせ型システムは、2つの技術を無理やり足し合わせるのではなく、それぞれが得意な部分を担当するようにすることだ。
本当のプロジェクトでは、何を微調整することが多いのか?
「すべての文書を覚えさせる」ためではない
初心者の方は、次のように考えがちです。
微調整したら、モデルがナレッジベースを全部暗記するはず
でも、もっと一般的で現実的な目的は次のようなものです。
- 分野特有の用語の雰囲気を学ばせる
- 出力形式を学ばせる
- 業務用の回答テンプレートを学ばせる
- ある種類のタスクの固定構造を学ばせる
例を挙げると
モデルに次のようなことを学ばせたいかもしれません。
- 「まずポリシーを引用してから結論を出す」
- 「不確かな場合は明確に回答を保留する」
- 「すべての回答を標準フィールドで出力する」
こうした能力は、微調整、または少なくとも強い教師あり学習で強化するのに向いています。
プロジェクト価値の高い分け方
RAG 層が担当すること
- 文書のチャンク化
- 検索
- 出典引用
- 知識更新
微調整層が担当すること
- 回答スタイル
- 出力形式
- タスクテンプレート
- 業務用語の理解
この役割分担をはっきりさせると、プロジェクトの保守性はかなり良くなります。
この統合システムはどう評価するのか?
「答えが自然か」だけでは足りない
少なくとも、2つの層を見てください。
- 検索層:正しい文書を見つけられているか
- 回答層:出力が業務要件に合っているか
最小限の評価方法
eval_data = [
{"question": "返金条件は何ですか", "gold_doc": "doc1", "must_contain": "7 日以内"},
{"question": "修了証はどうやって取得しますか", "gold_doc": "doc2", "must_contain": "テストに合格"}
]
for item in eval_data:
result = rag_plus_finetune_system(item["question"])
hit = result["retrieved_docs"][0]["id"] == item["gold_doc"]
good_answer = item["must_contain"] in result["answer"]
print(item["question"], "retrieval_hit=", hit, "answer_ok=", good_answer)
期待される出力:
返金条件は何ですか retrieval_hit= True answer_ok= True
修了証はどうやって取得しますか retrieval_hit= True answer_ok= True
これだけでも、「ただデモがそれっぽく見えるか」を確認するより、ずっと前進しています。
小さなレイヤー診断ドリルを追加する
組み合わせ型システムが失敗したら、まずどの層が担当すべき問題かを切り分けます。この小さな表が、実プロジェクトの振り返りの入口になります。
diagnostics = [
{"symptom": "正しい文書が top-2 に入らない", "likely_layer": "RAG", "next_step": "チャンク化、クエリ書き換え、検索戦略を改善する"},
{"symptom": "正しい文書は取れているが、回答形式が安定しない", "likely_layer": "微調整 / プロンプト", "next_step": "教師あり例を増やすか schema を厳しくする"},
{"symptom": "回答は A を引用しているが、事実は B から来ている", "likely_layer": "grounding", "next_step": "引用チェックと文単位の根拠検証を追加する"},
]
for row in diagnostics:
print(f"{row['likely_layer']}: {row['symptom']} -> {row['next_step']}")
期待される出力:
RAG: 正しい文書が top-2 に入らない -> チャンク化、クエリ書き換え、検索戦略を改善する
微調整 / プロンプト: 正しい文書は取れているが、回答形式が安定しない -> 教師あり例を増やすか schema を厳しくする
grounding: 回答は A を引用しているが、事実は B から来ている -> 引用チェックと文単位の根拠検証を追加する

上から順に読んでください。RAG 層は正しい文書が取れているか、回答層は業務に合う形式で答えているかを見ます。失敗したときは、層別診断のメモから修正する層を決めます。
初心者がよくやる失敗
知識更新の問題を微調整で解決しようとする
これはたいてい効率がよくありません。
出力スタイルの安定化を RAG だけで無理に解決しようとする
これも、いつも適切とは限りません。
役割分担が曖昧になる
自分で「どの層が何を担当しているのか」を説明できないと、後から調整がとても難しくなります。
まとめ
この節で一番大事なのは、RAG と微調整という2つの言葉を並べることではありません。大事なのは、次を理解することです。
RAG+微調整の統合システムの価値は、「知識の取得」と「回答の振る舞い」を、それぞれ最も適した仕組みに任せられることにある。
これこそが、組み合わせ型 LLM システムの本当の設計思想です。
ポートフォリオ向け提出チェックリスト
このプロジェクトをポートフォリオに入れるなら、「1つ質問したら1つ答える」だけを見せるのはもったいないです。RAG 層、回答層、評価層、そして振り返り資料までまとめて出す方がよいです。
| 提出物 | 最低要件 | ポートフォリオ級の要件 |
|---|---|---|
| ナレッジベースのサンプル | 少なくとも 3~5 個の文書断片 | 元資料、チャンク結果、metadata フィールド、出典を示す |
| 検索ログ | 命中した文書を表示できる | query、top-k、score、source、context 長を保存する |
| 回答出力 | 答えを返せる | 結論、根拠、出典、「答えられない場合の保険」を含める |
| 評価セット | 2~5 個のテスト質問 | 20~50 問で、言い換え、境界条件、紛らわしい質問を含める |
| 失敗サンプル | 簡単なエラー記録 | 検索失敗、生成失敗、引用失敗、形式失敗を分けて記録する |
| README | 動かし方を説明できる | 構成図、実行コマンド、入力出力例、指標、今後の計画がある |
この表のポイントは、プロジェクトを「技術デモ」から「説明可能な作品」に引き上げることです。見る人は、当たったかどうかだけでなく、なぜ当たったのか、なぜ外れたのか、どう改善するのかまで確認します。
おすすめのプロジェクト構成
最終成果物は、次のような構成にまとめるとよいです。
rag-domain-assistant/
├── README.md
├── data/
│ ├── raw_docs/
│ ├── chunks.jsonl
│ └── eval_questions.csv
├── src/
│ ├── ingest.py
│ ├── retrieve.py
│ ├── answer.py
│ └── evaluate.py
├── logs/
│ ├── retrieval_logs.jsonl
│ └── failure_cases.md
└── reports/
├── baseline_result.md
└── improvement_record.md
最初からすべてのファイルを埋める必要はありませんが、少なくとも次の 3 本の流れが見えるようにしましょう。資料がどうシステムに入るか、質問がどう文書に命中するか、答えがどう評価されるか、です。
README で最も見せるべきもの
ポートフォリオの README は、「このプロジェクトは RAG と微調整を使っています」と書くだけでは弱いです。大切なのは、全体の流れが見えることです。
| README の項目 | 何に答えるべきか |
|---|---|
| プロジェクト目標 | このシステムはどの分野の問題を解決するのか、なぜ RAG や微調整が必要なのか |
| システム構成 | ユーザーの質問がどう検索、文脈、回答、引用を通るのか |
| 実行方法 | 依存関係の入れ方、データ準備、Q&A 実行、評価の方法 |
| 出力例 | 質問、命中文書、最終回答、出典引用 |
| 評価結果 | baseline の成績、改善後の成績、失敗サンプル |
| 技術的な取捨選択 | なぜ RAG を使うのか、なぜ微調整を検討するのか、両者の境界は何か |
| 今後の計画 | 検索、回答スタイル、コスト、デプロイのうち何を次に改善するのか |
とても小さいですが有効な出力例は、次のように書けます。
質問:返金条件は何ですか?
命中文書:doc1 返金ポリシー score=0.92
回答:返金ポリシーによると、購入後 7 日以内かつ学習進捗が 20% 未満なら返金を申請できます。
出典:doc1
評価:retrieval_hit=true, answer_ok=true, citation_ok=true
最小限の失敗サンプル記録
RAG+微調整プロジェクトで、エンジニアリング力が最もよく出るのは成功例ではなく失敗例です。少なくとも 3 種類は記録するのがおすすめです。
| 失敗タイプ | 現象 | 可能性のある原因 | 次の一手 |
|---|---|---|---|
| 検索失敗 | 正しいポリシーが top-k に入らない | chunk の切り方が悪い、キーワードが合わない、embedding が適切でない | チャンク調整、混合検索、query rewrite |
| 回答失敗 | 資料は取れているが、答えから重要条件が抜ける | prompt の制約が弱い、回答テンプレートが不安定 | 出力形式を強化する、must_contain 検査を増やす |
| 引用失敗 | 答えの結論と引用部分が一致しない | 引用の結合ミス、モデルの自由な創作 | citation check を入れる、文ごとに根拠を求める |
| スタイル失敗 | 事実は合っているが、業務表現に合わない | 微調整データや例が足りない | 形式例や教師ありデータを増やす |
失敗サンプルをきちんと書くと、成功スクリーンショットだけを貼るよりずっと説得力が出ます。
バージョン別の進め方
| バージョン | 目標 | 提出の重点 |
|---|---|---|
| 基礎版 | 最小限の流れを動かす | 入力できる、処理できる、出力できる、例を 1 セット残す |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| 発展版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗サンプル分析、次の改善計画を入れる |
最初は基礎版を完成させることをおすすめします。いきなり大きく全部を作ろうとしないでください。1 段階進めるたびに、「何が増えたか」「どう確認したか」「まだ何が課題か」を README に書くようにしましょう。
練習
- ナレッジベースに新しい文書を 2 つ追加し、検索結果がどう変わるか観察してみましょう。
- 自分なりの「分野別回答スタイル規則」を設計し、微調整層の動きをまねてみましょう。
- 考えてみましょう。もし検索はいつも正しいのに、回答形式だけがいつも乱れるなら、優先して改善すべきなのは RAG でしょうか、それとも微調整でしょうか?
- 自分の言葉で説明してみましょう。「RAG は知識を補い、微調整は振る舞いを補う」と言えるのはなぜでしょうか?