8.5.2 プロジェクト:企業ナレッジベースQ&A
企業ナレッジベースQ&Aがポートフォリオ向けプロジェクトとして適しているのは、名前が立派だからではなく、とても実務に近いからです。
- 文書がある
- 権限がある
- バージョンがある
- 引用元がある
- さらに「答えを間違えると業務に影響する」というプレッシャーがある
だから、この種のプロジェクトで最も大事なのは「答えているように見えること」ではなく、次の点です。
答えが正しい文書に基づいているか、正しい権限範囲内にあるか、そして出典までたどれるか。
学習目標
- 企業文書を検索可能な知識単位に整理する方法を学ぶ
- 権限と引用という2つの企業向け重要制約を設計できるようになる
- 最小限の検索器で、見せられるプロジェクトの全体像を作る方法を学ぶ
- エラー分析と追跡可能性を軸にプロジェクトを見せる方法を学ぶ
初学者向けの用語ブリッジ
企業ナレッジベースのプロジェクトでは、簡単そうに見えてもエンジニアリング上は厳密な意味を持つ言葉があります。
| 用語 | 初学者向けの意味 | このプロジェクトで重要な理由 |
|---|---|---|
permission filtering | 権限フィルタリング。検索や回答の前に、現在のユーザーが見られない文書を除外すること | 社内情報の漏えいを防ぐため |
citation | 回答に付ける出典参照 | ユーザーが答えの根拠を確認できる |
metadata | chunk に付ける追加情報。元ファイル、部署、公開範囲、ページ、バージョンなど | フィルタリング、デバッグ、引用に必要 |
SOP | Standard Operating Procedure。標準作業手順をまとめた内部文書 | 企業の回答は単なる事実ではなく、業務手順であることが多い |
traceability | 回答を元文書や処理経路までたどれること | 流暢に見えるだけでなく、信頼できるプロジェクトにするため |
大事なのは、企業ナレッジベースは検索だけの問題ではないということです。権限、証拠、監査の問題でもあります。
一、なぜ企業ナレッジベースQ&Aは普通のFAQより難しいのか?
文書が長い
企業のナレッジは、数件のQ&Aだけではなく、
たいてい次のような文書から成ります。
- ポリシー文書
- 社内SOP
- 研修マニュアル
- 製品説明
権限が複雑
同じ質問でも、次のように分かれることがあります。
- 外部向け版
- 社内向け版
信頼性の要求が高い
ユーザーはよく次のように確認してきます。
- このルールはどこから来たの?
- どのファイルを引用しているの?
そのため、企業ナレッジベースQ&Aは次の組み合わせに近いです。
- 検索システム
- 引用システム
- 権限システム
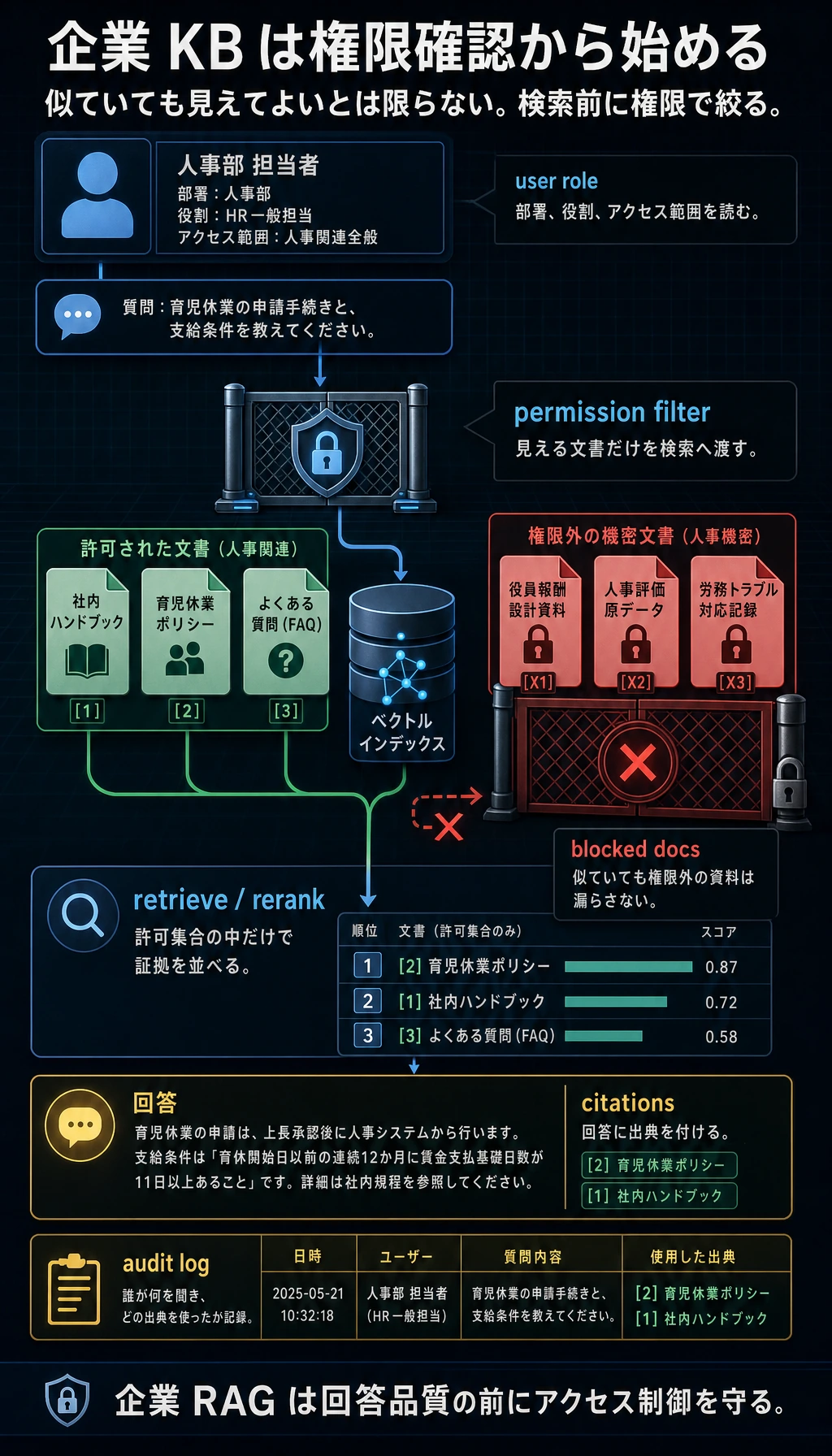
企業ナレッジベースでは、「意味的に近いか」だけを見てはいけません。まずユーザー権限で候補を絞り、その後に検索と再ランキングを行い、最後の回答には必ず出典を付けます。そうしないと、見た目はそれらしく答えても、社内文書を漏らしたり、あとから追跡できなかったりします。
二、まずはプロジェクトの範囲をはっきり決める
ポートフォリオとして見せやすい最小範囲は、たとえば次のようなものです。
コースプラットフォームの社内ヘルプセンター向けに、「返金 / 請求書 / 修了証 / 社内カスタマーサポートSOP」のナレッジベースQ&Aシステムを作る。
少なくとも次の4種類の質問に答えられるようにします。
- 外部ルールに関する質問
- 社内フローに関する質問
- 権限の違いによって答えが変わる質問
- 出典を示す必要がある質問
なぜこの範囲がよいのか?
- 文書のテーマがまとまっている
- 権限の境界が現実的
- 結果の良し悪しを説明しやすい
モデルを書く前に、まず知識単位を設計する
次の例では3つのことを行います。
- 文書を最小の知識単位に分ける
- 各段落にメタデータを付ける
- 外部公開と社内限定の可視範囲を分ける
kb = [
{
"id": "doc_001",
"section": "返金ポリシー",
"department": "support",
"visibility": "public",
"text": "コース購入後7日以内かつ学習進捗が20%未満の場合、返金を申請できます。",
"keywords": {"返金", "7日", "進捗", "20%"},
},
{
"id": "doc_002",
"section": "修了証の説明",
"department": "teaching",
"visibility": "public",
"text": "すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます。",
"keywords": {"修了証", "修了テスト", "項目"},
},
{
"id": "doc_003",
"section": "社内カスタマーサポートSOP",
"department": "internal",
"visibility": "internal",
"text": "サポートが返金申請を処理するときは、注文番号、学習進捗、支払いチャネルを先に確認する必要があります。",
"keywords": {"返金", "サポート", "SOP", "確認", "フロー"},
},
]
for item in kb:
print(f"{item['id']} | {item['visibility']} | {item['section']}")
期待される出力:
doc_001 | public | 返金ポリシー
doc_002 | public | 修了証の説明
doc_003 | internal | 社内カスタマーサポートSOP
なぜここでこんなにメタデータを付けるのか?
企業ナレッジベースの検索では、「内容が似ているか」だけでは足りません。
さらに次の点を判断する必要があります。
- 今のユーザーに見せてよいか
- どの業務領域に属するか
- 回答時に出典をどう表示するか
これが、企業プロジェクトと普通のQ&Aデモの根本的な違いです。
まずは説明しやすい検索器を作る
この例を現在の環境でそのまま動かせるように、外部の embedding ライブラリは使わず、
純粋な Python のキーワード重複検索器で、まずはプロジェクトの骨組みを作ります。
def retrieve(query, allowed_visibility, top_k=2):
candidates = []
query_text = query.lower()
for item in kb:
if item["visibility"] not in allowed_visibility:
continue
score = sum(keyword.lower() in query_text for keyword in item["keywords"])
candidates.append((score, item))
candidates.sort(key=lambda x: x[0], reverse=True)
return [item for score, item in candidates[:top_k] if score > 0]
print("public user:")
for hit in retrieve("返金ルールは何ですか?", allowed_visibility={"public"}):
print(hit["id"], hit["visibility"], hit["section"])
print("\ninternal support:")
for hit in retrieve("サポートの確認フローは何ですか?", allowed_visibility={"public", "internal"}):
print(hit["id"], hit["visibility"], hit["section"])
期待される出力:
public user:
doc_001 public 返金ポリシー
internal support:
doc_003 internal 社内カスタマーサポートSOP
この検索器は単純でも、なぜ学習に向いているのか?
次の3点がはっきり見えるからです。
- 検索語が再現率にどう影響するか
- 権限が候補集合にどう影響するか
- 結果がなぜ変わるのか
なぜここであえて最初から embedding を使わないのか?
この節ではまず次の点をはっきりさせたいからです。
- 権限
- 出典
- 構造化された知識単位
こうした企業向けの重要ポイントを先に理解しておくと、そのあとでより強い検索方法に置き換えるときも安定します。
「回答 + 出典」をまとめて返す
def answer_with_sources(query, allowed_visibility):
hits = retrieve(query, allowed_visibility=allowed_visibility, top_k=2)
if not hits:
return {
"answer": "現在の権限範囲内では、十分に関連する情報が見つかりませんでした。",
"sources": [],
}
top = hits[0]
return {
"answer": top["text"],
"sources": [
{
"id": top["id"],
"section": top["section"],
"department": top["department"],
"visibility": top["visibility"],
}
],
}
print(answer_with_sources("返金ルールは何ですか?", {"public"}))
print(answer_with_sources("サポートの確認フローは何ですか?", {"public", "internal"}))
期待される出力:
{'answer': 'コース購入後7日以内かつ学習進捗が20%未満の場合、返金を申請できます。', 'sources': [{'id': 'doc_001', 'section': '返金ポリシー', 'department': 'support', 'visibility': 'public'}]}
{'answer': 'サポートが返金申請を処理するときは、注文番号、学習進捗、支払いチャネルを先に確認する必要があります。', 'sources': [{'id': 'doc_003', 'section': '社内カスタマーサポートSOP', 'department': 'internal', 'visibility': 'internal'}]}
なぜ「出典を返すこと」が作品レベルの強みなのか?
それによって、システムは単に「答えを返す」だけではなく、
次のことも説明できるようになるからです。
- この答えはどこから来たのか
- なぜ信頼できるのか
これはプロジェクトの信頼性を大きく高めます。
なぜ企業シーンでは普通のQ&Aより出典が必要なのか?
企業ユーザーは、答えをそのまま実際の業務フローに使うことが多いからです。
出典がないと、信頼を作るのが難しくなります。
このプロジェクトはどう評価すべきか?
「答えられたか」だけを見ない
企業ナレッジベースのプロジェクトは、少なくとも次の3層で評価するべきです。
- 関連する情報を拾えているか
- 権限が正しいか
- 引用が追跡可能か
きわめて簡単な評価セット
eval_cases = [
{
"query": "返金ルールは何ですか?",
"visibility": {"public"},
"expected_doc": "doc_001",
},
{
"query": "サポートの確認フローは何ですか?",
"visibility": {"public"},
"expected_doc": None,
},
{
"query": "サポートの確認フローは何ですか?",
"visibility": {"public", "internal"},
"expected_doc": "doc_003",
},
]
for case in eval_cases:
result = answer_with_sources(case["query"], case["visibility"])
got = result["sources"][0]["id"] if result["sources"] else None
print({
"query": case["query"],
"expected_doc": case["expected_doc"],
"got": got,
"match": got == case["expected_doc"],
})
期待される出力:
{'query': '返金ルールは何ですか?', 'expected_doc': 'doc_001', 'got': 'doc_001', 'match': True}
{'query': 'サポートの確認フローは何ですか?', 'expected_doc': None, 'got': None, 'match': True}
{'query': 'サポートの確認フローは何ですか?', 'expected_doc': 'doc_003', 'got': 'doc_003', 'match': True}
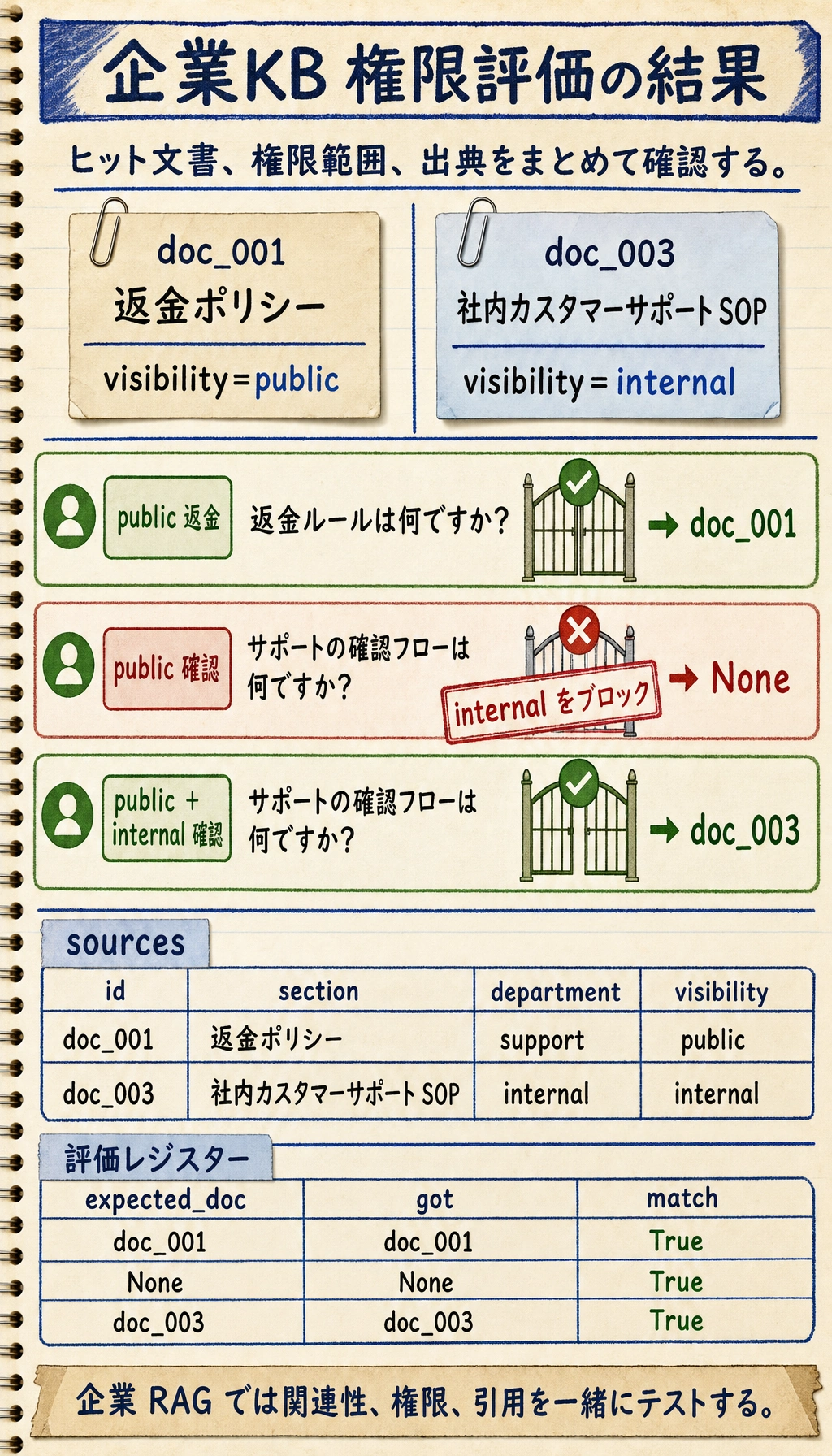
2行目を権限テストとして見てください。同じ確認フローの質問でも、public だけのユーザーは internal SOP を見られないため None になるべきです。3行目は internal を許可したときだけ doc_003 にヒットします。
なぜこの評価が価値が高いのか?
企業ナレッジベースで最も重要な2つのリスクを、そのままカバーできるからです。
- 答えるべきなのに、正しく答えられない
- 見せるべきでない社内文書を見せてしまう
七、このプロジェクトを作品レベルにもう一段上げるには?
ルールベース検索をベクトル検索にアップグレードする
文書の chunking と rerank を追加する
出典表示をUIとして見せる
見せる内容として特におすすめなのは次の4つです。
- ユーザーの質問
- ヒットした文書
- 最終回答
- 出典引用
「権限のために失敗した例」をいくつか見せる
これは非常に説得力があります。
八、最もハマりやすい落とし穴
「答えられる」だけで、「追跡できる」設計にしない
意味的な関連だけを見て、権限の境界を見ない
文書単位の切り方が粗すぎる
粗すぎると、答えも出典も曖昧になりやすくなります。
まとめ
この節で最も大事なのは、作品レベルの見方を持つことです。
企業ナレッジベースQ&Aが本当にプロジェクトらしく見えるのは、検索器をつないだからではなく、知識単位、権限の境界、回答生成、出典追跡をひとつの信頼できる閉ループとしてまとめられることです。
この閉ループがはっきりしていれば、このプロジェクトは実際の企業シーンにかなり近いシステムになります。
バージョン進化のおすすめ
| バージョン | 目的 | 重点成果物 |
|---|---|---|
| 基礎版 | 最小の閉ループを動かす | 入力できる、処理できる、出力できる、そして一組の例を保持する |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| 挑戦版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗例の分析、次のステップの道筋を追加する |
最初は基礎版を完成させるのがおすすめです。最初から大きく全部を作ろうとしないでください。バージョンを1つ上げるごとに、「何が追加されたか」「どう検証したか」「まだ何が課題か」を README に書きましょう。
練習
kbにさらに2件の「公開文書」と1件の「社内文書」を追加して、検索の競争がより現実的になるようにしてみましょう。- 企業ナレッジベースプロジェクトでは、なぜ「権限が正しいこと」が「答えがきれいなこと」より重要な場合があるのでしょうか?
- 文書の chunk が粗すぎると、回答と引用にどのような影響が出るか考えてみましょう。
- このプロジェクトをポートフォリオとしてまとめるなら、トップページで最も見せる価値がある情報は何でしょうか?