7 大モデル原理、Prompt と微調整
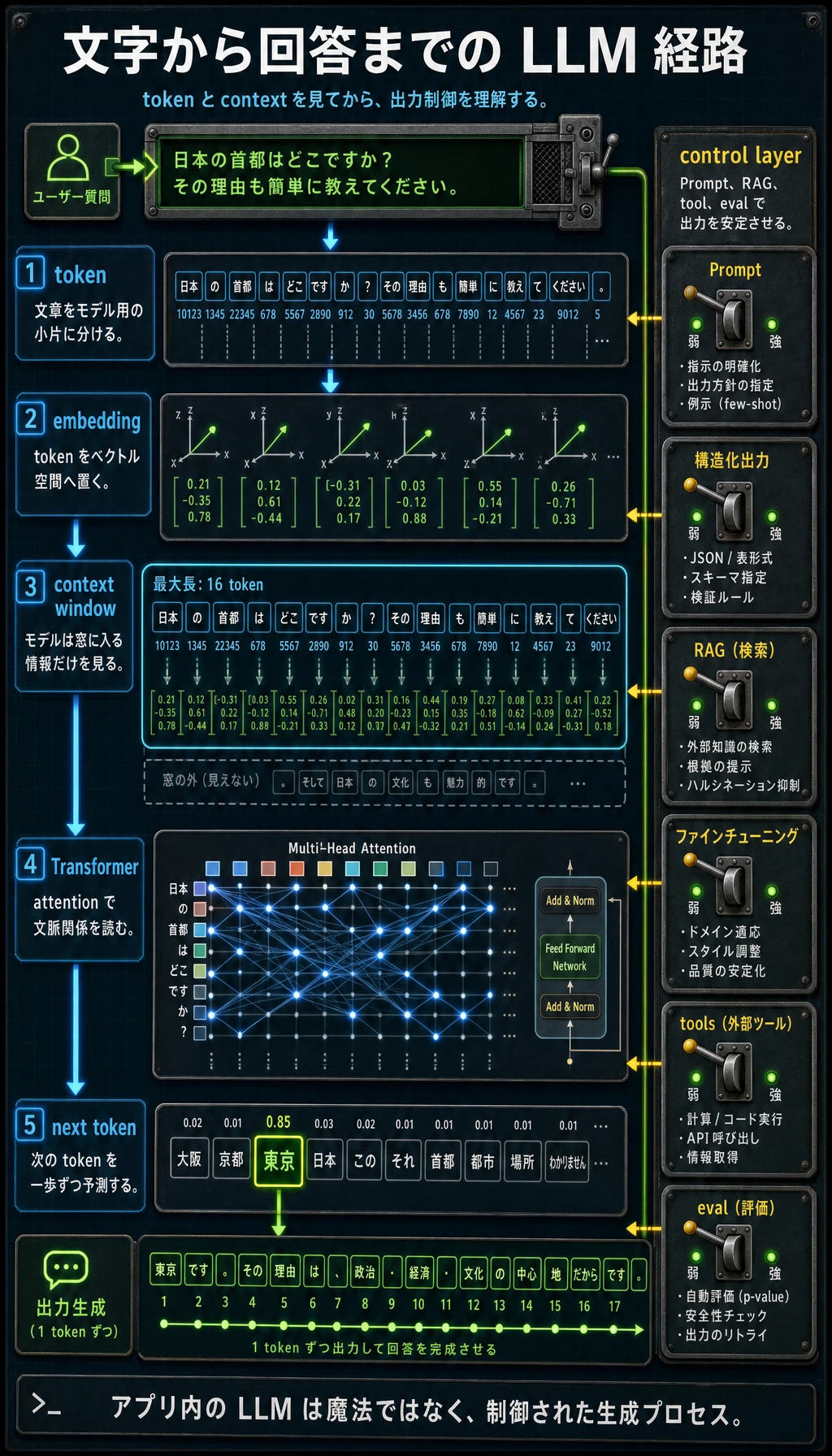
この章で答える実践的な問いは1つです。ユーザーが LLM に文章を送ったあと、その文章はどんな流れを通り、どうすればアプリに入れられるほど安定した出力にできるのか。
モデル名を暗記するところから始めなくて大丈夫です。まず操作できるループを押さえます。文章は token になり、token はベクトルになり、Transformer が文脈から次の token を予測し、その結果を Prompt、構造化出力、RAG、微調整、ツールで制御します。
まず全体の流れを見る

この図を、この章全体の地図として使ってください。
| 用語 | やさしい意味 | 実践で確認すること |
|---|---|---|
| Token | 入力文を小さく分けた単位 | Prompt がコンテキストウィンドウに収まるか? |
| Embedding | token や文章片を表すベクトル | 近い意味が比較や検索に使えるほど近いか? |
| Transformer | attention で文脈を混ぜるモデル構造 | どの前の語、例、ルールが回答に効いたか? |
| 事前学習 | 大量データから汎用的な言語パターンを学ぶこと | タスク前にモデルがすでに持つ能力は何か? |
| Prompt | 今モデルに送る指示と文脈 | より明確な指示だけで解けないか? |
| 微調整 | 学習例でモデルの長期的な振る舞いを変えること | 知識不足ではなく、繰り返す振る舞いの問題か? |
| 整合 | 出力をより安全に、人の意図へ近づけること | 流暢でも、どこで失敗し得るか? |
学習順序とタスク表
フルワークショップは最後に置きます。まず心の中の地図を作り、そのあと実験を一通り動かします。
| 手順 | 読む内容 | 手を動かすこと | 残す証拠 |
|---|---|---|---|
| 7.1 | NLP 速習 | tokenizer と embedding の例を動かす | token、ベクトル、文脈を説明するメモ |
| 7.2 | LLM 概観と発展史 | 規模、データ、指示チューニング、整合が挙動を変えた場所を印づける | タイムラインまたは能力マップ |
| 7.3-7.4 | Transformer と事前学習 | 暗記ではなく直感をつかむ | attention、文脈、学習目標を説明する図 |
| 7.5 | Prompt エンジニアリング | 固定入力で複数の Prompt 版を比べる | Prompt 版、出力、スコア、失敗例 |
| 7.6 | 微調整 | Prompt、RAG、微調整のどれを使うか判断する | 短い判断表 |
| 7.7 | 整合 | 失敗パターンと安全境界を確認する | 安全・評価チェックリスト |
| 7.8 | ステージプロジェクト | 7.8.4 実践:第 7 章フルワークショップ を動かす | ターミナル出力、合格率、README メモ |
最初に動かすループ:API なしで Prompt を試す
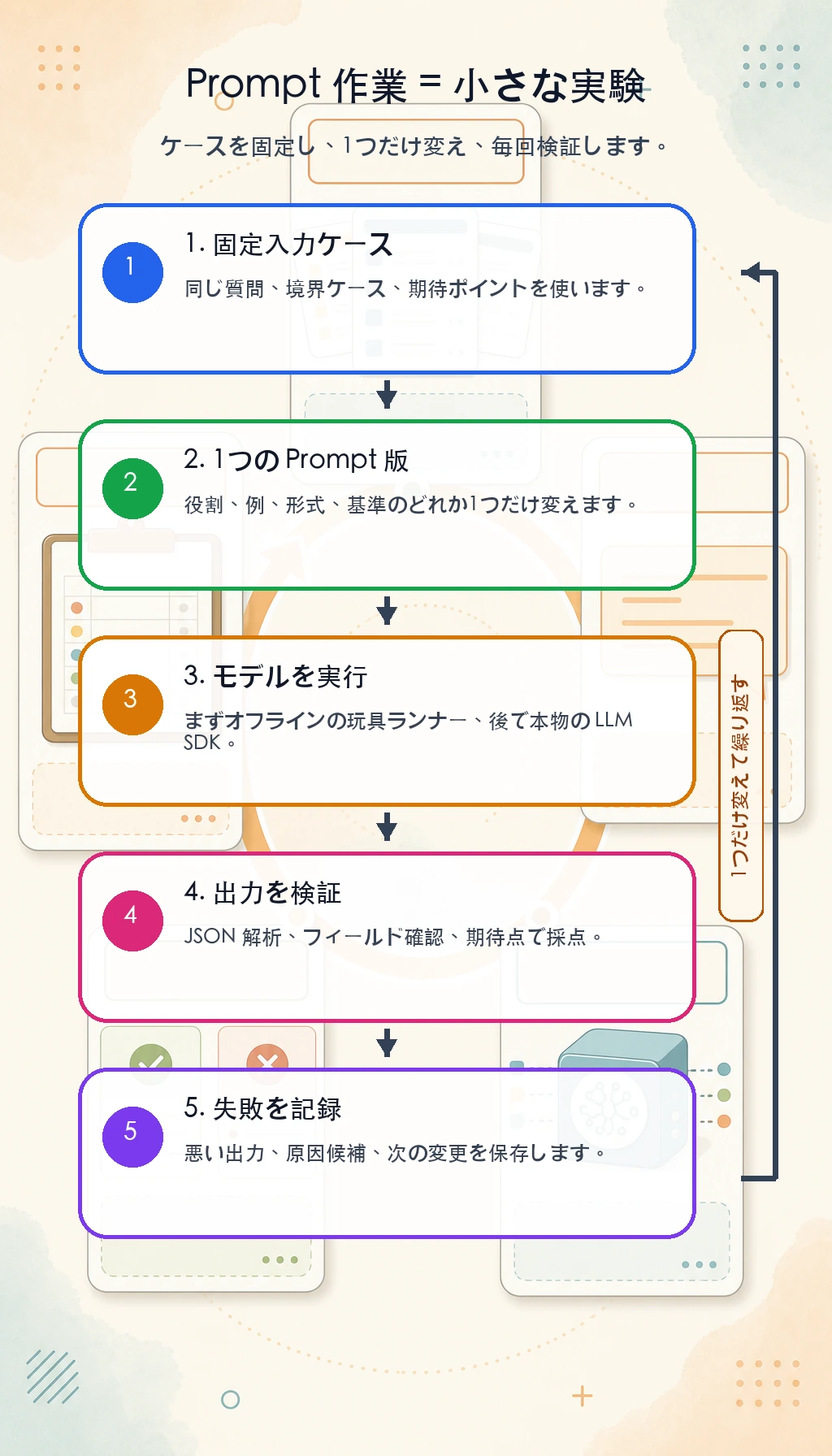
Prompt の作業はソフトウェアテストに近いです。入力ケースを固定し、毎回1つの Prompt 変数だけを変え、出力を検証し、失敗例を保存します。
ch07_prompt_test.py を作成し、Python 3.10 以降で実行してください。このオフライン例は本物のモデルを呼びません。評価ループを練習するためのものです。あとで本物の LLM SDK に接続するときは、toy_model() だけを置き換えます。
import json
cases = [
{"topic": "gradient descent", "level": "beginner"},
{"topic": "RAG", "level": "intermediate"},
]
prompts = {
"plain": "Explain the topic.",
"teacher": "You are a patient AI teacher. Explain the topic in 3 short bullets.",
"json": "Return JSON with keys: topic, level, summary, next_step.",
}
def toy_model(prompt: str, case: dict) -> str:
topic = case["topic"]
level = case["level"]
if "Return JSON" in prompt:
return json.dumps(
{
"topic": topic,
"level": level,
"summary": f"{topic} explained for {level} learners",
"next_step": "Run one small example and record the result",
},
ensure_ascii=False,
)
if "patient AI teacher" in prompt:
return f"- Define {topic}\n- Show one example\n- Ask the learner to retry"
return f"{topic} is an AI concept."
def validate_json(raw: str) -> bool:
try:
data = json.loads(raw)
except json.JSONDecodeError:
return False
return {"topic", "level", "summary", "next_step"} <= data.keys()
for prompt_name, prompt in prompts.items():
passed = 0
for case in cases:
output = toy_model(prompt, case)
ok = validate_json(output) if prompt_name == "json" else bool(output.strip())
passed += int(ok)
print(f"{prompt_name}: {passed}/{len(cases)} cases passed")
期待される出力:
plain: 2/2 cases passed
teacher: 2/2 cases passed
json: 2/2 cases passed
操作メモ: 悪いケース、長いケース、新しい出力フィールドを1つずつ追加してください。スコアが変わったら、どの Prompt 変更が原因だったかを記録します。この習慣は、1回だけ見栄えのよい回答を得ることより重要です。
Prompt、RAG、微調整、ツールの選び方
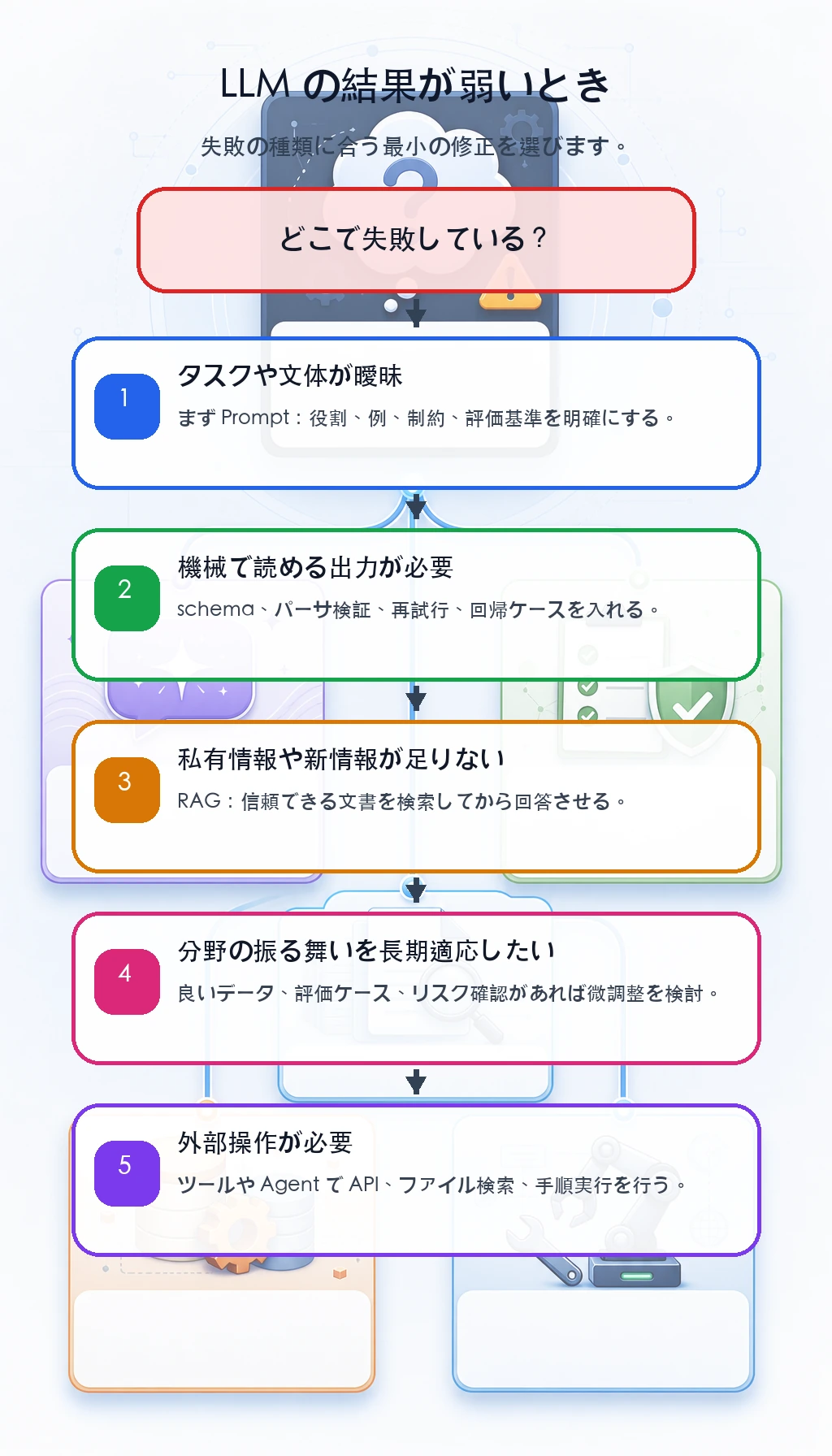
LLM の結果が弱いとき、すぐ微調整へ進まないでください。
| 症状 | まず試すこと | 次の手段へ進む目安 |
|---|---|---|
| 回答の書き方が曖昧 | Prompt を直し、例を追加する | 明確な指示でも固定ケースが失敗する |
| アプリが JSON や表を必要とする | schema とパーサ検証を追加する | フィールド漏れや型違いが繰り返される |
| 私有情報や新しい情報が足りない | 文書を検索する RAG を使う | 検索は正確なのに振る舞いが間違う |
| 分野特有の振る舞いを長期的に守らせたい | 微調整や LoRA を検討する | 高品質な例と評価ケースが十分ある |
| 外部の操作が必要 | ツールまたは Agent ワークフローを使う | API 呼び出し、ファイル検索、手順実行が必要 |
よくある失敗
- LLM をデータベースのように扱う: 流暢な文章は正しさの証明ではありません。
- Prompt、入力ケース、モデルを同時に変える: 何が改善に効いたのか分からなくなります。
- 構造化出力を求めても検証しない: JSON らしく見える文章でも無効なことがあります。
- 早すぎる微調整: 多くの問題は Prompt、RAG、ツール、プロダクトロジックから始めるべきです。
- 出力ループを見る前に Transformer 細部へ入りすぎる: 理論を実践に結びつけにくくなります。
クリア確認
第 8 章へ進む前に、次をできるようにしてください。
- token、embedding、attention、コンテキストウィンドウ、事前学習、Prompt、微調整、整合を自分の言葉で説明できる。
- 上の Prompt テストループを動かし、毎回1つの変数だけを変えられる。
- Prompt 版、固定入力ケース、出力、スコア、失敗例を保存できる。
- タスクを Prompt、構造化出力、RAG、微調整、ツール、Agent のどれから始めるべきか判断できる。
- フルワークショップを動かし、短い README に結果を記録できる。
印刷用チェックリストは 7.0 学習チェックリスト を使ってください。プロジェクトから始めたい場合は 7.8.4 実践:第 7 章フルワークショップ へ進みます。