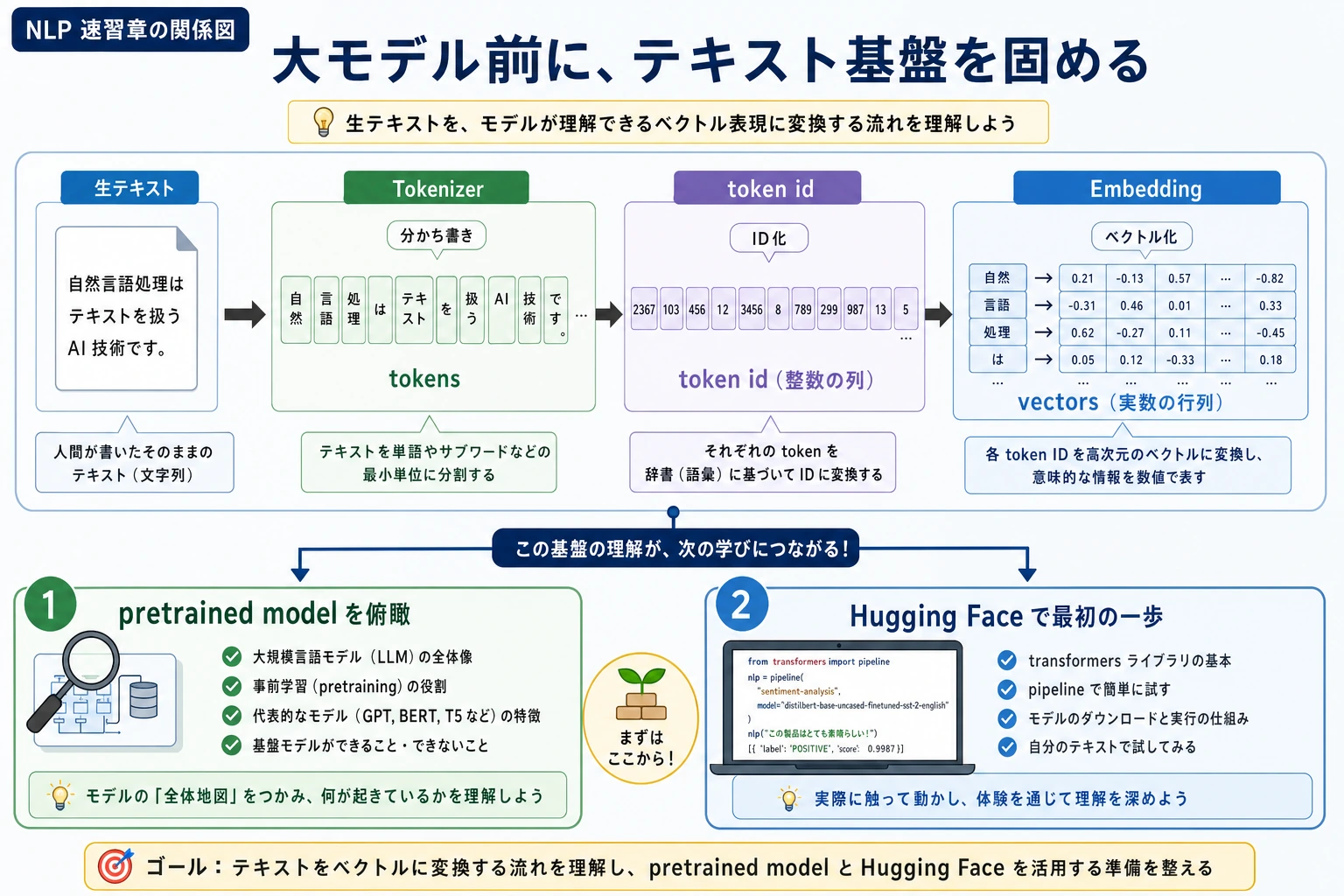
7.1.1 NLP 速習ロードマップ:テキストから token、ベクトルへ
LLM を理解しやすくするには、まずテキストがモデルの処理できる形へ変わる流れを見ます。text -> tokens -> IDs -> vectors -> model output です。
まず流れを見る
| 用語 | 最初の意味 |
|---|---|
| token | モデルが使うテキストの一部 |
| tokenizer | テキストを分け、ID に対応させる道具 |
| embedding | token やテキストの密なベクトル |
| pretrained model | 広いテキストで先に学習されたモデル |
| Hugging Face | モデル、データセット、ツールのエコシステム |
小さな token ラボを動かす
text = "RAG retrieves evidence before answering"
tokens = text.lower().split()
vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}
ids = [vocab[token] for token in tokens]
print("tokens:", tokens)
print("ids:", ids)
print("unique_tokens:", len(vocab))
出力:
tokens: ['rag', 'retrieves', 'evidence', 'before', 'answering']
ids: [3, 4, 2, 1, 0]
unique_tokens: 5
本物の tokenizer はもっと賢いですが、主な考え方は同じです。テキストは安定した部品と ID になってから、ベクトルやモデルへ進みます。
この順番で学ぶ
| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 7.1.2 Tokenizer | text -> tokens -> IDs |
| 2 | 7.1.3 Embeddings | token/text -> vectors |
| 3 | 7.1.4 事前学習済みモデル | モデル能力をロードして再利用する |
| 4 | 7.1.5 Hugging Face クイックスタート | pipeline、model card、ローカル実行 |
| 5 | 7.1.6 Tokenizer と Embedding ラボ | token とベクトルを確認する |
合格ライン
生テキストに tokenization が必要な理由、embedding がベクトルである理由、事前学習済みモデルをゼロからではなく再利用する理由を説明できれば合格です。