7.1.1 NLP 速成路线图:文本到 token 到向量
想理解 LLM,先看文本如何变成模型能处理的形式:文本 -> token -> ID -> 向量 -> 模型输出。
先看流程
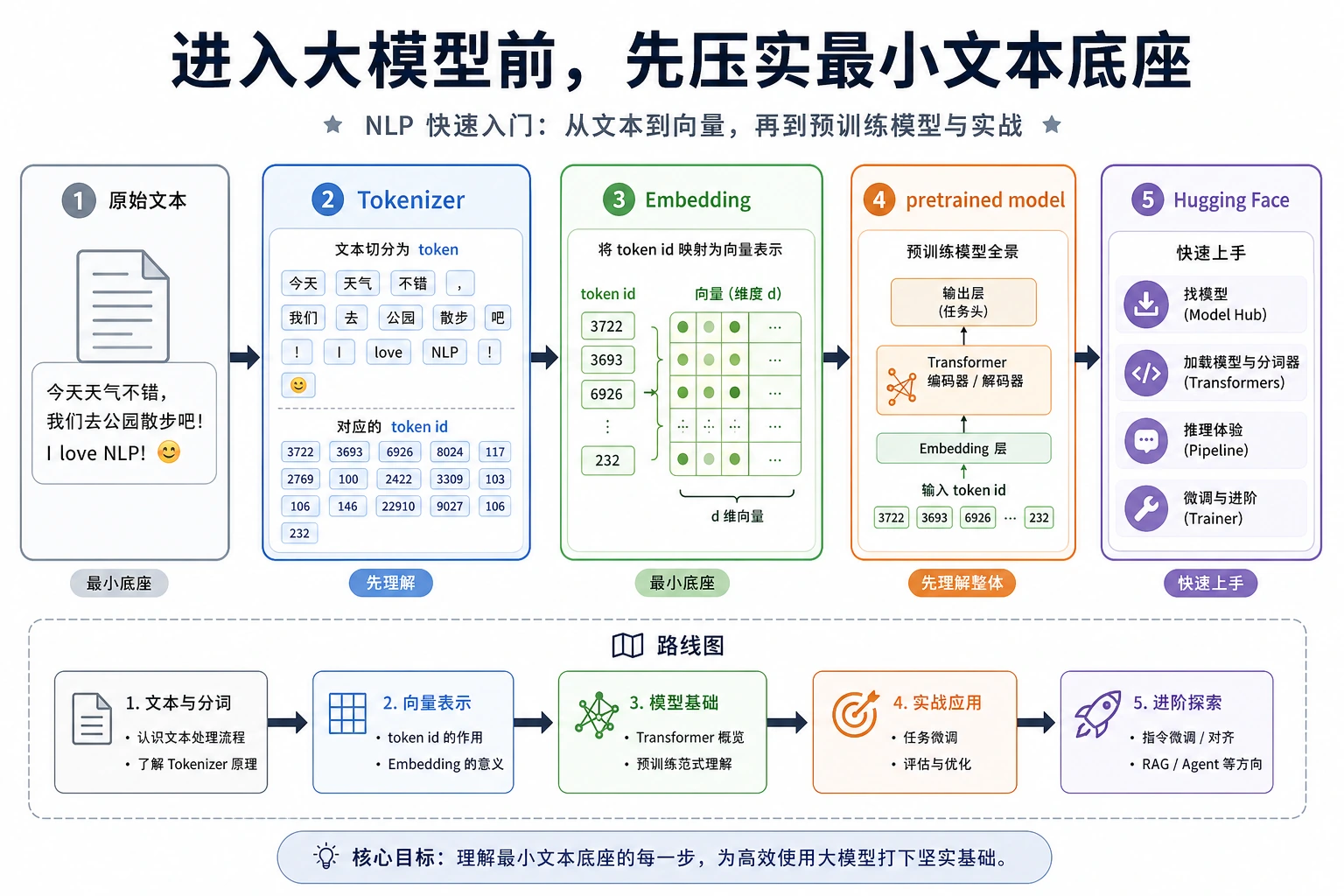
| 词 | 第一层意思 |
|---|---|
| token | 模型使用的一小段文本 |
| tokenizer | 切分文本并映射成 ID 的工具 |
| embedding | token 或文本的稠密向量 |
| pretrained model | 已经在大规模文本上训练过的模型 |
| Hugging Face | 模型、数据集、工具生态 |
跑一个极小 token 实验
text = "RAG retrieves evidence before answering"
tokens = text.lower().split()
vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}
ids = [vocab[token] for token in tokens]
print("tokens:", tokens)
print("ids:", ids)
print("unique_tokens:", len(vocab))
预期输出:
tokens: ['rag', 'retrieves', 'evidence', 'before', 'answering']
ids: [3, 4, 2, 1, 0]
unique_tokens: 5
真实 tokenizer 更复杂,但主线一样:文本必须先变成稳定的片段和 ID,后面才能进入向量和模型。
按这个顺序学
| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 7.1.2 Tokenizer | 文本 -> token -> ID |
| 2 | 7.1.3 Embeddings | token/文本 -> 向量 |
| 3 | 7.1.4 预训练模型 | 加载并复用模型能力 |
| 4 | 7.1.5 Hugging Face 快速上手 | pipeline、model card、本地运行 |
| 5 | 7.1.6 Tokenizer 与 Embedding 实验 | 检查 token 和向量 |
通过标准
能解释为什么原始文本需要分词、为什么 embedding 是向量、为什么预训练模型通常复用而不是从零训练,就算通过。