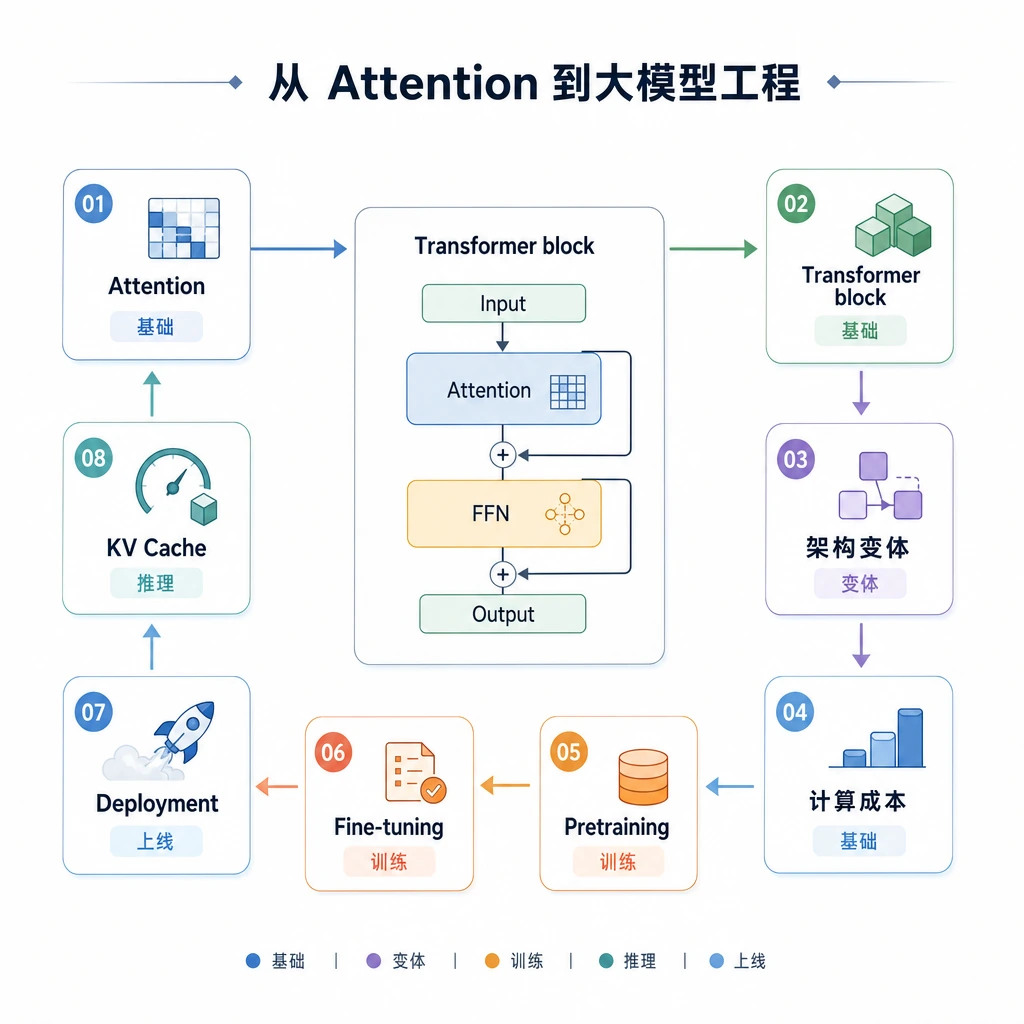
7.3.1 Transformer 深入路线图:Block、Mask、成本
本小章往 Transformer 内部看一层,帮助你调试 LLM 行为,并理解上下文长度、attention、KV cache 和模型变体为什么重要。
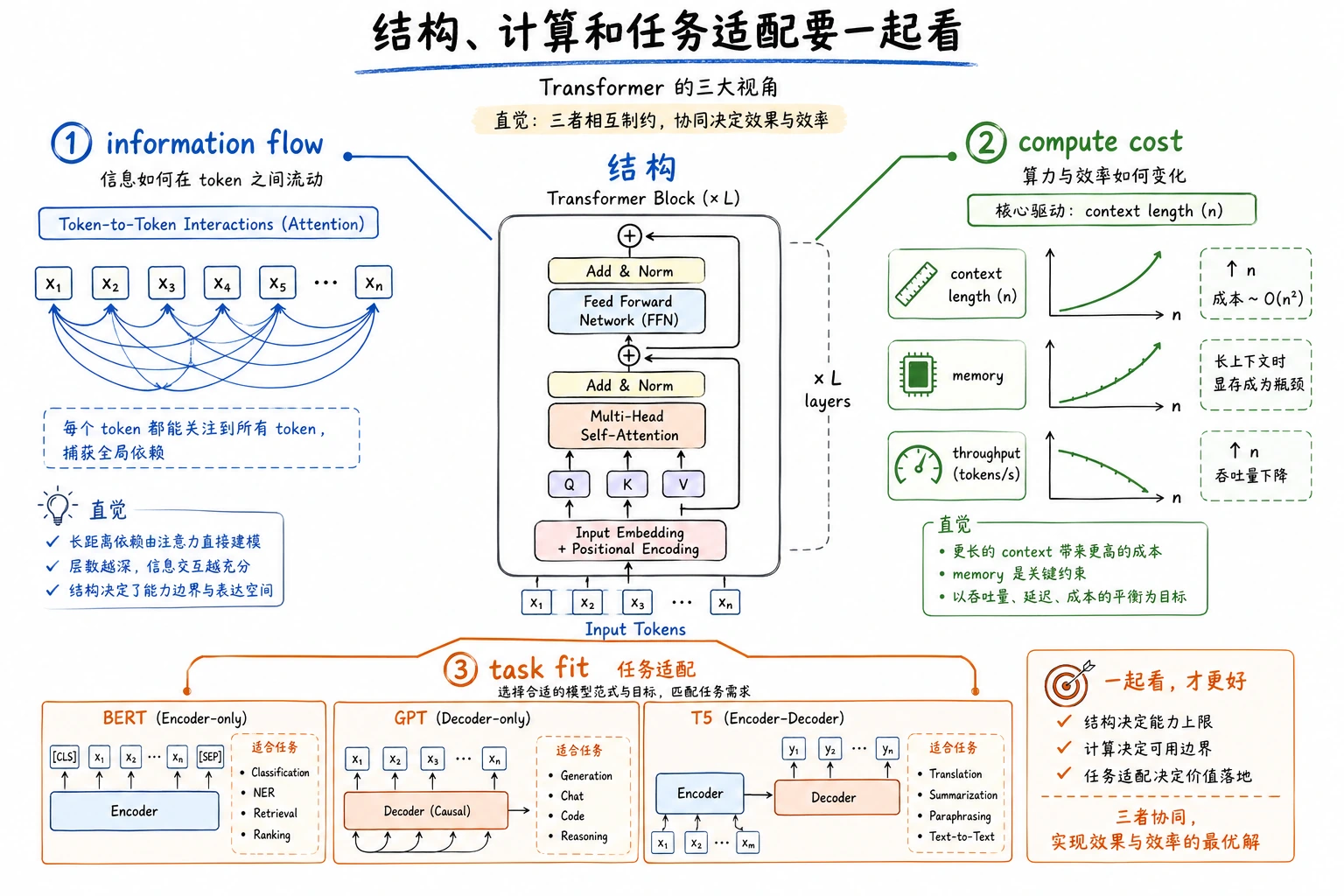
先看内部流
构造 causal mask
seq_len = 4
mask = []
for query_pos in range(seq_len):
row = []
for key_pos in range(seq_len):
row.append("allow" if key_pos <= query_pos else "block")
mask.append(row)
for row in mask:
print(row)
预期输出:
['allow', 'block', 'block', 'block']
['allow', 'allow', 'block', 'block']
['allow', 'allow', 'allow', 'block']
['allow', 'allow', 'allow', 'allow']
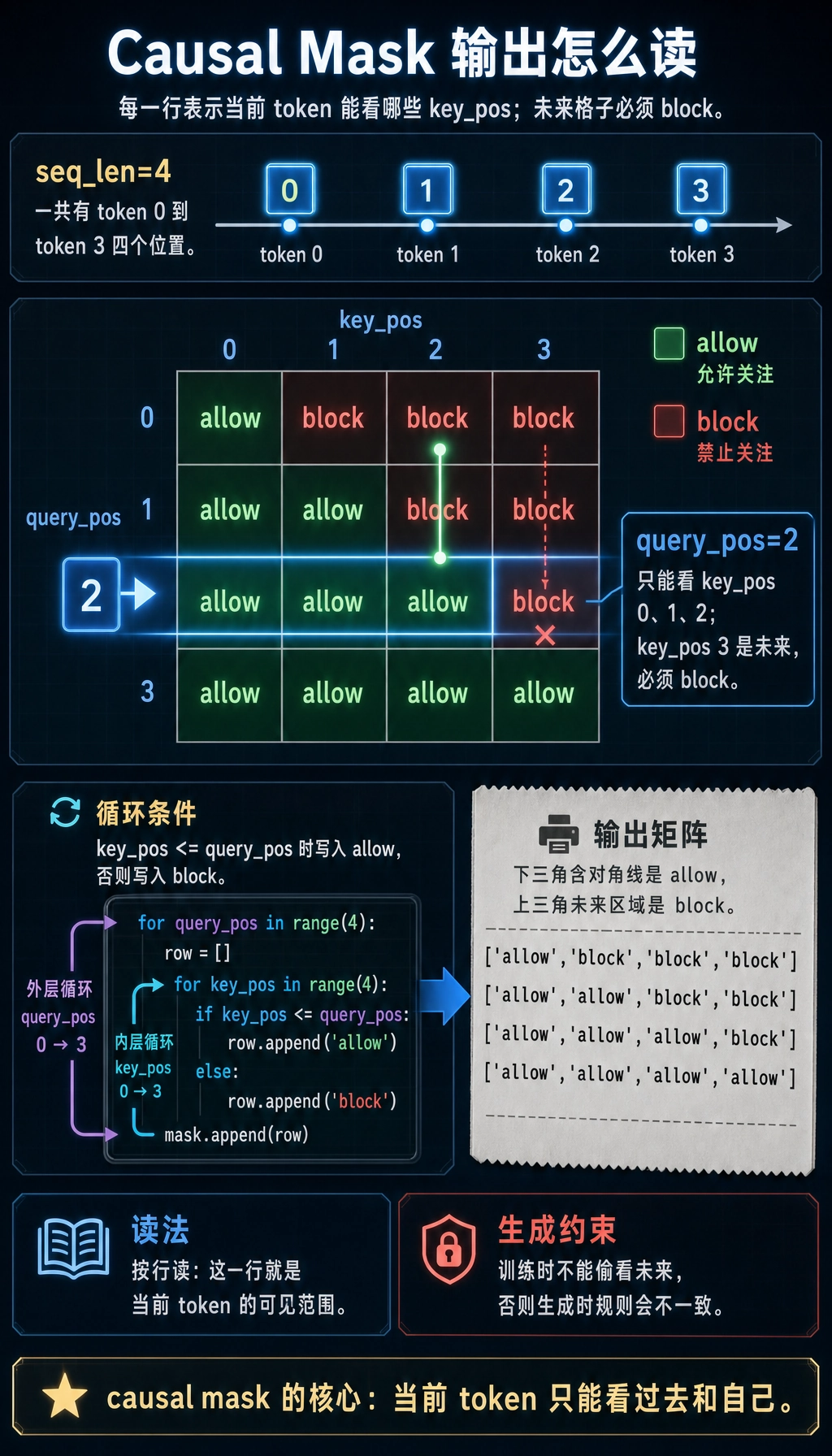
生成任务使用这种“不看未来”的规则:一个 token 可以看前面的 token,但不能看未来 token。
按这个顺序学
| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 7.3.2 架构回顾 | attention、残差、归一化 |
| 2 | 7.3.3 现代 Decoder Block | decoder-only LLM block |
| 3 | 7.3.4 模型变体 | encoder、decoder、encoder-decoder |
| 4 | 7.3.5 高效 Attention | KV cache、MQA/GQA、长上下文 |
| 5 | 7.3.6 规模与计算 | 成本、延迟、显存 |
通过标准
能解释 decoder-only 模型为什么需要 causal mask、为什么上下文变长会让 attention 变贵,以及 KV cache 为什么能帮助生成,就算通过。