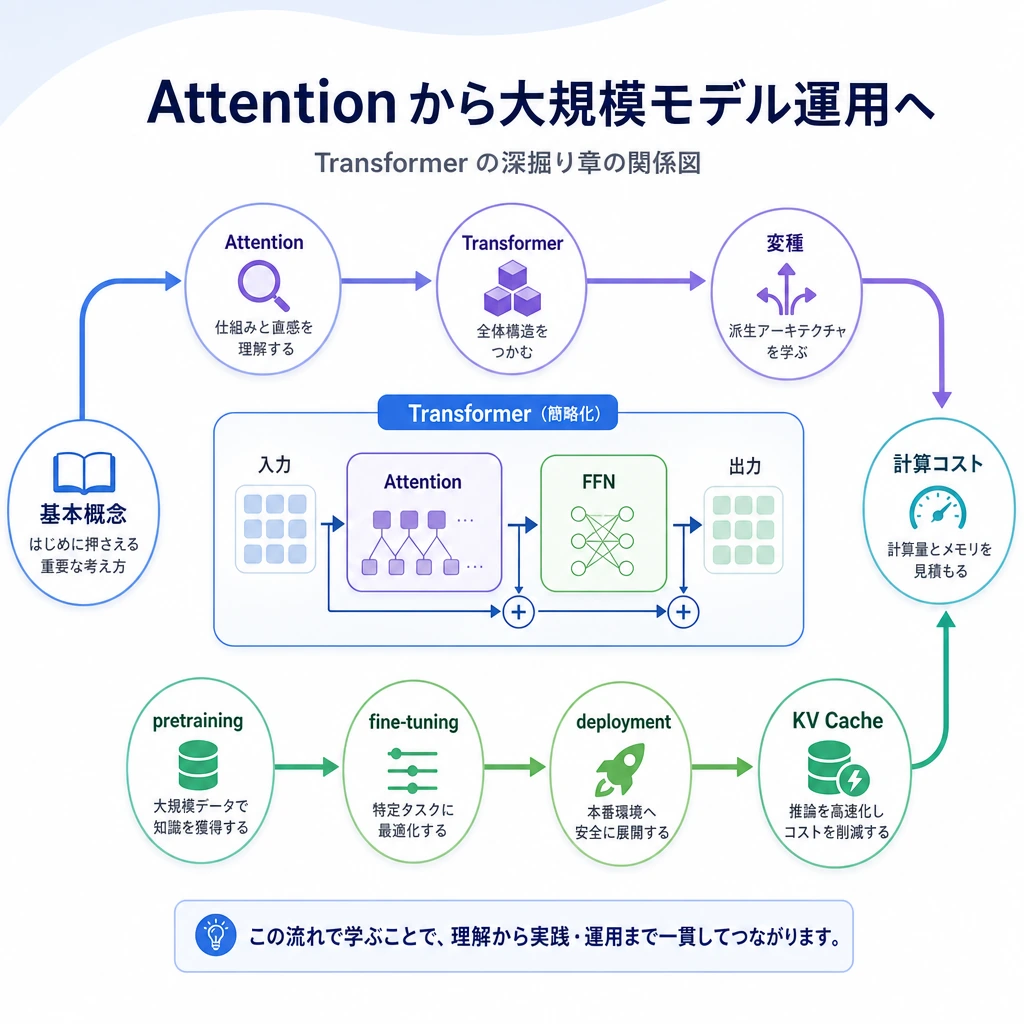
7.3.1 Transformer 深掘りロードマップ:Block、Mask、コスト
この章では Transformer の内部を少し深く見ます。LLM の挙動をデバッグし、context length、attention、KV cache、モデル変種がなぜ重要かを理解します。
まず内部フローを見る
causal mask を作る
seq_len = 4
mask = []
for query_pos in range(seq_len):
row = []
for key_pos in range(seq_len):
row.append("allow" if key_pos <= query_pos else "block")
mask.append(row)
for row in mask:
print(row)
出力:
['allow', 'block', 'block', 'block']
['allow', 'allow', 'block', 'block']
['allow', 'allow', 'allow', 'block']
['allow', 'allow', 'allow', 'allow']
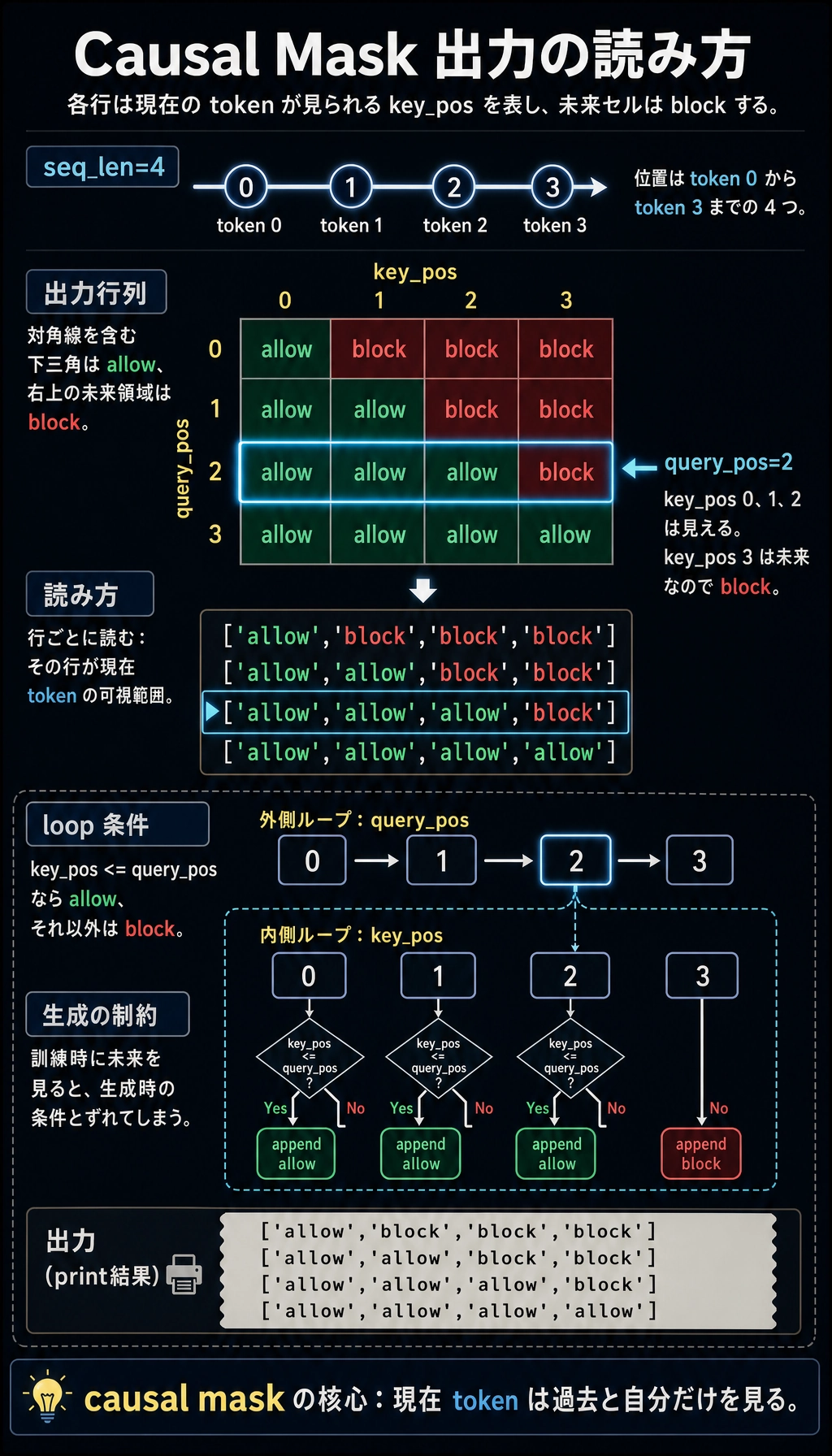
生成ではこの「未来を見ない」ルールを使います。token は前の token を見られますが、未来 token は見られません。
この順番で学ぶ
| 順番 | 読む | まず見ること |
|---|---|---|
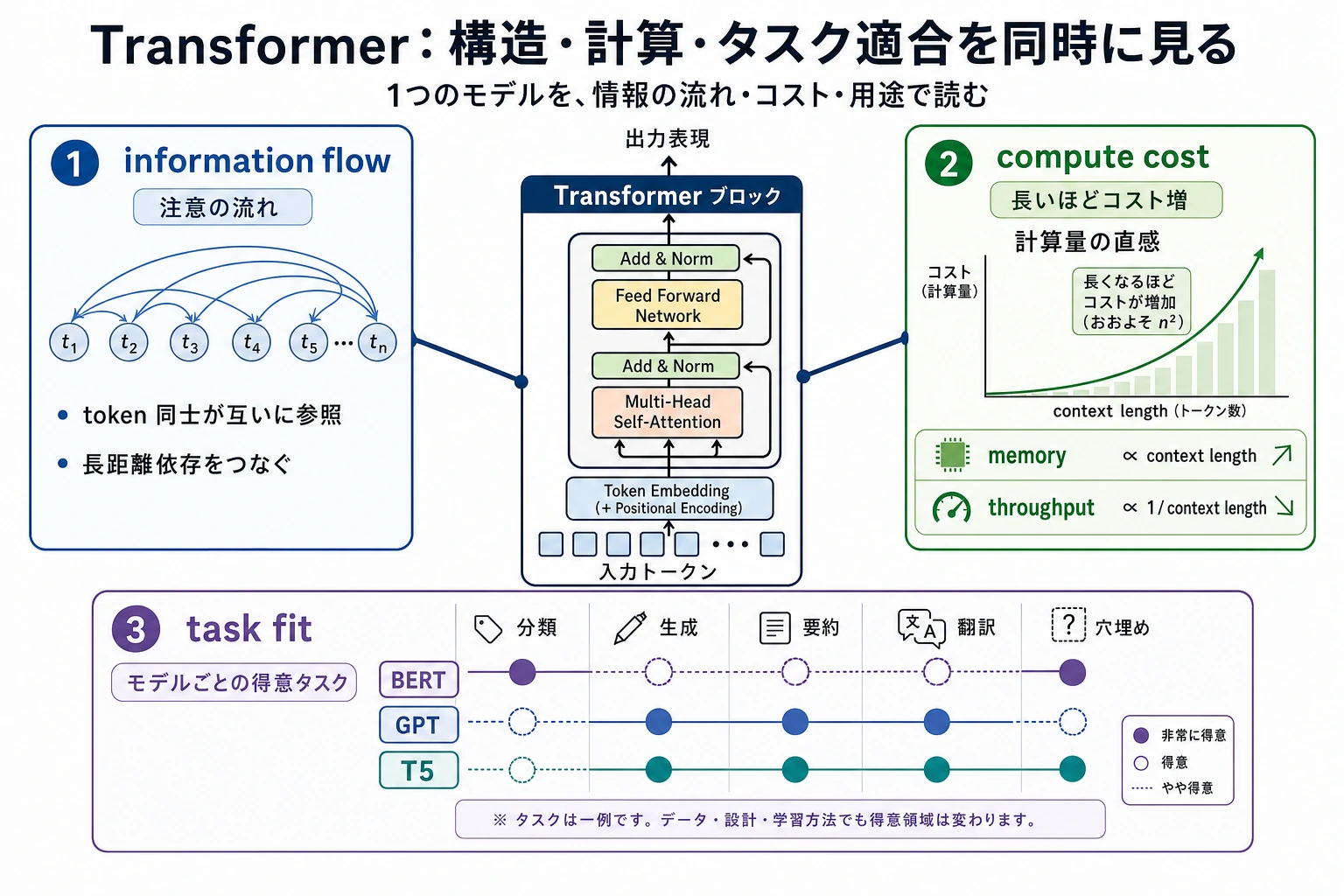
| 1 | 7.3.2 アーキテクチャ復習 | attention、残差、正規化 |
| 2 | 7.3.3 現代 Decoder Block | decoder-only LLM block |
| 3 | 7.3.4 モデル変種 | encoder、decoder、encoder-decoder |
| 4 | 7.3.5 効率的 Attention | KV cache、MQA/GQA、長い context |
| 5 | 7.3.6 スケールと計算 | コスト、遅延、メモリ |
合格ライン
decoder-only モデルになぜ causal mask が必要か、context が長くなるほど attention が高価になる理由、KV cache が生成を助ける理由を説明できれば合格です。