7.3.3 元の Transformer vs 現代 LLM Decoder
2017 年の Transformer 論文は基礎を作りました。しかし、多くの現代 LLM decoder block は、元の図をそのまま写したものではありません。
中心の考え方は同じです。
attention で token 同士を交流させ、FFN で token ごとの変換を行い、residual path で情報を保つ。
ただし、より深いモデル、長いコンテキスト、速い推論、安定した学習のために、多くの細部が変化しました。
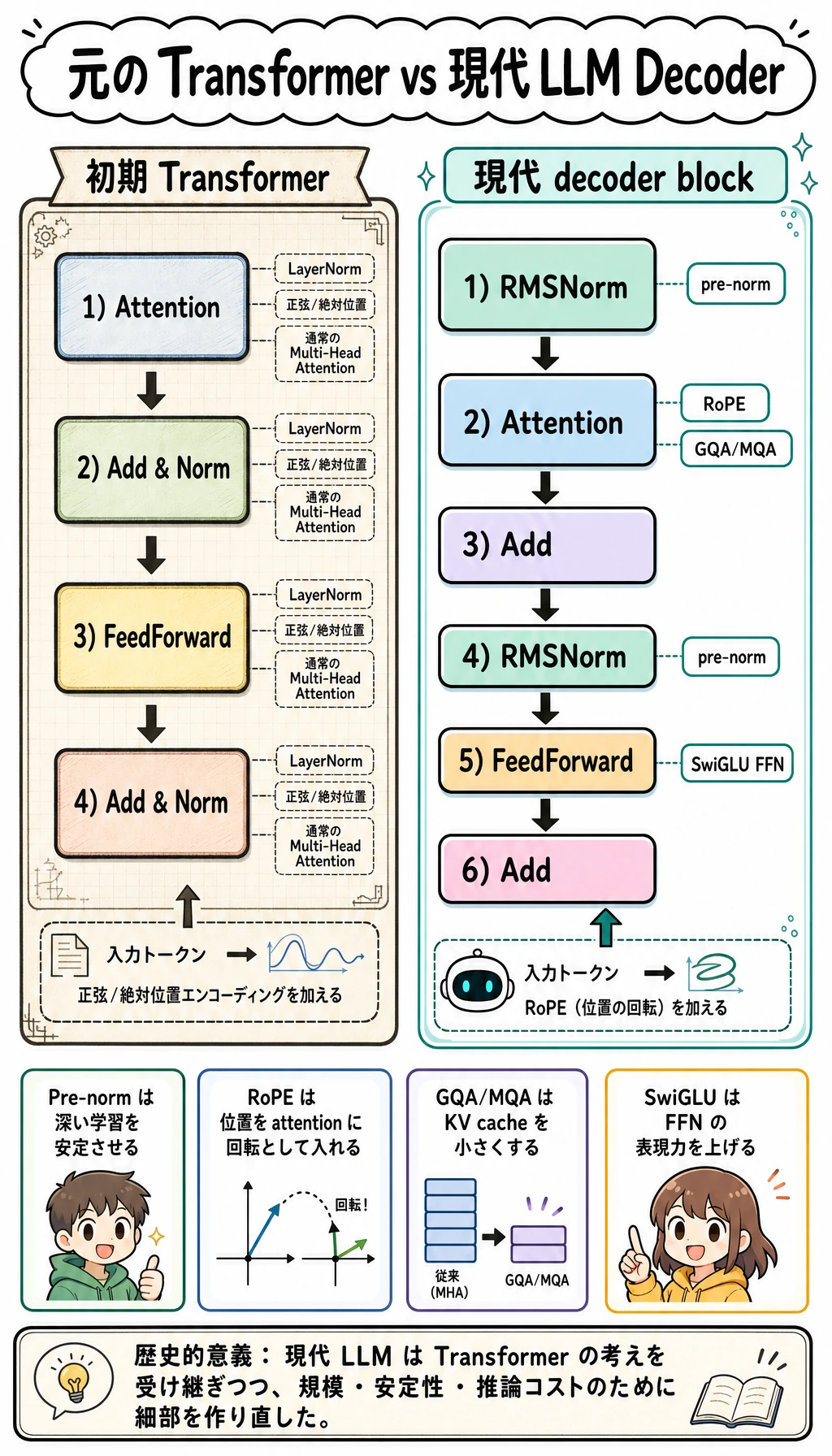
最初から名前を暗記しないでください。左右の流れを物語として読みます。元の block は Transformer を成立させ、現代 decoder block は同じ考えを保ちながら、LLM 規模のために normalization、位置表現、K/V 共有、FFN 設計を変えています。
初期 Transformer block
単純化した初期 Transformer block は、よく次のように説明されます。
Attention -> Add & Norm -> FeedForward -> Add & Norm
よく出てくる特徴は次の通りです。
- residual add の後に LayerNorm
- 正弦または絶対位置エンコーディング
- 通常の Multi-Head Attention
- 初期の説明では ReLU 系の feed-forward network
この構造は、今でも入門にはとても向いています。主線が分かりやすいからです。
しかし、モデルが深くなり、コンテキストが長くなり、長い対話を処理するようになると、次の問題が目立ちます。
- 深い学習が不安定になりやすい
- 絶対位置は長い文脈への拡張が柔軟ではない
- 推論時の KV cache コストが高い
- FFN により強い表現力が必要になる
よくある現代 LLM decoder block
単純化すると、現代 decoder block は次のような形によくなります。
RMSNorm -> Attention -> Add -> RMSNorm -> FeedForward -> Add
よくある特徴は次の通りです。
- post-norm ではなく pre-norm
- 完全な LayerNorm ではなく RMSNorm
- 位置表現に RoPE を使う
- KV cache 圧力を下げるために GQA または MQA を使う
- SwiGLU 系 FFN を使う
もちろん、すべての現代モデルが同じではありません。 モデルごとに選ぶ細部は違います。 それでも、このパターンは十分よく出てくるので、モデルコードを読むときに認識できるようにしておきましょう。
Pre-norm:先に正規化してから sublayer へ入る
post-norm block では、正規化はよく次の後にあります。
x + sublayer(x)
pre-norm block では、sublayer がまず正規化済みの入力を受け取ります。
x + sublayer(norm(x))
なぜ大事なのでしょうか?
Pre-norm は、非常に深い Transformer を学習しやすくします。residual path がよりきれいに保たれるからです。多くの層を通る安定した情報の高速道路だと考えると分かりやすいです。
実際のコードでは、次のような形をよく見ます。
x = x + attention(norm1(x))
x = x + ffn(norm2(x))
RMSNorm:より軽い正規化
LayerNorm は平均と分散を使って正規化します。 RMSNorm は root mean square、つまり二乗平均平方根の大きさを使い、平均を引く部分を省きます。
初心者向けには次のように考えるとよいです。
- LayerNorm:「各値は平均からどれくらい離れているか?」
- RMSNorm:「このベクトル全体はどれくらい大きいか?」
RMSNorm がよく使われるのは、より単純で効率的でありながら、大規模モデルを十分安定させられるからです。
最初から式を導く必要はありません。まず役割を覚えます。
RMSNorm は、より軽い正規化で activation の数値を安定させる。
RoPE:位置を attention に回転として入れる
初期 Transformer の例では、位置ベクトルを token embedding に足すことがよくあります。 現代 LLM では次をよく使います。
- RoPE:Rotary Position Embedding
直感は次の通りです。
入力で位置ベクトルを一度足すのではなく、位置に応じて Q と K を回転させ、相対位置情報を attention score に入れる。
なぜ便利なのでしょうか?
- attention の内部で自然に働く
- 相対位置の信号を入れやすい
- 単純な絶対位置 embedding より拡張や適応がしやすいことが多い
モデルコードでは、RoPE は通常 attention 計算の近く、QK^T の前に出てきます。
GQA / MQA:KV cache の圧力を下げる
推論時、decoder-only モデルは過去 token の K と V をキャッシュします。
これが次のものです。
- KV cache
通常の Multi-Head Attention では、多くの head がそれぞれ K/V を持つことがあります。 現代の推論サービスでは、このメモリ圧力を下げる必要があります。
よくある選択肢は次の 2 つです。
| 用語 | 意味 | 主に節約するもの |
|---|---|---|
| MQA | Multi-Query Attention:多くの query heads が 1 組の K/V を共有する | K/V 共有を最大化する |
| GQA | Grouped-Query Attention:query heads をグループ化し、グループごとに K/V を共有する | 品質と cache サイズのバランス |
実務的な直感は次です。
GQA/MQA は主にモデルを賢くするためではなく、長文脈推論を安くするための工夫です。
SwiGLU FFN:より強い feed-forward block
元の Transformer FFN は、よく次のように説明されます。
Linear -> activation -> Linear
多くの現代 LLM は、次のような gated FFN を使います。
- SwiGLU
直感は次の通りです。
- 片方の経路が候補特徴を作る
- もう片方の経路が gate のように働く
- gate が、どの特徴を強く通すかを決める
次のように覚えるとよいです。
SwiGLU は FFN に特徴を作らせるだけでなく、どの特徴を強調するかも制御させる。
小さな decoder block 検査を実行する
このスクリプトは完全な LLM を実装するものではありません。 目的はもっと狭く、いくつかのアーキテクチャ用語を観察できる挙動につなげることです。
from math import sqrt
activation = [2.0, -1.0, 0.5, 3.0]
def layer_norm(xs, eps=1e-6):
mean = sum(xs) / len(xs)
variance = sum((x - mean) ** 2 for x in xs) / len(xs)
return [(x - mean) / sqrt(variance + eps) for x in xs]
def rms_norm(xs, eps=1e-6):
rms = sqrt(sum(x * x for x in xs) / len(xs) + eps)
return [x / rms for x in xs]
decoder_config = {
"norm": "RMSNorm",
"position": "RoPE",
"query_heads": 32,
"kv_heads": 8,
"ffn": "SwiGLU",
}
print("LayerNorm:", [round(x, 3) for x in layer_norm(activation)])
print("RMSNorm :", [round(x, 3) for x in rms_norm(activation)])
print("position :", decoder_config["position"])
print("kv share :", decoder_config["query_heads"] // decoder_config["kv_heads"], "query heads per KV group")
print("ffn style:", decoder_config["ffn"])
期待される出力:
LayerNorm: [0.577, -1.402, -0.412, 1.237]
RMSNorm : [1.06, -0.53, 0.265, 1.589]
position : RoPE
kv share : 4 query heads per KV group
ffn style: SwiGLU

出力の読み方
LayerNormは平均を中心に値を整えます。RMSNormは主に全体の大きさをそろえます。kv shareは GQA を示します。4 個の query heads が 1 つの K/V group を共有します。RoPEとSwiGLUは飾りではありません。位置情報がどこで入るか、FFN が特徴をどう gate するかを表します。
コンパクトな比較表
| 部分 | 初期 Transformer の直感 | 現代 LLM decoder の直感 |
|---|---|---|
| 正規化の順序 | sublayer 後に Add & Norm | Attention / FFN 前に pre-norm |
| Norm 種類 | LayerNorm | RMSNorm がよく使われる |
| 位置 | 正弦または絶対位置 | RoPE がよく使われる |
| Attention heads | 通常の MHA | GQA / MQA がよく使われ、推論を軽くする |
| FFN | 基本 MLP / ReLU 系 | SwiGLU gated FFN がよく使われる |
| 主な圧力 | attention ベースの系列モデリングを成立させる | 深さ、文脈長、推論コストに耐える |
モデルコードを読むときの助け
現代モデルのコードを開いたら、Transformer という単語だけを探さないでください。
実際の部品を見つけます。
rms_normrotary_embq_proj、k_proj、v_projnum_key_value_headsgate_proj、up_proj、down_proj
これらの名前が、概念図と本物の LLM 実装をつなぐ橋です。
まとめ
現代 LLM decoder block は、元の Transformer を否定しているわけではありません。
同じ考えを、より厳しい制約に合わせて変えたものです。
- より深い学習
- より長いコンテキスト
- より低い latency
- より小さい KV cache
- より強い FFN 表現
これらの変化が分かると、現代 LLM のアーキテクチャ図やソースコードはずっと読みやすくなります。