7.3.6 モデル規模と計算
大規模モデルの話をするとき、多くの人がいちばん見がちなのは、たった1つの数字です。
- 7B
- 70B
- 671B
でも、実際に学習やデプロイまで考えると、パラメータ数だけではまったく足りません。
あわせて次のような要素も見る必要があります。
- hidden size
- 層数
- context length
- batch size
- KV cache
- スループットとレイテンシ
このレッスンでやるのは、「大規模モデルは大きい」というあいまいな言い方を、ちゃんと計算できて、見積もれて、判断できるエンジニアリングの言葉に分解することです。
学習目標
- パラメータ規模、コンテキスト長、計算コストの関係を理解する
- 学習時と推論時でコスト構造がなぜ違うのかを理解する
- 実行できる例を通して、パラメータ数と KV cache のざっくり見積もり方を学ぶ
- 「なぜモデルを無限に大きくできないのか」という現実的な見方を身につける
一、パラメータ数はあくまで最初の見え方
なぜみんな 7B / 70B のようにモデルを表すのか?
いちばんわかりやすいからです。
パラメータ数は、モデルの容量をざっくり表す指標として役立ちます。
- パラメータが多いほど、通常は表現できる上限が高い
ただし、これは最初の見え方にすぎません。
同じ大規模モデルでも、コストは他の多くの要素で変わる
たとえば、どちらも 7B と書かれていても、
次の違いだけでかなり差が出ることがあります。
- 層数が違う
- hidden size が違う
- head 数が違う
- context length が違う
- GQA / MoE を使っているかどうか
つまり、パラメータ数が無意味なのではなく、
それだけで判断してはいけないということです。
たとえ話:床面積は総コストそのものではない
パラメータ数は、家の床面積のようなものだと考えられます。
でも、実際のお金はそれだけでは決まりません。
- 階数や構造
- 内装の複雑さ
- 暖房や保守のコスト
同じように、大規模モデルの計算コストも、パラメータ数だけでは決まりません。
二、パラメータ数はどうやって増えていくのか?
decoder block の主な重みは Attention と FFN
ざっくり見積もるときは、主に次の2つを覚えておくと便利です。
- Attention projection
- FFN projection
多くの decoder-only モデルでは、
FFN のパラメータ数は Attention より大きくなることもあります。
とても使いやすい概算式
標準的な decoder block では、
次のような近似で考えられます。
- Attention 関連はおおよそ
4 * hidden^2 - FFN 関連はおおよそ
8 * hidden^2
したがって、1層あたりはだいたい次のように見積もれます。
12 * hidden^2
これに層数を掛ければ、
かなり実用的な一次見積もりになります。
なぜざっくり見積もりでも価値があるのか?
最初から1桁単位まで正確である必要はないからです。
むしろ大事なのは次のような点です。
- だいたいどのくらいの規模か
- どの部分が大きいコストを占めるか
- どのハイパーパラメータを変えるとコストが一気に上がるか
三、まずは本当に役立つ見積もりスクリプトを動かそう
次のスクリプトは、現場でよく使う2つの量を見積もります。
- decoder-only モデルのおおよそのパラメータ数
- 推論時の KV cache のおおよその使用量
def approx_decoder_params(num_layers, hidden_size, ffn_multiplier=4, vocab_size=50000):
attention_params = 4 * hidden_size * hidden_size
ffn_params = 2 * hidden_size * (hidden_size * ffn_multiplier)
norm_params = 4 * hidden_size
block_params = attention_params + ffn_params + norm_params
embedding_params = vocab_size * hidden_size
total = num_layers * block_params + embedding_params
return total
def kv_cache_bytes(
num_layers,
seq_len,
batch_size,
num_kv_heads,
head_dim,
dtype_bytes=2,
):
# 2 は K と V の2つのキャッシュを表す
return num_layers * batch_size * seq_len * num_kv_heads * head_dim * 2 * dtype_bytes
def human_readable(num_bytes):
units = ["B", "KB", "MB", "GB", "TB"]
value = float(num_bytes)
for unit in units:
if value < 1024 or unit == units[-1]:
return f"{value:.2f} {unit}"
value /= 1024
configs = [
{
"name": "small",
"layers": 24,
"hidden": 2048,
"kv_heads": 16,
"head_dim": 128,
"seq_len": 4096,
},
{
"name": "large",
"layers": 48,
"hidden": 4096,
"kv_heads": 8,
"head_dim": 128,
"seq_len": 8192,
},
]
for cfg in configs:
params = approx_decoder_params(cfg["layers"], cfg["hidden"])
kv_bytes = kv_cache_bytes(
num_layers=cfg["layers"],
seq_len=cfg["seq_len"],
batch_size=1,
num_kv_heads=cfg["kv_heads"],
head_dim=cfg["head_dim"],
)
print("-" * 60)
print("model :", cfg["name"])
print("rough params:", f"{params / 1e9:.2f}B")
print("kv cache :", human_readable(kv_bytes))
期待される出力:
------------------------------------------------------------
model : small
rough params: 1.31B
kv cache : 768.00 MB
------------------------------------------------------------
model : large
rough params: 9.87B
kv cache : 1.50 GB

このコードでいちばん大事なポイントは?
1つ目:
- パラメータ数は
hidden_size^2と強く関係している
つまり hidden size が少し大きくなるだけでも、
コストはかなり急に増えます。
2つ目:
- KV cache は
layers * seq_len * kv_heads * head_dimによって増える
だからこそ、コンテキスト長と推論メモリは強く結びついています。
なぜ large モデルの負荷は単純な倍増ではないのか?
多くの項目が同時に増えるからです。
- 層数が増える
- hidden size が増える
- seq_len が増える
これらが重なると、
学習コストも推論コストも、かなり大きくなります。
なぜ GQA / MQA は推論の負荷をやわらげるのか?
それらは直接、次の値を減らすからです。
num_kv_heads
そしてこれは、KV cache の式の中でも重要な項目です。
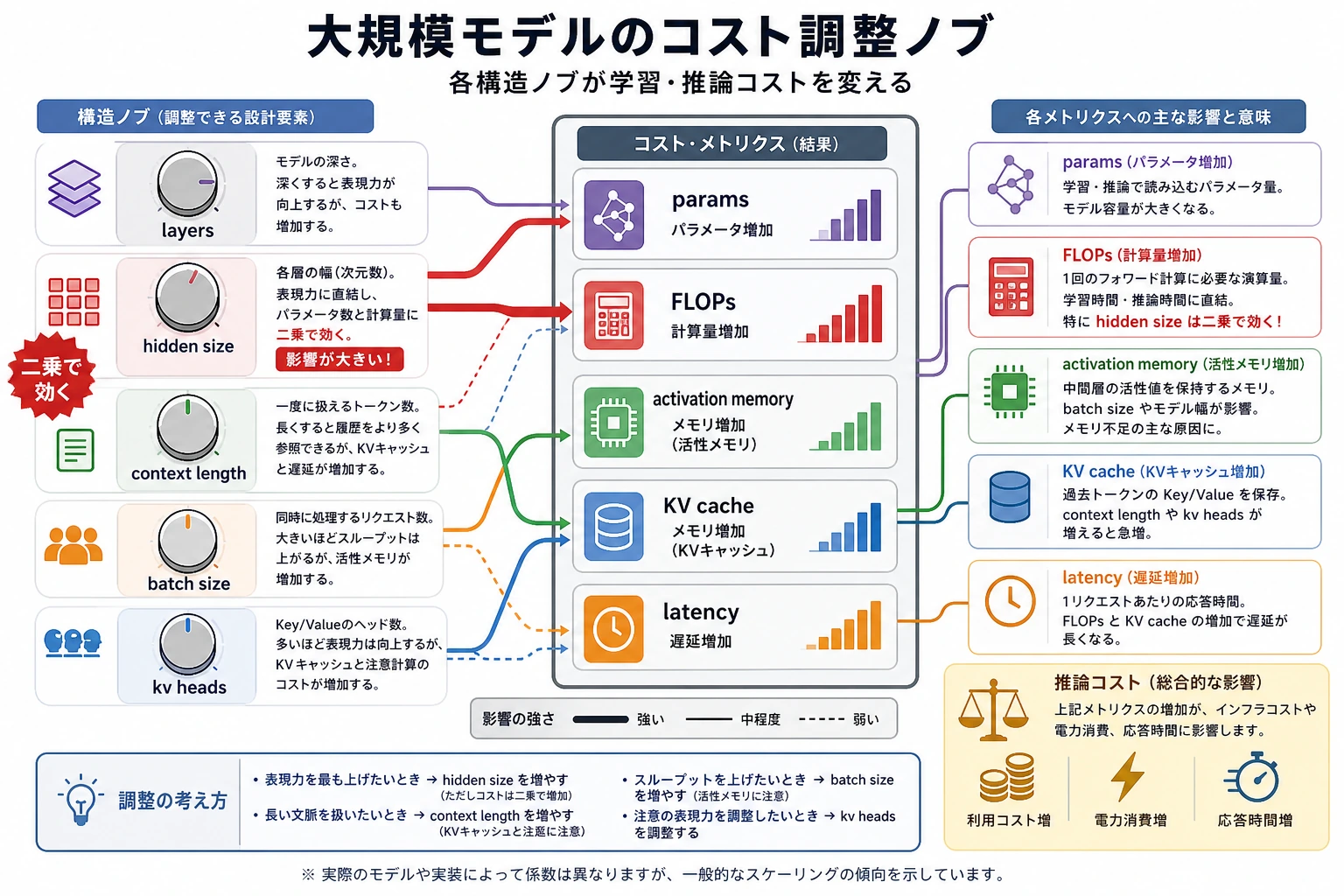
この図では、コストをいくつかのノブに分けています。layers、hidden size、context length、batch size、kv heads です。初心者が見落としやすいのは、これらのノブが足し算ではなく、掛け算のように効いて一気に増えることです。特に hidden size は、パラメータ数と計算量の両方に二乗で効くことが多いです。
四、学習時と推論時は何が違うのか?
学習時にいちばん詰まりやすいのは?
学習時によくあるボトルネックは次の通りです。
- パラメータ本体
- 勾配
- オプティマイザ状態
- 中間の activation
そのため学習では、特に次のような点が重要になります。
- mixed precision
- gradient checkpointing
- tensor parallelism / data parallelism
- activation memory
推論時にいちばん詰まりやすいのは?
推論時の中心的な負荷は、より次のものにあります。
- KV cache
- スループット
- 1リクエストあたりのレイテンシ
- 同時接続時の GPU メモリ
そのため、次の点をよく気にします。
- batch をどう設定するか
- コンテキストをどれくらい長くするか
- kv heads は何個あるか
- cache を量子化できるか
なぜ「学習できる」ことと「うまくデプロイできる」ことは別なのか?
学習と推論は、そもそも同じ workload ではないからです。
学習は次のような性質があります。
- 大きな batch
- 継続的な更新
- スループット重視
推論は次のような性質があります。
- リアルタイム応答
- cache が積み上がる
- レイテンシ重視
だから、学習では問題なかった設計でも、
デプロイすると非常に苦しくなることがあります。
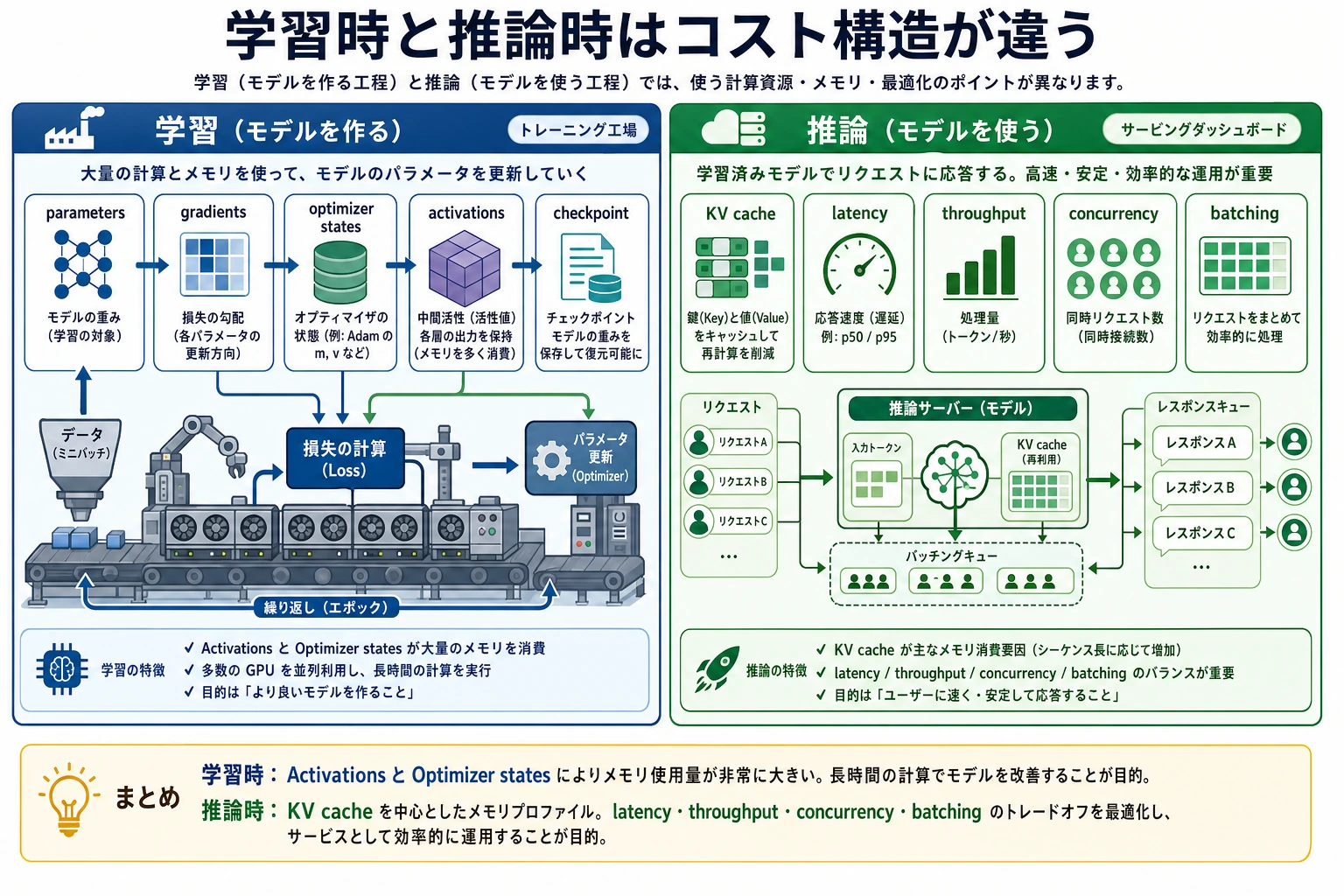
学習時は「継続的な生産」に近く、パラメータ、勾配、オプティマイザ状態、中間 activation を見るのが重要です。推論時は「リアルタイムサービス」に近く、KV cache、レイテンシ、スループット、同時実行時のメモリが重要です。学習できることと、うまくデプロイできることは別で、両者の詰まりどころはまったく違います。
五、スケールアップは「大きいほど良い」ではなく、「大きいほど高い」
パラメータを増やすのは、能力の可能性を増やすことであって、無料で性能が上がるわけではない
パラメータが増えると、表現力の上限が上がることは多いです。
でも、そのためには次の条件も必要です。
- 十分なデータ
- 十分な学習 token
- 十分な計算資源
これらが足りないと、モデルはただ「大きい」だけで、
「その大きさに見合う価値」が出ないことがあります。
コンテキストを長くするのも、無料ではない
context length を伸ばすと、次の利点があります。
- より多くの情報を使える
ただし同時に、次の負担も増えます。
- Attention の計算コストが上がる
- KV cache が大きくなる
- 長距離情報を安定して使うのが難しくなる
つまり、「128k に対応している」ことと、
「128k を全部うまく使える」ことは別です。
スケールアップでよくある現実的な3つの問題
- 学習コストが急激に上がる
- 推論サービスのコストも一緒に上がる
- データや学習 token が足りないと、追加投資の効果が下がる
つまり、スケールアップの本質は、
- 能力、コスト、データのバランスを取ること
です。
六、とても実用的な判断の順番
学習側で詰まっているなら
まず次を確認します。
- hidden size を攻めすぎていないか
- batch と seq_len が高すぎないか
- 中間 activation が主なボトルネックではないか
推論側で詰まっているなら
まず次を確認します。
- コンテキスト長
- 同時リクエスト数
- kv cache のサイズ
- GQA / MQA / cache quantization を使えるか
モデル規模を設計するなら
先に次の3つを自問します。
- そのデータ量で本当に支えられるか?
- 学習予算は持つか?
- 上線後の推論コストは受け入れられるか?
この3つを一緒に考えないと、
モデル設計はすぐ「大きいほど良い」という幻想に引っ張られます。
七、よくある誤解
誤解1:パラメータが大きければ、必ず性能も良い
不十分です。
パラメータ数は容量であって、自動的に性能を保証するものではありません。
誤解2:推論コストはパラメータ数だけで決まる
違います。
コンテキスト長と KV cache も、同じくらい重要になることがよくあります。
誤解3:学習用メモリと推論用メモリは同じ
違います。
両者は、メモリの内訳もボトルネックも異なります。
まとめ
この節でいちばん大事なのは、あるモデルが何 B かを覚えることではありません。
その代わり、次のような、より現実的な言葉を身につけることです。
モデル規模 = パラメータ容量、計算コスト = パラメータ、層数、hidden、コンテキスト長、KV cache、batch、そして実装方法を合わせて決まる。
これらをまとめて見られるようになると、
「なぜ大規模モデルは高いのか」「どこにコストがあるのか」「どう抑えるべきか」が、工程の感覚としてわかるようになります。
練習
- 例の
seq_lenを4096から16384に変えて、KV cache の使用量がどう変わるか確認してください。 - なぜ hidden size は、多くの人が思うよりずっと「高い」のでしょうか?
- 自分の言葉で説明してください。学習が通っても、デプロイが楽とは限らないのはなぜですか?
- 長い会話サービスを作るなら、パラメータ数以外に、最初にどんな指標を気にしますか?