7.3.2 Transformer アーキテクチャの振り返りと深掘り
注意機構を学んだことがあれば、Q / K / V という言葉はすでに知っているかもしれません。
でも、実際に大規模モデルの段階に入ると、そこでつまずく人は多いです。
- なぜ 1 つの block の中で、先に attention、後に前馈ネットワークなのか?
- なぜ残差と LayerNorm は何度も出てくるのか?
- 同じ Transformer なのに、なぜ GPT と BERT は最終的に違う方向へ進めるのか?
このレッスンの目的は、構造図をもう一度暗記することではありません。
1 つの Transformer block を実際に分解して、データフローに沿って説明できるようになることです。
学習目標
- Transformer block の中で、各モジュールがそれぞれ何を担当しているかを理解する
- token embedding、位置情報、自注意力、FFN がどうつながっているかを理解する
- 実行できる最小限の block の例を通して、「データがどう流れるか」の感覚を身につける
- なぜ残差接続と正規化が深いネットワークで重要なのかを理解する
一、なぜ Transformer は大規模モデルの土台になったのか?
解いているのは「系列の中で誰が誰を見るべきか」という問題
言語は本来、系列です。
モデルが 1 つの文を処理するとき、次のことを知る必要があります。
- 現在の単語は、どの前の単語と関係があるのか
- どの位置がより重要なのか
- 長距離の依存関係をどう保つのか
RNN の考え方は順番に読むこと、
CNN の考え方は局所畳み込みです。
それに対して Transformer の考え方は次の通りです。
各位置が自分から他の位置を「見に行き」、重みを割り当てる。
これが self-attention の核心です。
Transformer の本当に強いところは attention だけではない
Transformer を次のように単純化してしまう人は多いです。
- attention があるネットワーク
でも、実際に大規模学習に向いている理由は、1 つの要素ではなく全体の組み合わせにあります。
- token embedding
- 位置表現
- multi-head self-attention
- 残差接続
- LayerNorm
- 前馈ネットワーク
- 積み重ね可能な block 構造
この組み合わせによって、系列関係を表現できるだけでなく、深く、巨大に、並列に学習できます。
たとえ話: 各 block は「議論 + 整理」みたいなもの
Transformer block は会議のようなものだと考えると分かりやすいです。
- self-attention は「各 token が、他の token が何を言っているかを聞く」
- 前馈ネットワークは「文脈を受け取った後、それぞれの token が個別に内部処理をする」
- 残差接続は「元の発言を残して、新しい処理で完全に上書きしない」
1 つの block が 1 回の議論を担当し、
複数の block を重ねると、情報を何度も議論して整理する集団のようになります。
二、Transformer block の中には何があるのか?
まず入力をベクトルに変える
モデルが見ているのは文字そのものではなく、token id です。
この token id は embedding table を参照して、ベクトルに変換されます。
例えば:
我->[0.2, -0.1, 0.8, ...]喜欢->[0.7, 0.3, -0.2, ...]
このステップでやっているのは、
離散的な記号を、連続空間の表現に変えること。
次に位置情報を補う
attention 自体は「集合の中での関係」しか分かりません。
token が元々何番目にあるのかは知りません。
そのため、モデルに次の情報を伝える必要があります。
- 1 番目の token
- 2 番目の token
- 3 番目の token
これらの位置情報は、次の方法で注入できます。
- 正弦波の位置エンコーディング
- 学習可能な位置ベクトル
- RoPE などの相対位置手法
self-attention は「token をまたいだ交流」を担当する
self-attention では、各 token が 3 種類の表現を作ります。
- Query: 何を探したいか
- Key: 何を提供できるか
- Value: 注目されたときに最終的に渡す内容
その後、各 token は 2 ステップで計算します。
- 自分の
Queryと他の token のKeyから類似度を計算する - その類似度を使って、他の token の
Valueを重み付けする
その結果得られるのは、
- 「文脈を取り込んだ新しい表現」
です。
前馈ネットワークは「単独の token を深く加工する」
Transformer を学び始めたばかりの人は、attention だけが核心だと思いがちです。
でも実際には、FFN も非常に重要です。
特徴は次の通りです。
- 各 token がそれぞれ小さな MLP を通る
- token 同士の交流はしない
- ただし、非線形の表現力を高める
こう理解するとよいです。
attention は情報を交換し、FFN は情報を消化する。
なぜ残差と正規化が何度も出てくるのか?
深いネットワークは、訓練が不安定になりやすいからです。
残差接続と LayerNorm の役割は、まずはざっくり次のように覚えれば十分です。
- 残差: 古い情報を保ち、新しい情報を「増分更新」にする
- LayerNorm: 各層の出力を、より安定した数値範囲に戻す
これらがないと、
深い Transformer は訓練がとても難しくなります。
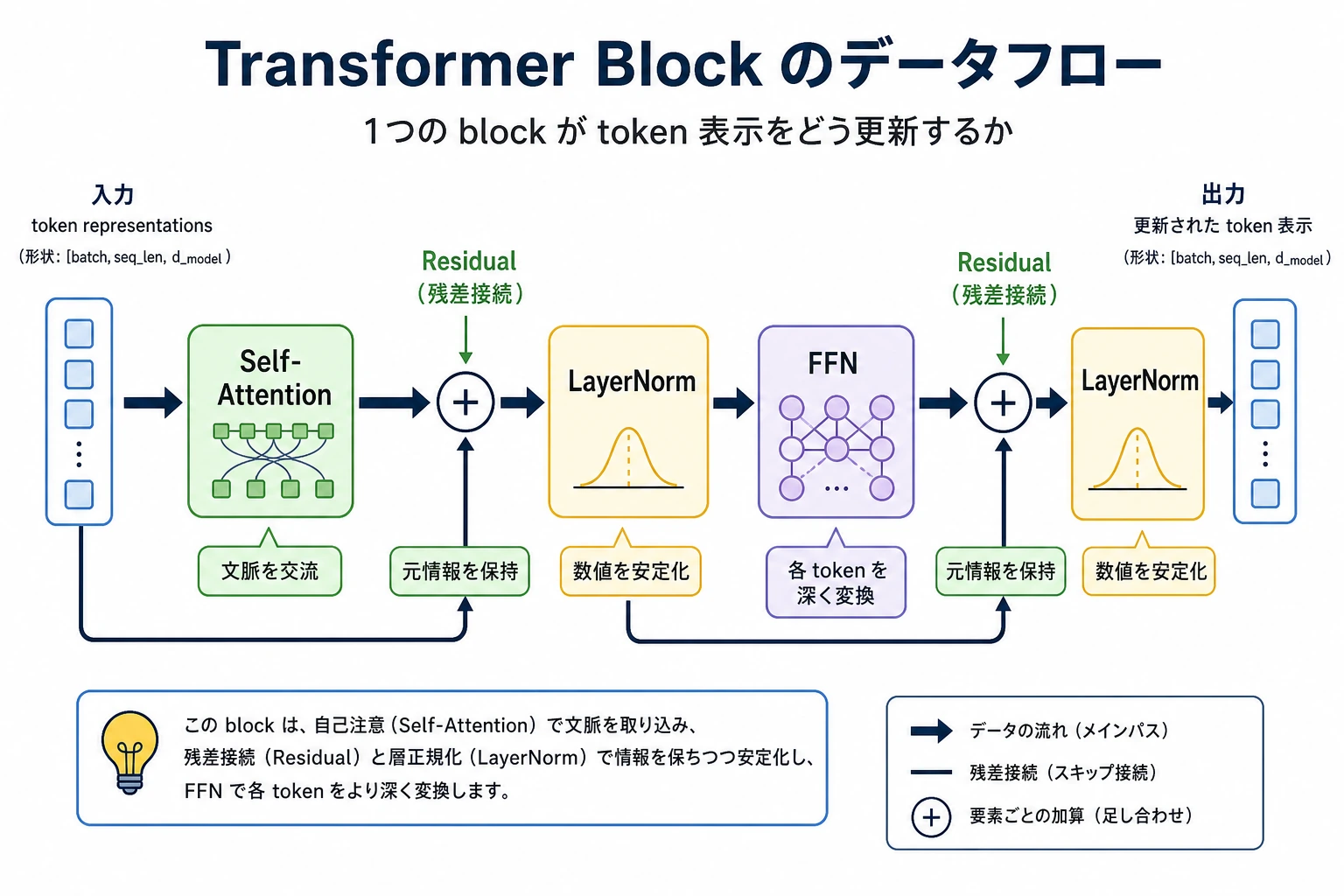
この図は 1 層の block のデータフローとして読むのがおすすめです。token 表現はまず Self-Attention で文脈と交流し、その後 Residual/LayerNorm で情報を安定させ、最後に FFN で token ごとの深い加工に入ります。Transformer は attention だけではなく、「交流、保持、安定化、加工」の組み合わせです。
三、まずは本当に最小限の Transformer block を動かしてみよう
下のコードは、純粋な Python で次のことを行います。
- 3 つの token ベクトルを入力する
- 1 ヘッドの self-attention を計算する
- 残差接続を行う
- その後、小さな前馈ネットワークを通す
これは完全な本番実装ではありませんが、各ステップは実際の block の中心構造に対応しています。
from math import exp, sqrt
tokens = [
[1.0, 0.0, 1.0],
[0.0, 1.0, 1.0],
[1.0, 1.0, 0.0],
]
W_q = [
[1.0, 0.0],
[0.5, 1.0],
[0.0, 1.0],
]
W_k = [
[1.0, 0.5],
[0.0, 1.0],
[1.0, 0.0],
]
W_v = [
[1.0, 0.0, 0.5],
[0.0, 1.0, 0.5],
]
W1 = [
[1.0, -0.5],
[0.5, 1.0],
[1.0, 0.5],
]
W2 = [
[0.5, 1.0, 0.0],
[1.0, 0.0, 0.5],
]
def matmul_vec(vec, matrix):
return [
sum(vec[i] * matrix[i][j] for i in range(len(vec)))
for j in range(len(matrix[0]))
]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
def softmax(values):
m = max(values)
exps = [exp(v - m) for v in values]
total = sum(exps)
return [x / total for x in exps]
def add(a, b):
return [x + y for x, y in zip(a, b)]
def relu(vec):
return [max(0.0, x) for x in vec]
Q = [matmul_vec(token, W_q) for token in tokens]
K = [matmul_vec(token, W_k) for token in tokens]
V_in = [[1.0, 0.0], [0.0, 1.0], [1.0, 1.0]]
V = [matmul_vec(v, W_v) for v in V_in]
scale = sqrt(len(Q[0]))
scores = []
for i, q in enumerate(Q):
row = []
for j, k in enumerate(K):
row.append(dot(q, k) / scale if j <= i else -10**9)
scores.append(row)
weights = [softmax(row) for row in scores]
contexts = []
for row in weights:
context = [0.0, 0.0, 0.0]
for w, v in zip(row, V):
context = [c + w * x for c, x in zip(context, v)]
contexts.append(context)
after_attention = [add(token, context) for token, context in zip(tokens, contexts)]
ffn_hidden = [relu(matmul_vec(vec, W1)) for vec in after_attention]
ffn_output = [matmul_vec(vec, W2) for vec in ffn_hidden]
block_output = [add(x, y) for x, y in zip(after_attention, ffn_output)]
print("attention weights:")
for row in weights:
print([round(x, 3) for x in row])
print("\nblock output:")
for row in block_output:
print([round(x, 3) for x in row])
期待される出力:
attention weights:
[1.0, 0.0, 0.0]
[0.413, 0.587, 0.0]
[0.456, 0.225, 0.32]
block output:
[3.75, 3.5, 1.5]
[3.897, 4.294, 2.566]
[4.366, 4.752, 1.153]
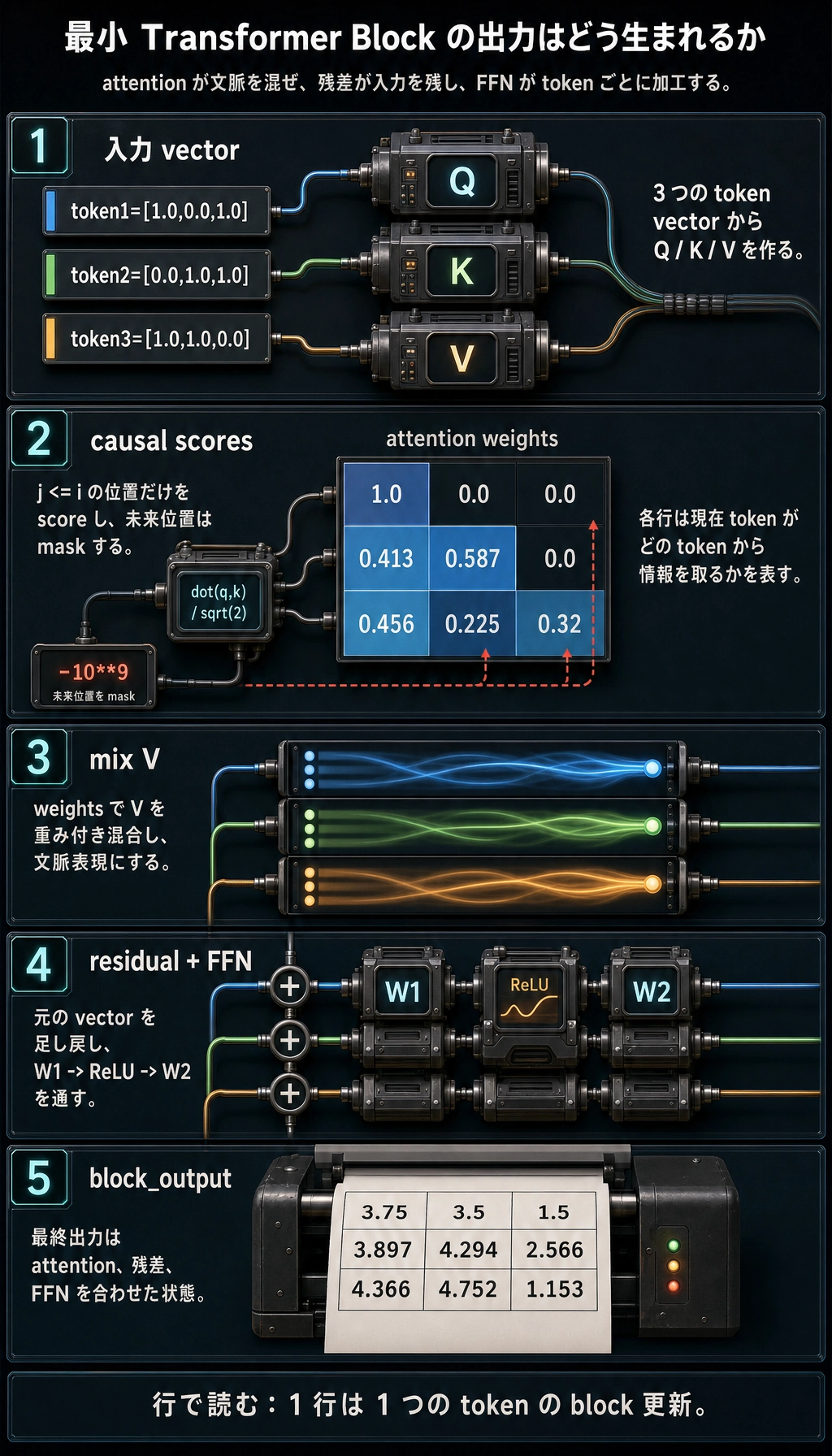
このコードを読むときは、まず 4 つの場所に注目する
最も重要なのは次の 4 か所です。
Q / K / Vの生成scoresの計算softmax後の重み付き和- 残差 + FFN
この 4 つが理解できれば、
Transformer block の理解は「図を暗記するだけ」の段階を越えています。
なぜここで causal mask を加えるのか?
この行に注目してください。
row.append(dot(q, k) / scale if j <= i else -10**9)
これは次を意味します。
- 現在の token は、自分自身とそれ以前の token だけを見ることができる
- 未来は見てはいけない
これが GPT のような decoder-only モデルを訓練するときの重要な制約です。
もし j <= i を消すと、
encoder のような双方向 attention に近くなります。
なぜ attention の後に FFN が必要なのか?
attention は「文脈を集約する」処理だからです。
つまり、現在の token に対して、
- 誰を注目すべきか
を教えてくれます。
ただし、十分に非線形な変換は得意ではありません。
FFN の役割は次の通りです。
- 文脈を統合した表現を、もう一段深く加工する
つまり、役割が違うので、両方必要です。
四、block を全体構造の中に戻して見る
多層に積むということは、抽象化を段階的に進めるということ
1 層目の attention が見ているのは、主に次のようなものです。
- 語法的な関係
- 近い位置のパターン
より高い層では、次のようなものが徐々に形成されます。
- 構文関係
- 意味役割
- 長距離依存
- タスク関連の特徴
だから Transformer は「1 層の attention」ではなく、
たくさんの block を積み重ねた構造なのです。
Encoder と Decoder の違いは、主に mask と相互作用の仕方
block だけを見ると、両者はかなり似ています。
主な違いは次の通りです。
- encoder: 通常は双方向 self-attention
- decoder: 通常は causal mask
- encoder-decoder: decoder に cross-attention が追加される
つまり、多くの構造上の違いは最終的に、
- 誰が誰を見られるか
に帰着します。
GPT が decoder だけを残した理由
生成タスクで最も重要な制約は、
- 過去を使って未来を予測することだけができる
という点です。
decoder-only はこの目的により合っていて、構造も直接的です。
これが GPT 系列が大きく発展していった理由の 1 つです。
五、実務で見落としやすい点
attention は無料ではない
各 token は他の token と比較する必要があります。
系列が長くなると、コストは一気に増えます。
そのため後になって、次のような工夫が登場しました。
- 高効率 attention
- KV cache
- GQA / MQA
- FlashAttention
block 構造はシンプルに見えても、訓練は簡単ではない
層数や hidden size が大きくなると、すぐに次の問題が出ます。
- メモリ負荷
- 勾配の安定性
- スループットとレイテンシのトレードオフ
Transformer が本当に大規模モデルの土台になれたのは、
「構造がきれいだから」だけではありません。
多くの実装・最適化の工夫が積み重なったからです。
block を理解すると、その後の多くの章が楽になる
これから学ぶ次の内容は、
- アーキテクチャ変種
- 高効率 attention
- 事前学習方法
- ファインチューニング
などですが、根っこはこの block の改造や応用です。
六、よくある誤解
誤解 1: Transformer = attention
不完全です。
Transformer は 1 つの式ではなく、block 設計のセットです。
誤解 2: FFN は脇役
違います。
FFN は非常に重要な非線形特徴変換を担当しています。
誤解 3: QKV が分かれば Transformer を理解したことになる
本当に理解するには、次も含まれます。
- なぜ残差が重要なのか
- mask がどう振る舞いを決めるのか
- 多層に積むと、なぜ抽象化が起きるのか
まとめ
この節で最も重要なのは、構造図をもう一度覚えることではありません。
1 つの Transformer block のデータフローをつなげて理解することです。
token ベクトルはまず attention で文脈と交流し、次に前馈ネットワークで深く加工され、さらに残差と正規化によって、多層に積んでも訓練が安定する。
この流れが頭の中でつながれば、
その後の「大規模モデルは複雑に見える」という構造の多くは、実はこの block を少し変えているだけだと分かってきます。
練習
- 例の
j <= iを、常に許可する形に変えて、attention 重みがどう変わるか観察してみましょう。 - 残差接続を外してみて、
block_outputと元の入力の関係がまだ安定しているか確認してみましょう。 - 自分の言葉で説明してみましょう: なぜ attention は情報交換を担当し、FFN は情報の消化を担当するのか?
- この block を 48 層積むとしたら、いちばん心配な実務上の問題は何だと思いますか?