A.5 ハードウェアとクラウドリソースガイド
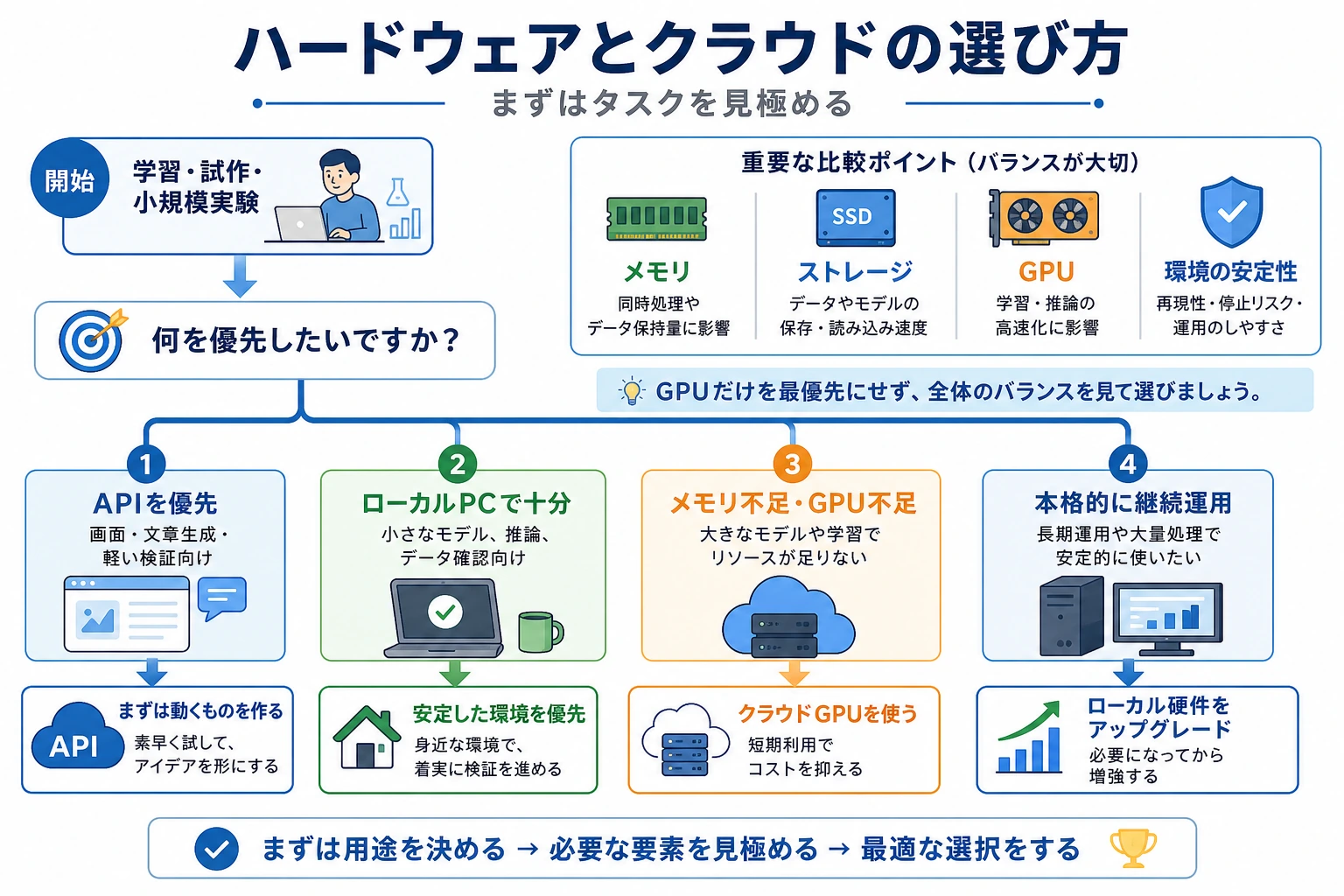
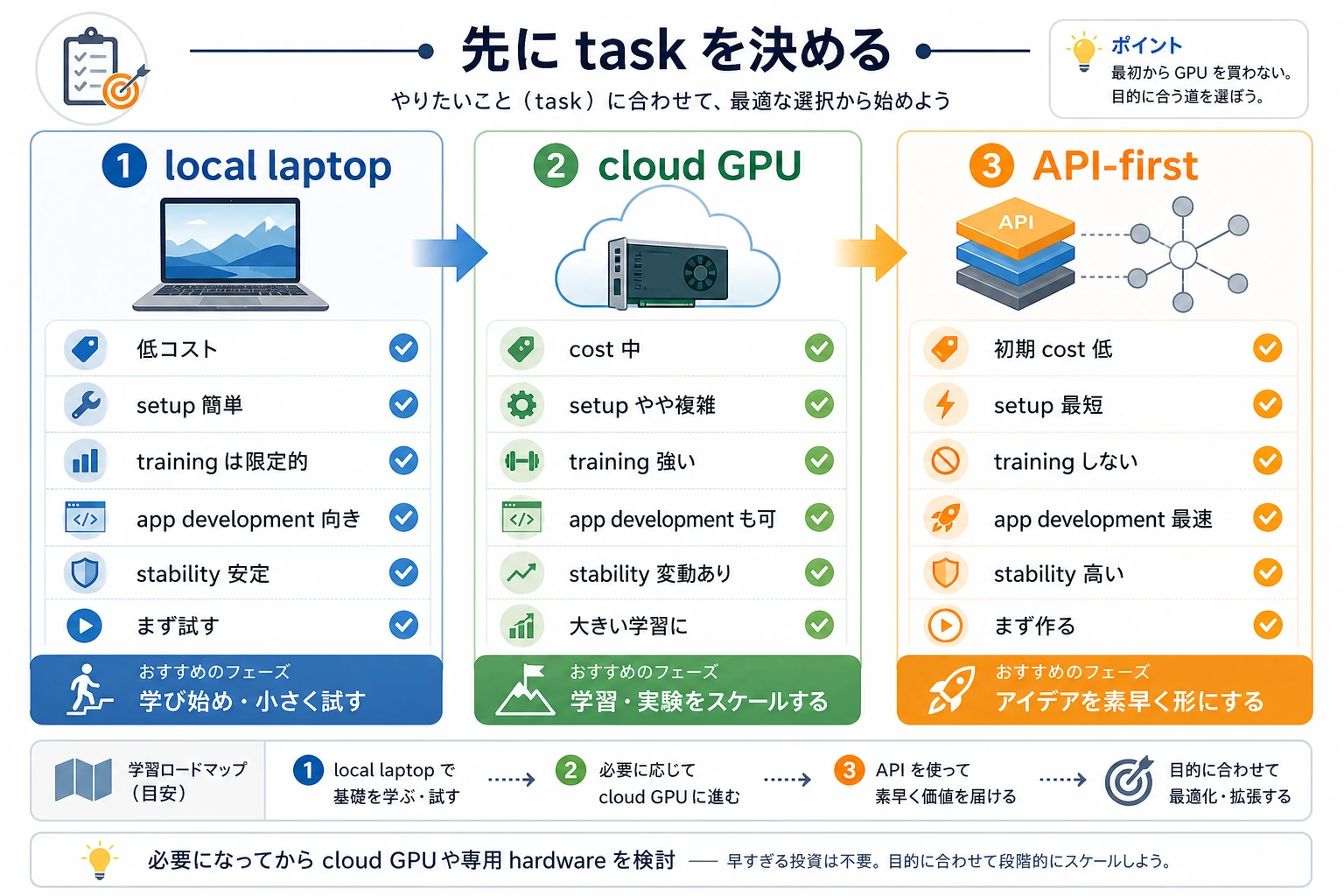
短い結論: 最初に GPU を買わないでください。まずタスクを見て、ローカル CPU、クラウド GPU、API のどれを使うか決めます。
クイック判断表
| 学習段階 | ローカルで必要なもの | 詰まったときの選択 |
|---|---|---|
| 第 1-5 章: ツール、Python、データ、数学、古典的 ML | 8-16GB RAM、SSD | 通常 GPU は不要 |
| 第 6 章: 深層学習基礎 | 16GB RAM | 学習用の訓練はクラウド GPU |
| 第 7 章: LLM 原理と微調整概念 | 16-32GB RAM | クラウド GPU または API 実験 |
| 第 8-9 章: RAG と Agent | 16GB RAM、安定したネットワーク | API 優先のエンジニアリング |
| 第 10-11 章: CV と NLP | 16GB RAM | 重めの実験はクラウド GPU |
| 第 12 章: マルチモーダル | 16-32GB RAM | クラウド生成または API サービス |
購入の優先順位
多くの学習者は、この順番で投資するほうが安定します。
- メモリ: 最低 16GB、快適なら 32GB。
- SSD: 最低 512GB、快適なら 1TB。
- 安定した環境: 整理された Python、Node、Docker、プロジェクトフォルダ。
- 表示と入力の快適さ: 外部モニタ、キーボード、マウス。
- GPU: 実際の負荷がわかってから。
クラウドや API を使うタイミング
| 選択肢 | 向いていること | 注意点 |
|---|---|---|
| 無料 notebook | 小さな demo とワークフロー理解 | 時間制限と可用性 |
| 時間課金クラウド GPU | コードとデータが明確な訓練実験 | 先に準備し、終わったらすぐ停止 |
| API 優先ルート | RAG、Agent、アシスタント、プロダクト | ログ、コスト、プライバシー、リトライ |
| ローカル GPU | 長期的で頻繁な訓練と高速なローカル反復 | VRAM、冷却、電源、総コスト |
ローカル GPU を買う価値があるとき
少なくとも 2 つ当てはまるなら検討します。
- 今後数か月、頻繁にモデルを訓練する。
- クラウドの待ち時間や制限が毎週のように邪魔になる。
- モデルサイズ、batch size、必要 VRAM がわかっている。
- 初期費用の低さより、高速なローカル反復が重要。
理由が「いつか必要かもしれない」だけなら、まだ待ちましょう。
実用的な進め方
第 1-5 章は今の PC で進めます。第 6、10、11 章で本当に訓練が必要になったときだけクラウド GPU を借ります。第 8-9 章は API 優先のエンジニアリングプロジェクトで進めます。ローカル GPU は、プロジェクト負荷が必要性を証明してから判断しましょう。