7.4.1 事前学習ロードマップ:データ、目的、エンジニアリング
事前学習は、モデルが広い言語パターンを最初に学ぶ工程です。エンジニアリング視点では、データを整え、目的を決め、大規模に学習し、リスクを追跡します。
まず事前学習の三角形を見る
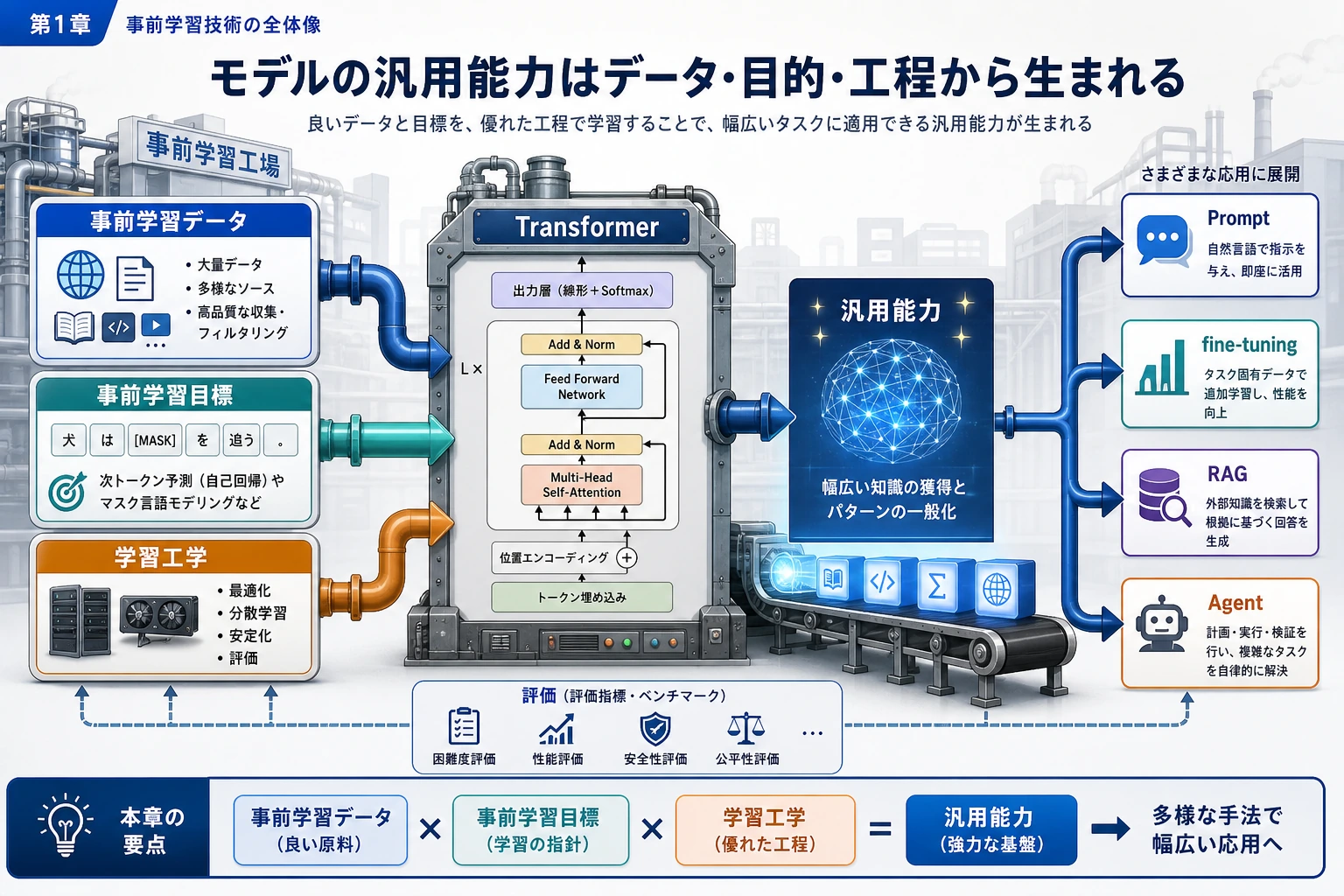
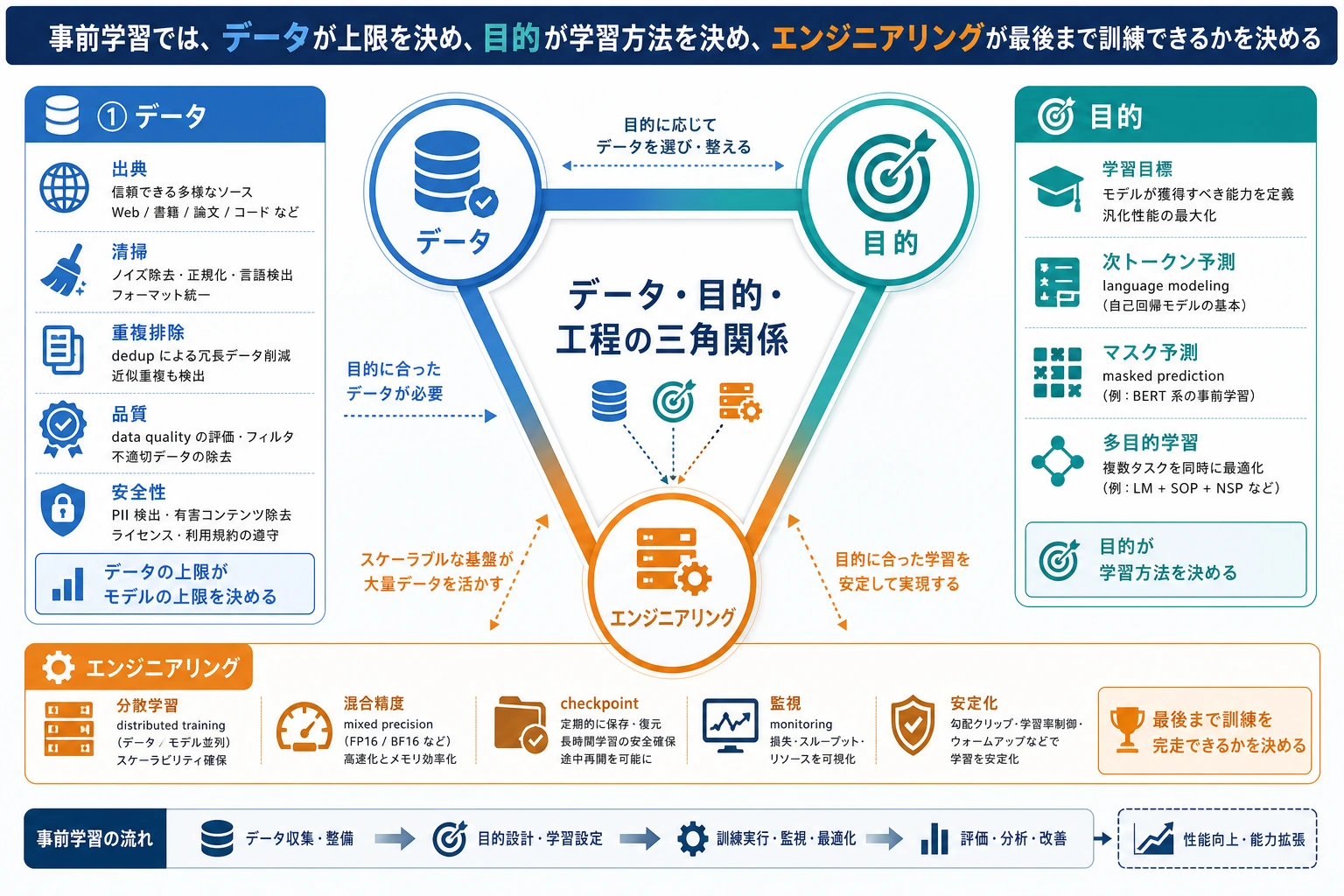
| 要素 | 最初に問うこと |
|---|---|
| データ | どのテキストを学習に入れ、何を除外するか |
| 目的 | どの予測タスクが学習信号を作るか |
| エンジニアリング | スケール、checkpoint、ログ、失敗をどう扱うか |
| 評価 | モデルに何ができ、どこで失敗するか |
next-token ペアを作る
tokens = ["AI", "learns", "from", "text"]
pairs = list(zip(tokens[:-1], tokens[1:]))
for source, target in pairs:
print(f"{source} -> {target}")
出力:
AI -> learns
learns -> from
from -> text
この小さな例が next-token prediction の形です。本物の事前学習では、これを巨大なテキストと厳密なデータガバナンスに広げます。
この順番で学ぶ
| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 7.4.2 事前学習データ | ソース、フィルタリング、重複除去、汚染 |
| 2 | 7.4.3 事前学習手法 | next-token prediction、loss、scaling |
| 3 | 7.4.4 事前学習エンジニアリング | 分散学習、checkpoint、監視 |
合格ライン
データ、目的、エンジニアリングが最終モデルへどう影響するか、そして contamination が評価を誤解させる理由を説明できれば合格です。