7.4.2 事前学習データ
多くの人は、大規模モデルというと、まず次のような点を思い浮かべます。
- パラメータ数がどれくらいか
- アーキテクチャがどれだけ新しいか
- どれくらい長く学習したか
でも、モデルが「何を学ぶか」「何を学ばないか」を本当に左右する土台は、事前学習データです。
そして、ここで本当に難しいのは次のことではありません。
- より多くのテキストを集めること
難しいのは、むしろ次のことです。
- どんなテキストを集めるか
- どうクリーニングするか
- どう配分するか
- どう重複と汚染を防ぐか
この節の目標は、「データが大事」という抽象的な話を、実際に使える判断へ分解することです。
学習目標
- 事前学習データの重要な品質観点を理解する
- 「データが多い」ことが必ずしも「良いデータ」を意味しない理由を理解する
- 実行可能な例を通して、クリーニング、重複排除、データ配分の意味を理解する
- 汚染、重複、低品質コーパスのリスク意識を身につける
この節は、前の LLM / 事前学習の流れとどうつながるのか
すでに「事前学習がモデルの土台を決める」という考えを受け入れているなら、この節の自然な続きは次の通りです。
- 前の節で、モデルの能力は事前学習から生まれると分かった
- この節ではさらに具体的に、その能力はどんなデータで作られるのかを問う
つまり、この節が本当に解決したいのは、「データが大事」という当たり前の話ではなく、次の点です。
- 事前学習データは何を決めるのか
- なぜデータエンジニアリングがモデルの上限に直接影響するのか
一、なぜ事前学習データがモデルの土台を決めるのか?
まずは物語で考える:2人の学生が違う本を読んだら?
2人の学生がいて、どちらも頭が良く、勉強法も同じだとします。
1人目は、質の高い教材、論文、技術文書、そして編集された長文を毎日読みます。2人目は、重複した広告、見出しだけのページ、転載サイト、混乱したコメントを毎日読みます。半年後、表現力、事実の信頼性、問題を分析する習慣は、かなり違っているはずです。
事前学習データがモデルに与える影響も、これと似ています。モデルのアーキテクチャは勉強法、計算資源は勉強時間、そしてデータは毎日読み込む教材です。教材が違えば、最終的に身につく能力の土台も変わります。
モデルが学ぶのは知識だけではなく、言語の癖や世界の分布でもある
事前学習段階でモデルは、自動的に次のような区別をしません。
- どの内容の信頼性が高いか
- どのテキストが単なるノイズか
- どの表現をまねる価値があるか
見たものを、できるだけそのまま近似しようとします。
そのため、事前学習データが最終的に影響するのは、次のような点だけではありません。
- 知識のカバー範囲
それだけでなく、次のものにも影響します。
- 言語スタイル
- 事実の信頼性
- バイアスの分布
- 安全性リスク
たとえ話:基礎の質が、その後のすべての仕上げの上限を決める
事前学習データは、家の基礎のようなものだと考えられます。
- 微調整は内装工事
- アラインメントは手すりやルール
もし基礎そのものが乱れていたら、
その後どれだけ微調整しても、多くはすでに固まった土台の上を少し直すだけです。
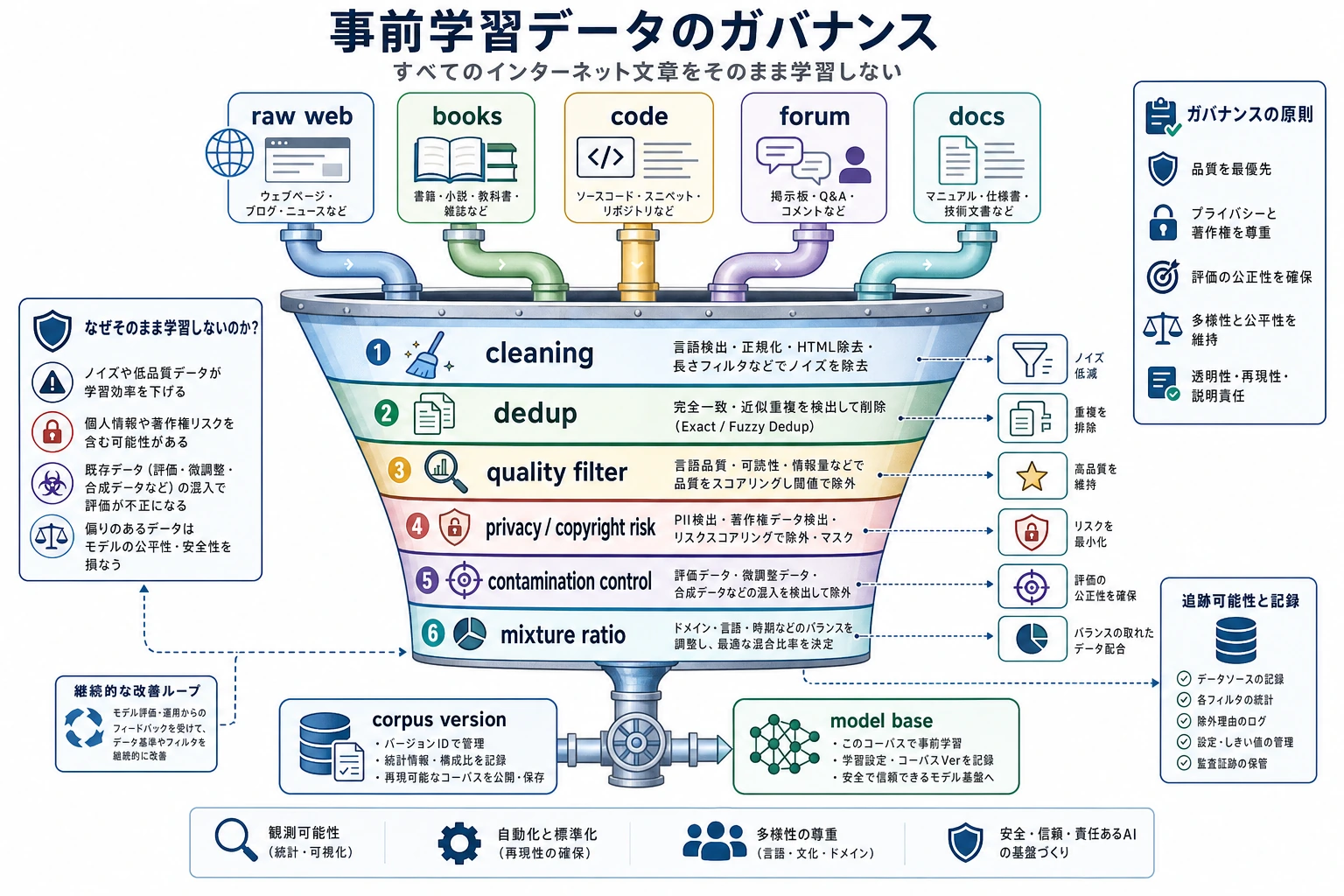
なぜ「インターネットは巨大」でも「そのまま学習に使える」とは限らないのか?
実際のテキストには、次のような問題が混ざっているからです。
- 重複コンテンツ
- 低品質な転載
- 広告やスパムページ
- テンプレート化された SEO テキスト
- 違法またはセンシティブな内容
- 評価データの汚染
大規模モデルで本当に難しいのは、データが見つからないことではありません。
むしろ次の点です。
大量の生テキストを、高品質で、制御可能で、再利用可能なデータ基盤に整えるにはどうすればよいか。
事前学習データを初めて学ぶとき、まず何をつかむべきか?
最初に押さえるべきなのは、具体的なコーパス名ではなく、次の一文です。
モデルの事前学習段階は「何を学ぶ価値があるか」を自動では見分けない。だからデータガバナンスは、モデルに代わって最初の価値選別をしている。
この考えがしっかりすると、あとで出てくる
- 重複排除
- フィルタリング
- 配分
- 汚染対策
は、単なる実装の細部ではなく、すべてモデルの土台に関わるものだと分かります。
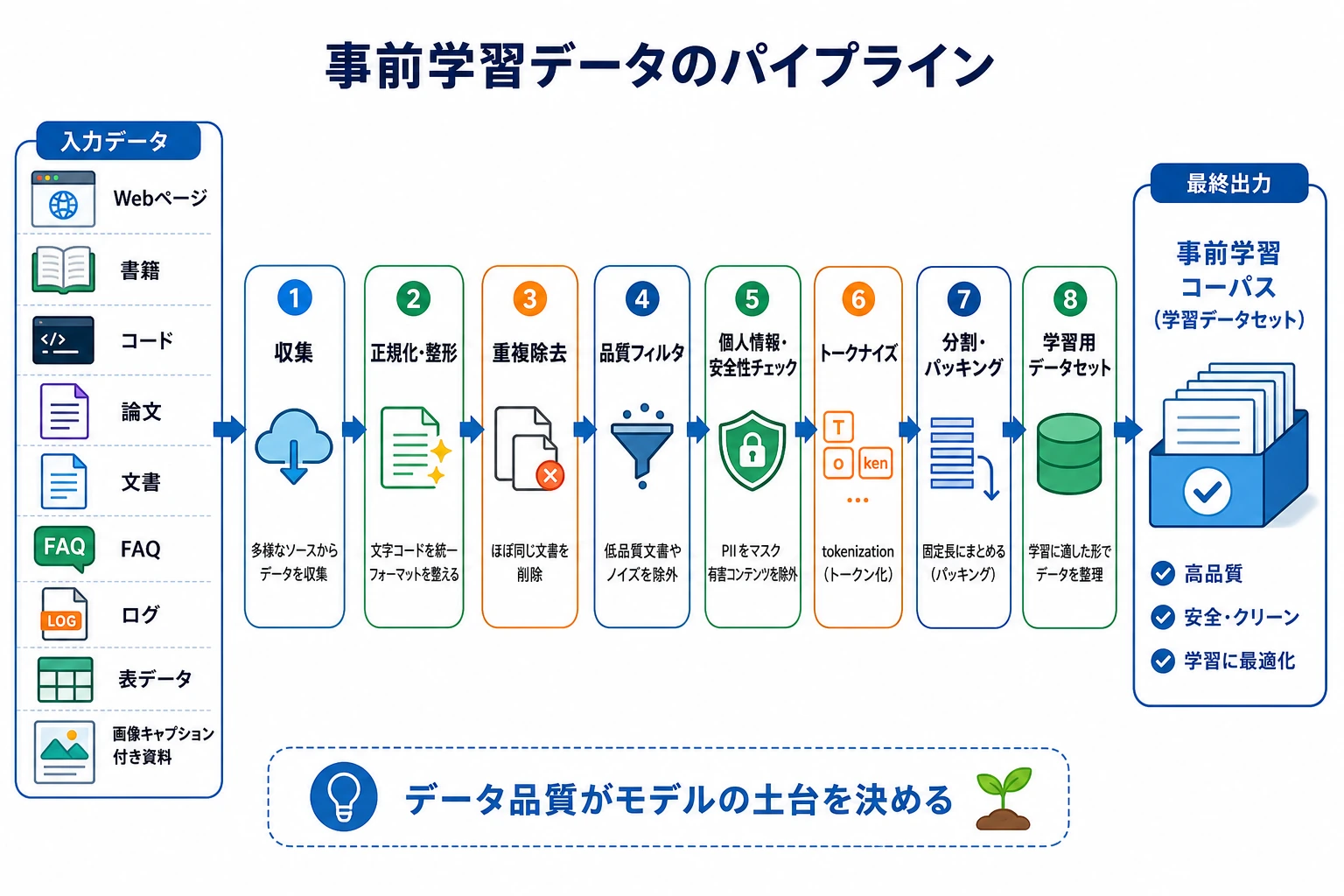
まずは事前学習データのパイプラインを図で見る
このパイプラインは、「データが大事」という話を具体化してくれます。どの段階も、モデルが最終的に何を学べるか、何に偏るか、どんなミスをしやすいかを変えます。
この図は「生データがたくさんある」状態から、「学習可能なコーパスはずっと少ない」状態へと読んでください。クリーニング、重複排除、リスクフィルタリング、汚染対策、配分は飾りではなく、モデルに対して「どのパターンを学ぶ価値があるか」「どのノイズを訓練前に止めるべきか」を決める工程です。
二、事前学習データでは、どんな観点を見るべきか?
カバレッジ:モデルがどれだけ多様な言語や知識に触れられるか
よくあるデータソースには、次のようなものがあります。
- Web
- 書籍
- コード
- 学術論文
- Q&A フォーラム
- 対話コーパス
カバレッジが不足すると、特定の場面でモデルが弱くなります。
たとえば、
- コード比率が低すぎると、コード能力が弱くなる
- 長文の書き言葉が少なすぎると、長い文章を組み立てる力が落ちる
品質:すべての token が同じ価値を持つわけではない
実用的な経験則として、次のように考えられます。
- 高品質な token の価値は、低品質 token を大量に積み上げるよりずっと高いことが多い
コーパスに次のようなものが大量にあると、
- 同じ言い回しの繰り返し
- 機械的なつぎはぎ
- マーケティング広告
- 誤字脱字や文法の乱れ
モデルは、そうした学ぶ価値の低いパターンに計算資源を使ってしまいます。
多様性:1種類の話し方だけではだめ
データが同じ種類のソースばかりだと、
モデルはかなり偏って学ぶ可能性があります。
たとえばフォーラムの口語ばかりだと、
- スタイルが安定しない
- かしこまった文章が弱い
一方で、百科事典のような書き言葉ばかりだと、
- 対話らしさが弱い
- 指示に自然に従う感じが出にくい
安全性とコンプライアンス:「見てから考える」では遅い内容もある
データガバナンスでは、次の点も考えなければなりません。
- 著作権リスク
- 個人情報
- センシティブまたは有害な内容
- コンプライアンスの境界
これは、あとで安全性の微調整を1回入れれば完全に補えるものではありません。
データガバナンスを初めて見るなら、まず何を覚えるべきか?
まずはこの4つを押さえましょう。
- カバレッジ
- 品質
- 多様性
- リスク
この4つは、以降のデータに関する議論の最小の骨組みです。
三、まずは本当に役立つデータクリーニングの例を動かしてみる
以下のコードは、とても小さな事前学習データパイプラインを模擬しています。
- テキストの正規化
- 重複排除
- 低品質フィルタリング
- ソースごとの残存比率の集計
from collections import Counter
raw_docs = [
{"source": "web", "text": "クリックしてクーポンを受け取る!!!クリックしてクーポンを受け取る!!!"},
{"source": "web", "text": "Python is a programming language. Python is widely used."},
{"source": "book", "text": "The transformer architecture uses self-attention to model token interactions."},
{"source": "web", "text": "python is a programming language. python is widely used."},
{"source": "forum", "text": "パスワードを忘れました。サポートに聞いたらSMSでリセットできるそうです。"},
{"source": "forum", "text": "はははははは"},
]
def normalize(text):
return " ".join(text.lower().replace("!", "!").split())
def repeated_char_ratio(text):
if len(text) < 2:
return 0.0
repeats = sum(text[i] == text[i - 1] for i in range(1, len(text)))
return repeats / (len(text) - 1)
def quality_ok(text):
if len(text.split()) < 4 and len(text) < 12:
return False
if "クーポン" in text or "クリックして" in text:
return False
if repeated_char_ratio(text) > 0.6:
return False
return True
seen = set()
clean_docs = []
for doc in raw_docs:
normalized = normalize(doc["text"])
if normalized in seen:
continue
if not quality_ok(normalized):
continue
seen.add(normalized)
clean_docs.append({"source": doc["source"], "text": normalized})
print("kept docs:")
for doc in clean_docs:
print(doc)
print("\nsource mix:", Counter(doc["source"] for doc in clean_docs))
期待される出力:
kept docs:
{'source': 'web', 'text': 'python is a programming language. python is widely used.'}
{'source': 'book', 'text': 'the transformer architecture uses self-attention to model token interactions.'}
{'source': 'forum', 'text': 'パスワードを忘れました。サポートに聞いたらsmsでリセットできるそうです。'}
source mix: Counter({'web': 1, 'book': 1, 'forum': 1})
このコードは、実際の現場ではどの工程に対応するのか?
とても小さいですが、事前学習パイプラインでよくある次の処理に対応しています。
- テキスト正規化
- exact dedup
- 低品質サンプルの除外
- データソース分布の集計
これは、あってもなくてもよい前処理ではなく、
大規模モデルのデータエンジニアリングの基本です。
なぜ重複排除が特に重要なのか?
重複テキストがあると、モデルは同じ内容を何度も見ることになります。
これには次の2つの問題があります。
- 学習 token の無駄遣い
- 一部のパターンの過度な強調
特に Web データでは、
転載、ミラーサイト、テンプレートページがとても多く見られます。
なぜ「はははははは」のようなサンプルを除外するのか?
こうしたテキストは実在する言語ではありますが、
汎用能力の向上にはほとんど役立たず、
分布を偏らせる可能性もあります。
つまり、事前学習データは生のままで多ければよいわけではなく、
「学習価値」を見て判断する必要があります。
なぜこの小さな例を何度も見る価値があるのか?
この例を見ると、次のことが分かります。
- データエンジニアリングは抽象的な理念から始まるのではない
- とても具体的な判断の積み重ねから始まる
たとえば、
- これは重複か
- これはノイズか
- このソース比率は偏りすぎていないか
こうした判断が積み重なって、最終的にモデル能力の差になります。
四、データ配分はなぜモデルのスタイルに直接影響するのか?
ソースごとの token は、それぞれ違う能力を育てる
ざっくりですが、実用的な理解としては次の通りです。
- Web: 範囲は広いが、品質のばらつきが大きい
- 書籍: 構成がしっかりしていて、言語が安定しやすい
- コード: プログラムのパターンと形式言語能力を強める
- フォーラム対話: 口語的なやりとりや対話感を強める
そのため、最終的なデータ混合比率は、モデルを次のように変えます。
- より百科事典らしくなる
- よりアシスタントらしくなる
- よりプログラマらしくなる
配分が不適切だと、何が起こるか?
たとえば、
- コード比率が低すぎると、コードを書く力が弱くなる
- フォーラム比率が高すぎると、かしこまった文章が口語っぽくなる
- 低品質な Web ページが多いと、回答が空疎でテンプレート的になる
だから、学習前にはしばしば次のような設計を行います。
- source mix の設計
簡単な配分サンプリングの例
import random
from pprint import pprint
random.seed(42)
datasets = {
"web": ["web_1", "web_2", "web_3"],
"book": ["book_1", "book_2"],
"code": ["code_1", "code_2"],
}
mix = {"web": 0.5, "book": 0.2, "code": 0.3}
def sample_source(mix_config):
r = random.random()
cumulative = 0.0
for source, prob in mix_config.items():
cumulative += prob
if r <= cumulative:
return source
return source
draws = []
for _ in range(20):
source = sample_source(mix)
item = random.choice(datasets[source])
draws.append((source, item))
pprint(draws)
期待される出力:
[('book', 'book_1'),
('code', 'code_1'),
('web', 'web_3'),
('web', 'web_3'),
('code', 'code_1'),
('book', 'book_1'),
('web', 'web_1'),
('web', 'web_3'),
('web', 'web_1'),
('code', 'code_2'),
('web', 'web_3'),
('web', 'web_1'),
('code', 'code_1'),
('book', 'book_2'),
('web', 'web_1'),
('code', 'code_2'),
('web', 'web_2'),
('web', 'web_2'),
('book', 'book_1'),
('code', 'code_1')]
このコードが伝えているのは、次のことです。
- データ混合は「全部入れれば終わり」ではない
- サンプリング戦略自体が学習設計の一部である
五、汚染と評価リークはなぜ危険なのか?
データ汚染とは何か?
よくあるのは次のようなケースです。
- 評価問題、正解、またはその近い変種が学習データに混ざってしまう
こうなると、評価時にモデルが強く見えても、
それは汎化ではなく、元の問題を見たことがあるだけかもしれません。
なぜこれは普通の重複より深刻なのか?
モデル能力の判断を直接ゆがめるからです。
つまり、次のように誤解してしまいます。
- 推論能力が上がった
- 知識が豊富になった
でも実際には、
- 学習データにテストサンプルが漏れていただけ
かもしれません。
実際にはどうやってリスクを下げるのか?
よくある方法は次の通りです。
- ハッシュや n-gram に基づく近重複検出
- 公開 benchmark の明示的なフィルタリング
- データソースとバージョンの厳密な記録
だからこそ、データガバナンスにはバージョン管理の意識が必要です。
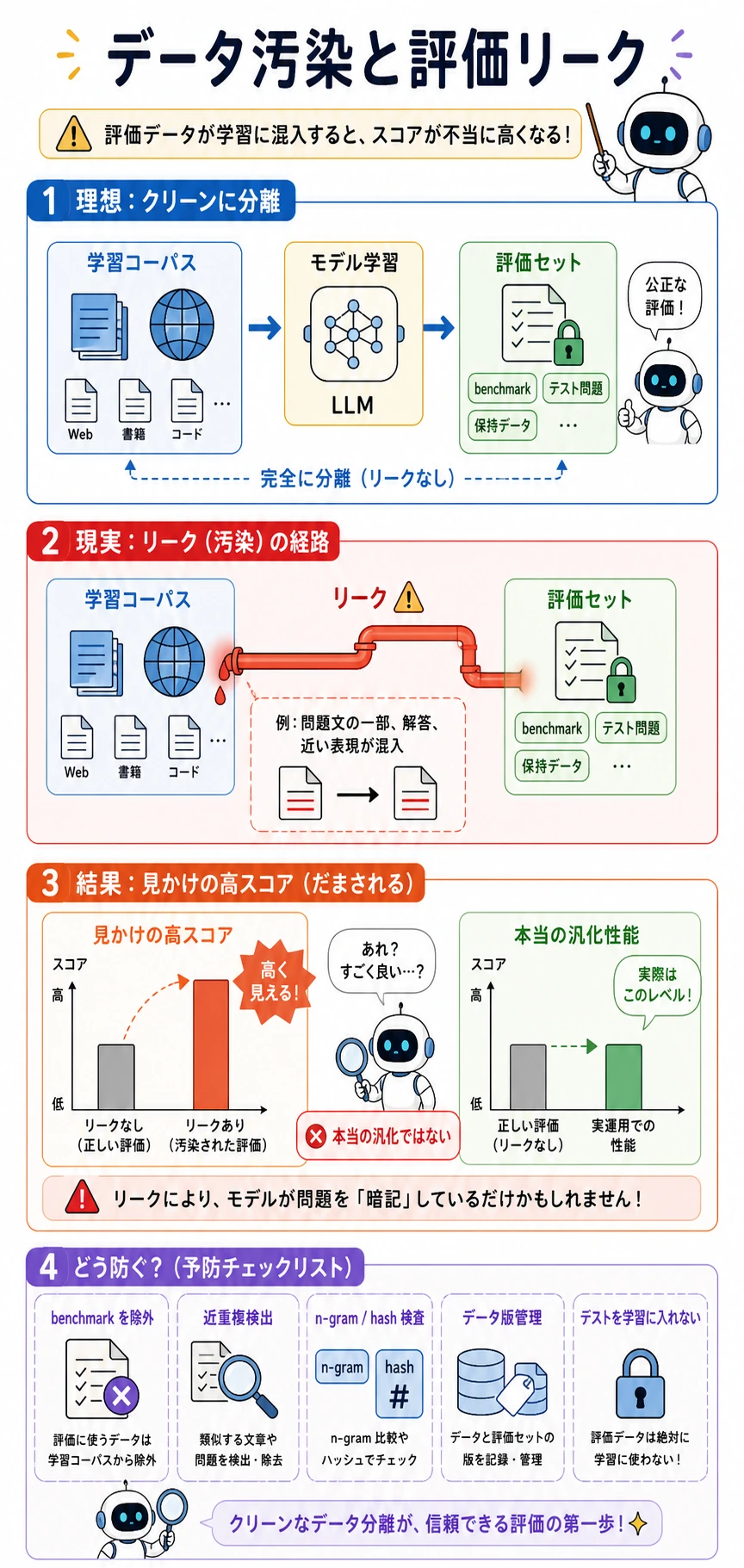
学習コーパスと評価セットは、必ずきれいに分離します。benchmark の問題、解答、または近い変種が学習に漏れると、モデルは答え方のパターンを見たことがあるだけで高得点に見える場合があります。それは本当の汎化ではありません。
区別しておきたい用語
| 用語 | 意味 | 事前学習で重要な理由 |
|---|---|---|
| データ汚染 | テストデータ、解答、近重複サンプルが誤って学習コーパスに入ること | モデルが転移できる能力ではなく、benchmark のパターンを暗記してしまう可能性がある |
| 評価リーク | 評価セットの情報が学習やプロンプト設計に影響すること | スコアが本当の未知データ性能を表さなくなる |
| Benchmark | モデル比較に使う標準的なテストセット | 公開 benchmark は便利だが、Web 規模のコーパスに混ざりやすい |
| n-gram / hash 検査 | テキスト断片や指紋を使って重なりを比較する方法 | 完全重複や、かなり似ている疑わしいサンプルを見つけやすい |
| バージョン管理 | 各コーパス版を作ったデータソース、フィルタ、ルールを記録すること | 記録がないと、スコア変化の理由説明や訓練の再現が難しくなる |
六、事前学習データ品質のセルフチェック表
事前学習コーパスを見るときは、まず次の表で素早く判断できます。
| チェック項目 | 何を確認するか | 不十分だとどうなるか |
|---|---|---|
| カバレッジ | 必要な言語、分野、形式をカバーしているか | 一部の場面でモデルが弱くなる |
| 品質 | 大量の広告、文字化け、テンプレートページが混ざっていないか | 低価値なパターンを学ぶ |
| 重複排除 | 転載、ミラー、重複テンプレートが大量にないか | token を浪費し、重複パターンを強める |
| 配分 | Web、書籍、コード、対話の比率が目標に合っているか | スタイルと能力の偏りが起こる |
| 汚染 | 評価データや正解が学習に混ざっていないか | 評価が過大になり、汎化能力を誤判定する |
| バージョン | データソースと処理ルールを追跡できるか | 再現実験や問題調査が難しくなる |
この表は、プロジェクトノートに入れておくと便利です。
「データが多いほどいい」と考えるだけではなく、学習に向いているデータかどうかをエンジニアリングの観点で判断できるようになるからです。
七、事前学習データで最も陥りやすい落とし穴
誤解1:データは多いほどいい
低品質の比率が高いなら、
単に量を増やしても、計算資源を無駄にしているだけかもしれません。
誤解2:クリーニングは厳しければ厳しいほど安全
過度なクリーニングにも代償があります。
- 多様性の低下
- 希少知識の誤削除
- 言語スタイルの狭まり
つまり、クリーニングは厳しければよいのではなく、
目標とする能力に合わせる必要があります。
誤解3:後で微調整するから、事前学習データはあまり気にしなくてよい
違います。
微調整は、すでにある土台の上で方向を整える作業に近く、
土台そのものを最初から作り直すものではありません。
まとめ
この節で最も重要なのは、いくつかのデータソース名を覚えることではなく、次の判断を身につけることです。
事前学習データは、モデルにどんな世界を見せるかを決める。そして、高品質な事前学習パイプラインの核心は、単にテキストをもっと集めることではなく、クリーニング、重複排除、配分、汚染対策を行うことにある。
この視点ができると、
今後、事前学習の目的、学習エンジニアリング、微調整データを見るときにも、何を「源流」で解決すべきかが分かるようになります。
八、演習
- この節のコードを参考に、除外すべきだと思うサンプルや、残すべきだと思うサンプルをいくつか追加し、ルールが妥当か確認してください。
- なぜ「exact dedup」は第一歩にすぎず、実際のプロジェクトでは近重複検出も必要なのか、説明してください。
- 自分の言葉で考えてみましょう。モデルが主にコード用途なら、データ配分はどう調整すべきでしょうか。
- なぜ評価リークがモデル能力を過大評価させるのか、自分の言葉で説明してください。