7.3.3 原始 Transformer vs 现代 LLM Decoder
2017 年 Transformer 论文给了我们基础架构,但大多数现代 LLM decoder block 并不是原始图的逐行复刻。
核心思想仍然一样:
用 attention 做 token 之间的信息交流,用 FFN 做逐 token 变换,用 residual path 保留信息。
但为了更深的模型、更长的上下文、更快的推理和更稳定的训练,很多细节已经演化了。
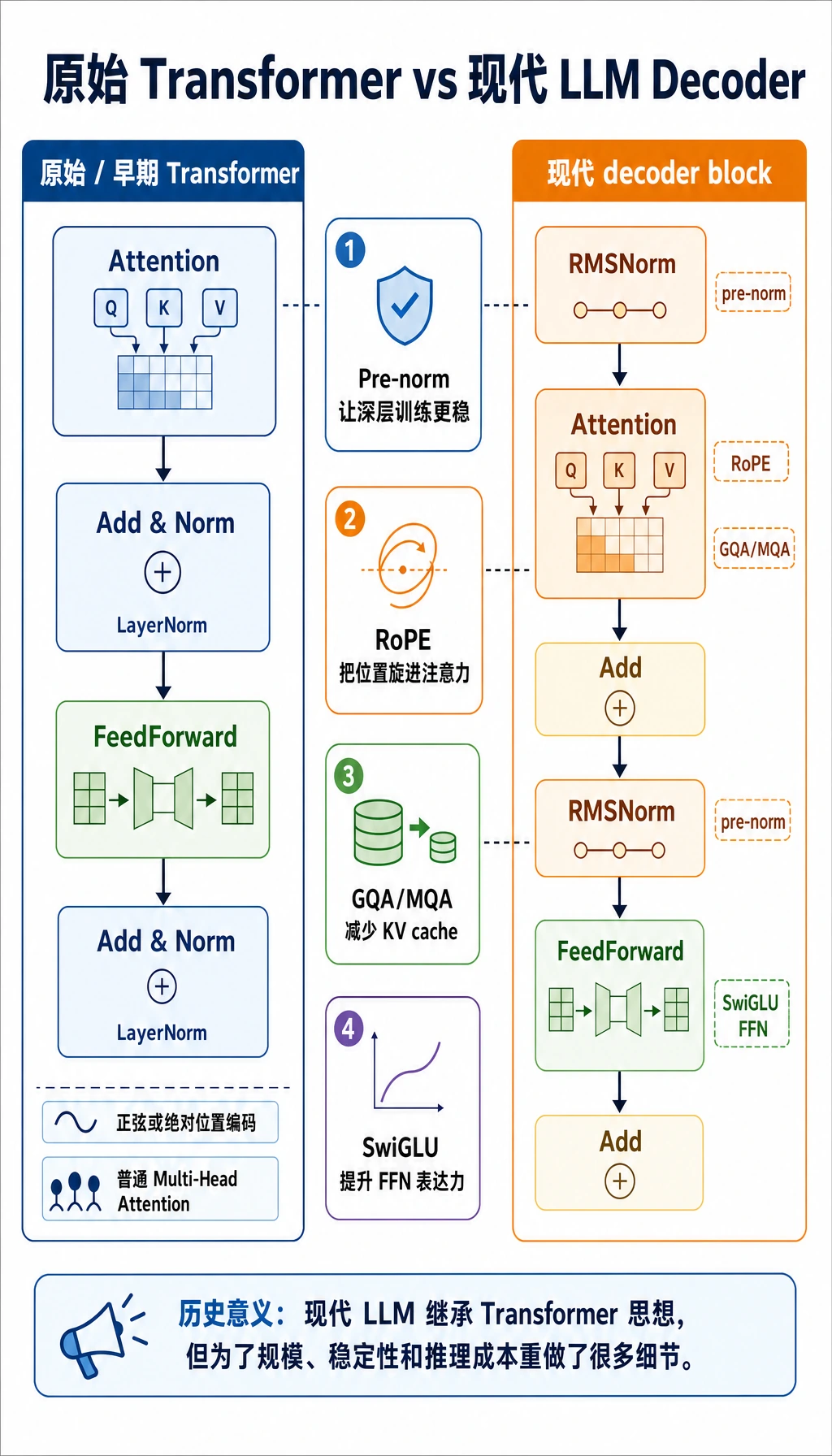
不要先背名词。先把左右两条流程当成故事读:原始 block 让 Transformer 成立,现代 decoder block 保留思想,但为了 LLM 规模改了 normalization、位置编码、K/V 共享和 FFN 设计。
早期 Transformer block
一个简化的早期 Transformer block 常被描述成:
Attention -> Add & Norm -> FeedForward -> Add & Norm
常见细节包括:
- residual add 后做 LayerNorm
- 正弦或绝对位置编码
- 普通 Multi-Head Attention
- 很多早期描述里使用 ReLU 风格的 feed-forward network
这个结构依然很适合入门,因为它能清楚解释主线。
但当模型变得更深、上下文更长、服务长对话时,几个问题会更明显:
- 深层训练可能不稳定
- 绝对位置对长上下文扩展不够灵活
- 推理时 KV cache 成本很高
- FFN 在大规模训练下需要更强表达力
常见现代 LLM decoder block
一个简化的现代 decoder block 通常更像:
RMSNorm -> Attention -> Add -> RMSNorm -> FeedForward -> Add
常见细节包括:
- pre-norm,而不是 post-norm
- RMSNorm,而不是完整 LayerNorm
- 用 RoPE 表示位置
- 用 GQA 或 MQA 缓解 KV cache 压力
- 使用 SwiGLU 风格 FFN
这不代表所有现代模型完全一样。 不同模型会选择不同细节。 但这个模式足够常见,读模型代码时应该能认出来。
Pre-norm:先归一化,再进入子层
在 post-norm block 里,归一化常出现在:
x + sublayer(x)
之后。
在 pre-norm block 里,子层先接收归一化后的输入:
x + sublayer(norm(x))
为什么重要?
Pre-norm 往往让非常深的 Transformer 更容易训练,因为 residual path 更干净。你可以把它理解成:让信息高速公路在很多层里保持稳定。
真实代码里,你经常会看到:
x = x + attention(norm1(x))
x = x + ffn(norm2(x))
RMSNorm:更轻的归一化
LayerNorm 使用均值和方差做归一化。 RMSNorm 使用 root mean square,也就是均方根幅度,去掉了减均值这一步。
新人可以这样理解:
- LayerNorm 问:“每个值离平均值有多远?”
- RMSNorm 问:“这个向量整体有多大?”
RMSNorm 流行,是因为它更简单、更高效,同时仍然能很好稳定大模型。
一开始不需要推公式,先记住作用:
RMSNorm 用更轻的归一化步骤,让 activation 数值更稳定。
RoPE:把位置旋进 attention
早期 Transformer 示例常把位置向量加到 token embedding 上。 现代 LLM 经常使用:
- RoPE:Rotary Position Embedding,旋转位置编码
直觉是:
不是只在输入处加一次位置向量,而是根据位置旋转 Q 和 K,让相对位置信息进入 attention 分数。
为什么有用?
- 它自然发生在 attention 内部。
- 它提供较好的相对位置信号。
- 相比简单绝对位置 embedding,扩展和适配通常更灵活。
读模型代码时,RoPE 通常出现在 attention 计算附近,在 QK^T 之前。
GQA / MQA:减少 KV cache 压力
推理时,decoder-only 模型会缓存历史 token 的 K 和 V。
这叫:
- KV cache
普通 Multi-Head Attention 可能为很多 head 存 K/V。 现代服务需要减少这部分显存压力。
两种常见选择是:
| 术语 | 含义 | 主要节省什么 |
|---|---|---|
| MQA | Multi-Query Attention:很多 query heads 共享一组 K/V | 最大化 K/V 共享 |
| GQA | Grouped-Query Attention:query heads 分组共享 K/V | 在质量和 cache 大小之间折中 |
实用直觉:
GQA/MQA 主要不是让模型“更聪明”,而是让长上下文推理更便宜。
SwiGLU FFN:更强的前馈层
原始 Transformer FFN 常被讲成:
Linear -> activation -> Linear
很多现代 LLM 使用门控 FFN,例如:
- SwiGLU
直觉是:
- 一条路径产生候选特征
- 另一条路径像门一样控制
- 这个门决定哪些特征更应该通过
可以这样记:
SwiGLU 让 FFN 不只是生成特征,还能控制哪些特征更重要。
跑一个很小的 decoder block 检查
这段脚本不是实现完整 LLM。 它的目标更窄:把几个架构名词和可观察的行为连起来。
from math import sqrt
activation = [2.0, -1.0, 0.5, 3.0]
def layer_norm(xs, eps=1e-6):
mean = sum(xs) / len(xs)
variance = sum((x - mean) ** 2 for x in xs) / len(xs)
return [(x - mean) / sqrt(variance + eps) for x in xs]
def rms_norm(xs, eps=1e-6):
rms = sqrt(sum(x * x for x in xs) / len(xs) + eps)
return [x / rms for x in xs]
decoder_config = {
"norm": "RMSNorm",
"position": "RoPE",
"query_heads": 32,
"kv_heads": 8,
"ffn": "SwiGLU",
}
print("LayerNorm:", [round(x, 3) for x in layer_norm(activation)])
print("RMSNorm :", [round(x, 3) for x in rms_norm(activation)])
print("position :", decoder_config["position"])
print("kv share :", decoder_config["query_heads"] // decoder_config["kv_heads"], "query heads per KV group")
print("ffn style:", decoder_config["ffn"])
预期输出:
LayerNorm: [0.577, -1.402, -0.412, 1.237]
RMSNorm : [1.06, -0.53, 0.265, 1.589]
position : RoPE
kv share : 4 query heads per KV group
ffn style: SwiGLU
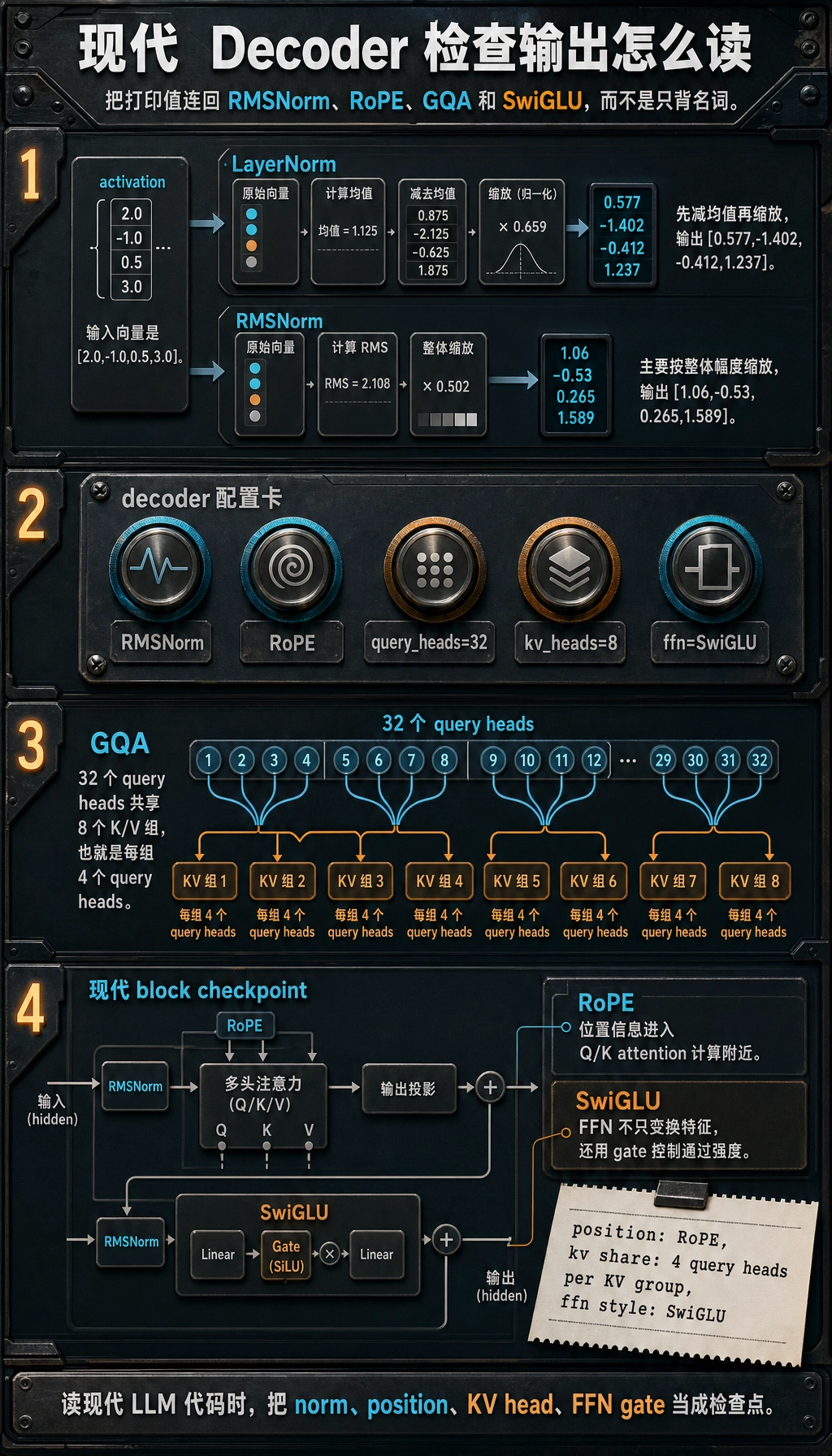
怎么读这个输出?
LayerNorm会围绕均值重新居中;RMSNorm更像是在缩放整体幅度。kv share说明这是 GQA:每 4 个 query heads 共享一组 K/V。RoPE和SwiGLU不是装饰词。它们分别说明位置信息在哪里进入、FFN 如何用门控控制特征。
一张紧凑对比表
| 部分 | 早期 Transformer 直觉 | 现代 LLM decoder 直觉 |
|---|---|---|
| 归一化顺序 | 子层后 Add & Norm | Attention / FFN 前 pre-norm |
| Norm 类型 | LayerNorm | 常见 RMSNorm |
| 位置 | 正弦或绝对位置 | 常见 RoPE |
| Attention heads | 普通 MHA | 常见 GQA 或 MQA,服务推理更省 |
| FFN | 基础 MLP / ReLU 风格 | 常见 SwiGLU 门控 FFN |
| 主要压力 | 让 attention 序列建模跑起来 | 让深度、上下文和推理成本可承受 |
这对读模型代码有什么帮助
打开现代模型代码时,不要只找 Transformer 这个词。
更应该找真实组件:
rms_normrotary_embq_proj、k_proj、v_projnum_key_value_headsgate_proj、up_proj、down_proj
这些名字就是概念图和真实 LLM 实现之间的桥。
总结
现代 LLM decoder block 不是在否定原始 Transformer。
它是在同一思想上适配更难的约束:
- 更深训练
- 更长上下文
- 更低延迟
- 更小 KV cache
- 更强 FFN 表达
理解这些变化后,现代 LLM 架构图和源码都会少很多神秘感。