7.8.1 项目路线图:选择 Prompt、RAG 还是微调
这个综合项目把第 7 章压缩成一个工程判断:问题到底是任务表达不清、知识缺失、格式不稳定、安全边界不清,还是评估太弱?
先看项目路线
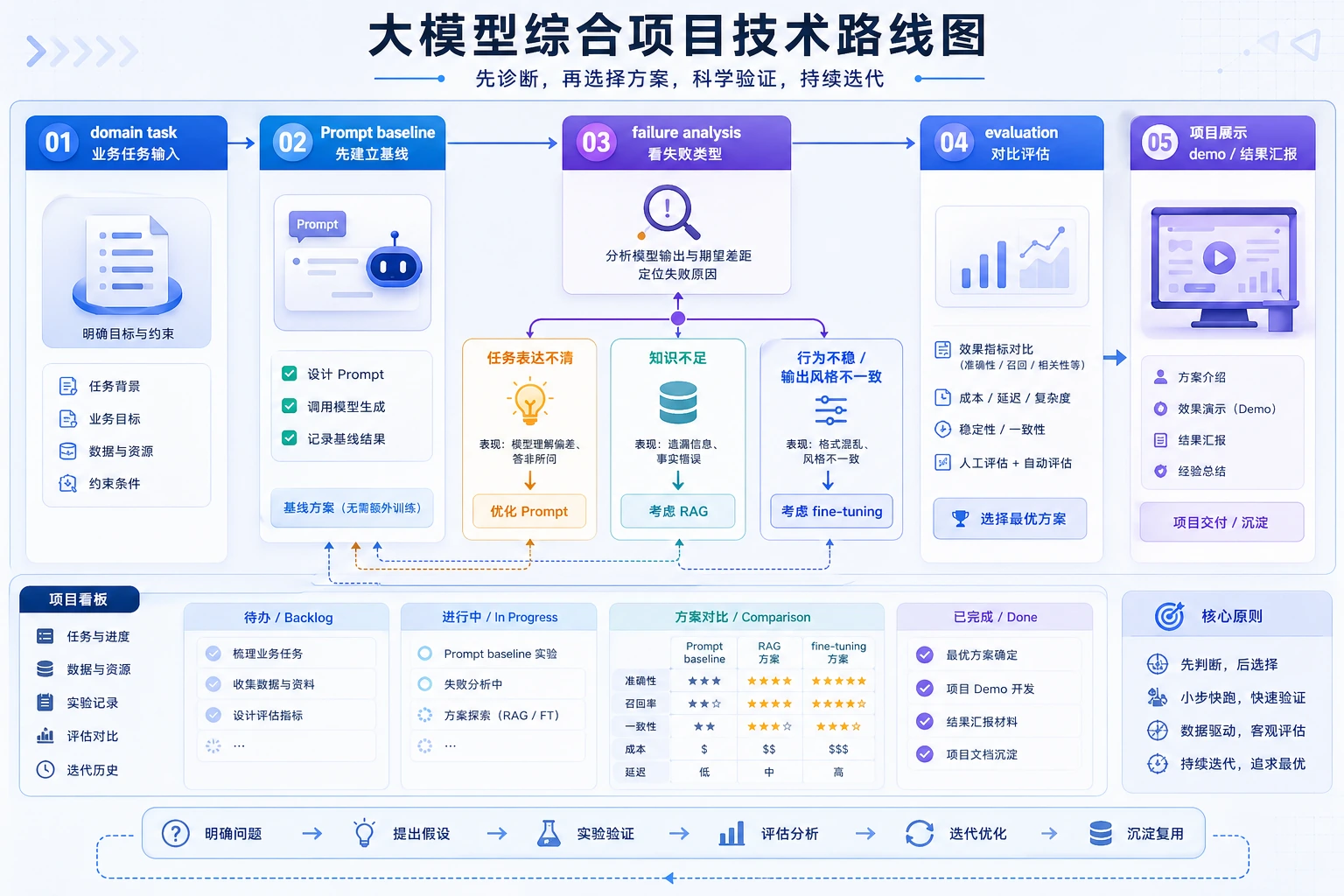
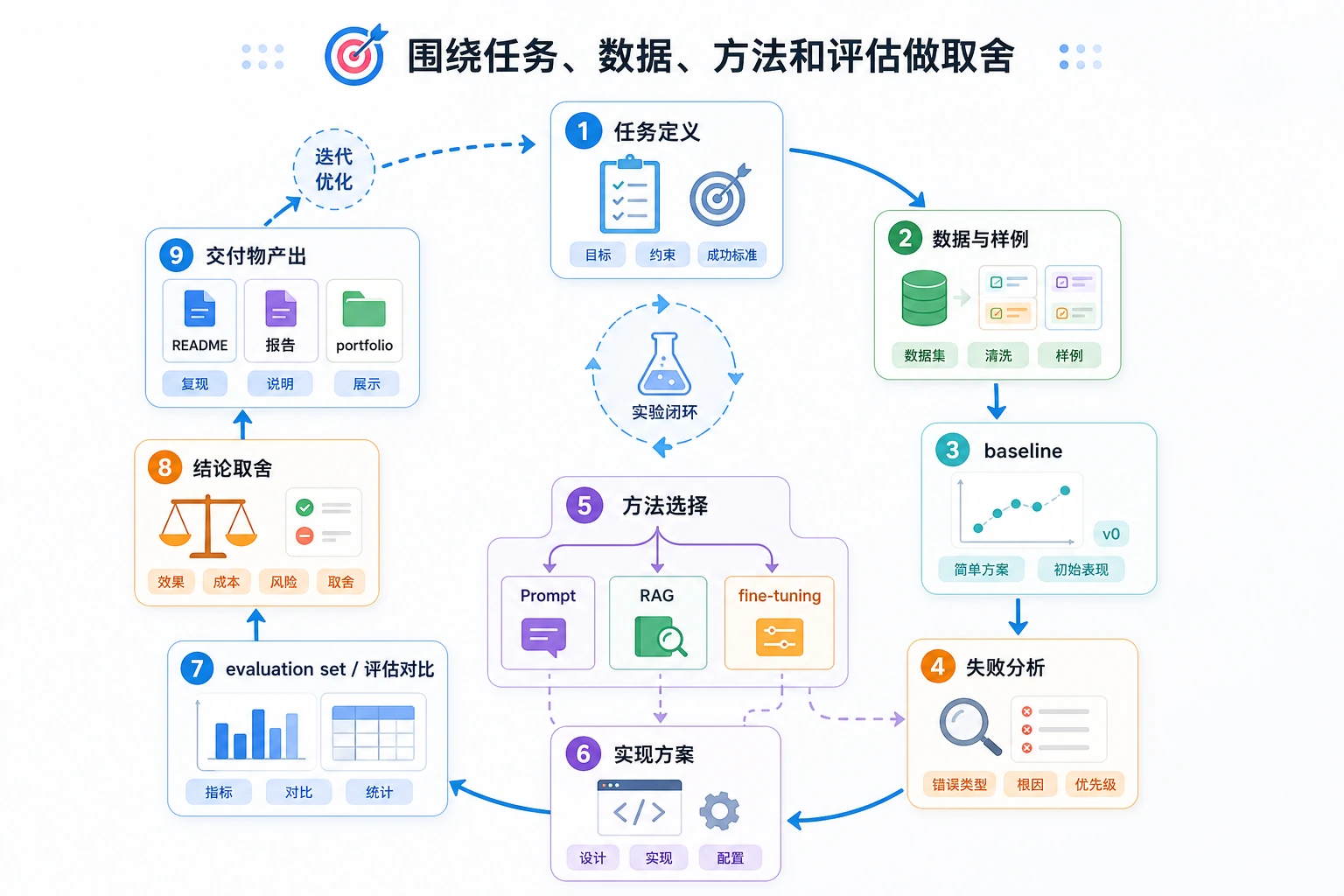

不要从最强模型或最复杂框架开始。先从一个小领域任务、Prompt 基线、固定样例和失败记录开始。
跑一个证据包检查
写报告前先用这个小项目日志。它会强制你展示基线、改进幅度、下一条路线,以及现在是否真的需要微调。
project = {
"task": "classify course questions",
"baseline_pass_rate": 0.62,
"prompt_v2_pass_rate": 0.78,
"rag_needed": True,
"finetune_needed": False,
}
improvement = project["prompt_v2_pass_rate"] - project["baseline_pass_rate"]
print("task:", project["task"])
print("improvement:", round(improvement, 2))
print("next_route:", "RAG" if project["rag_needed"] else "Prompt")
print("fine_tune_now:", project["finetune_needed"])
预期输出:
task: classify course questions
improvement: 0.16
next_route: RAG
fine_tune_now: False
如果你的项目填不出这些字段,就继续缩小范围。清晰的对比,比庞大但无法测试的演示更有价值。
按这个顺序学
| 步骤 | 操作 | 证据 |
|---|---|---|
| 1 | 选择一个领域任务 | 一句话任务定义和 10 个固定样例 |
| 2 | 建立 Prompt 基线 | Prompt 版本、输出、通过/失败记录 |
| 3 | 分类失败类型 | 任务表达、知识缺失、格式漂移、安全边界 |
| 4 | 选择下一种方法 | Prompt 迭代、RAG 或微调决策说明 |
| 5 | 打包结果 | README、运行命令、截图、失败案例、下一步 |
如果想先跟着做,可以先运行 7.8.4 实操:完整第 7 章工作坊,再设计自己的领域项目。
项目交付物标准
| 交付物 | 最低标准 | 更强的作品集版本 |
|---|---|---|
| README | 目标、运行命令、模型或 API 选择、输入/输出样例 | 增加方案取舍、成本说明、评估和复盘 |
| 样例 | 至少 10 个固定案例 | 对比 Prompt、RAG、微调或规则方案 |
| 评估 | 明确通过/失败规则 | 增加评分、失败类型统计和回归记录 |
| Prompt/数据记录 | 保存 Prompt 版本或样本格式 | 增加 schema 校验、数据质量检查和安全说明 |
| 展示材料 | 截图或短 GIF 证明能运行 | 说明为什么当前路线优于其他选择 |
通过标准
如果你能用固定评估集清楚解释“这里为什么不微调”“这里为什么需要 RAG”或“这个 Prompt 修改为什么有效”,而不是只展示一个好回答,就通过了本章。
最终项目可以很基础:在一个领域任务上比较两个 Prompt 版本。更强版本可以加入 RAG 或小型微调实验,但必须在基线和失败记录证明需要之后再做。